Interested Article - Хеш-таблица

- 2020-09-15
- 1
Хеш-табли́ца — это структура данных , реализующая интерфейс ассоциативного массива , а именно, она позволяет хранить пары (ключ, значение) и выполнять три операции: операцию добавления новой пары, операцию удаления и операцию поиска пары по ключу.
Введение
Существуют два основных варианта хеш-таблиц: с открытой адресацией и списками. Хеш-таблица является массивом , элементы которого есть пары (хеш-таблица с открытой адресацией) или списки пар (хеш-таблица со списками).
 , элементы которого есть пары (хеш-таблица с открытой адресацией) или списки пар (хеш-таблица со списками).
, элементы которого есть пары (хеш-таблица с открытой адресацией) или списки пар (хеш-таблица со списками).
Выполнение операции в хеш-таблице начинается с вычисления хеш-функции от ключа. Получающееся хеш-значение играет роль индекса в массиве . Затем выполняемая операция (добавление, удаление или поиск) перенаправляется объекту, который хранится в соответствующей ячейке массива .
 играет роль индекса в массиве
играет роль индекса в массиве
 . Затем выполняемая операция (добавление, удаление или поиск) перенаправляется объекту, который хранится в соответствующей ячейке массива
. Затем выполняемая операция (добавление, удаление или поиск) перенаправляется объекту, который хранится в соответствующей ячейке массива
![H[i]](/images/000/064/64724/6.jpg?rand=475647) .
.
Ситуация, когда для различных ключей получается одно и то же хеш-значение, называется коллизией . Такие события не так уж и редки — например, при вставке в хеш-таблицу размером 365 ячеек всего лишь 23 элементов вероятность коллизии уже превысит 50% (если каждый элемент может равновероятно попасть в любую ячейку) — см. парадокс дней рождения . Поэтому механизм разрешения коллизий — важная составляющая любой хеш-таблицы.
В некоторых специальных случаях удаётся избежать коллизий вообще. Например, если все ключи элементов известны заранее (или очень редко меняются), то для них можно найти некоторую совершенную хеш-функцию , которая распределит их по ячейкам хеш-таблицы без коллизий. Хеш-таблицы, использующие подобные хеш-функции, не нуждаются в механизме разрешения коллизий, и называются хеш-таблицами с прямой адресацией .
Число хранимых элементов, делённое на размер массива (число возможных значений хеш-функции), называется коэффициентом заполнения хеш-таблицы (load factor) и является важным параметром, от которого зависит среднее время выполнения операций.
 (число возможных значений хеш-функции), называется
коэффициентом заполнения хеш-таблицы
(load factor) и является важным параметром, от которого зависит среднее время выполнения операций.
(число возможных значений хеш-функции), называется
коэффициентом заполнения хеш-таблицы
(load factor) и является важным параметром, от которого зависит среднее время выполнения операций.
Свойства хеш-таблицы
Важное свойство хеш-таблиц состоит в том, что, при некоторых разумных допущениях, все три операции (добавление, удаление, поиск элемента) в среднем выполняются за время . Но при этом не гарантируется, что время выполнения отдельной операции мало́. Это связано с тем, что при достижении некоторого значения коэффициента заполнения необходимо осуществлять перестройку индекса хеш-таблицы: создать новый массив увеличенного размера и заново добавить в него все пары из старого массива пар (он же старая хеш-таблица).
 . Но при этом не гарантируется, что время выполнения отдельной операции мало́. Это связано с тем, что при достижении некоторого значения коэффициента заполнения необходимо осуществлять перестройку индекса хеш-таблицы: создать новый массив
. Но при этом не гарантируется, что время выполнения отдельной операции мало́. Это связано с тем, что при достижении некоторого значения коэффициента заполнения необходимо осуществлять перестройку индекса хеш-таблицы: создать новый массив
 увеличенного размера и заново добавить в него все пары из старого массива пар (он же старая хеш-таблица).
увеличенного размера и заново добавить в него все пары из старого массива пар (он же старая хеш-таблица).
Разрешение коллизий
Существует несколько способов разрешения коллизий .
Метод списков

Каждая ячейка массива H является указателем на связный список пар ключ-значение, соответствующих одному и тому же хеш-значению ключа. Коллизии просто приводят к тому, что появляются списки длиной более одного элемента.
Операции поиска или удаления элемента требуют просмотра всех элементов соответствующего ему списка, чтобы найти в нём элемент с заданным ключом. Для добавления элемента нужно добавить элемент в конец или начало соответствующего списка и в случае, если коэффициент заполнения станет слишком велик, увеличить размер массива H и перестроить таблицу.
При предположении, что каждый элемент может попасть в любую позицию таблицы H с равной вероятностью и независимо от того, куда попал любой другой элемент, среднее время работы операции поиска элемента составляет Θ (1 + α ), где α — коэффициент заполнения таблицы.
Открытая адресация
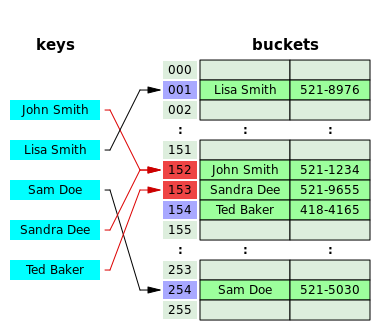
В массиве H хранятся сами пары ключ-значение. Алгоритм вставки элемента проверяет ячейки массива H в некотором порядке до тех пор, пока не будет найдена первая свободная ячейка, в которую и будет записан новый элемент. Этот порядок вычисляется на лету, что позволяет сэкономить на памяти для указателей, требующихся в хеш-таблицах с цепочками.
Последовательность, в которой просматриваются ячейки хеш-таблицы, называется последовательностью проб . В общем случае, она зависит только от ключа элемента, то есть это последовательность h 0 ( x ), h 1 ( x ), …, h n — 1 ( x ), где x — ключ элемента, а h i ( x ) — произвольные функции, сопоставляющие каждому ключу ячейку в хеш-таблице. Первый элемент в последовательности, как правило, равен значению некоторой хеш-функции от ключа, а остальные считаются от него одним из приведённых ниже способов. Для успешной работы алгоритмов поиска последовательность проб должна быть такой, чтобы все ячейки хеш-таблицы оказались просмотренными ровно по одному разу.
Алгоритм поиска просматривает ячейки хеш-таблицы в том же самом порядке, что и при вставке, до тех пор, пока не найдется либо элемент с искомым ключом, либо свободная ячейка (что означает отсутствие элемента в хеш-таблице).
Удаление элементов в такой схеме несколько затруднено. Обычно поступают так: заводят булевый флаг для каждой ячейки, помечающий, удален элемент в ней или нет. Тогда удаление элемента состоит в установке этого флага для соответствующей ячейки хеш-таблицы, но при этом необходимо модифицировать процедуру поиска существующего элемента так, чтобы она считала удалённые ячейки занятыми, а процедуру добавления — чтобы она их считала свободными и сбрасывала значение флага при добавлении.
Последовательности проб
Ниже приведены некоторые распространенные типы последовательностей проб. Сразу оговорим, что нумерация элементов последовательности проб и ячеек хеш-таблицы ведётся от нуля, а N — размер хеш-таблицы (и, как замечено выше, также и длина последовательности проб).
- Линейное пробирование : ячейки хеш-таблицы последовательно просматриваются с некоторым фиксированным интервалом k между ячейками (обычно k = 1), то есть i -й элемент последовательности проб — это ячейка с номером (hash( x ) + ik ) mod N . Для того, чтобы все ячейки оказались просмотренными по одному разу, необходимо, чтобы k было взаимно-простым с размером хеш-таблицы.
-
: интервал между ячейками с каждым шагом увеличивается на константу. Если размер хеш-таблицы равен степени двойки (
N
= 2
p
), то одним из примеров последовательности, при которой каждый элемент будет просмотрен по одному разу, является:
- hash( x ) mod N , (hash( x ) + (1+1*1)/2) mod N , (hash( x ) + (2+2*2)/2) mod N , (hash( x ) + (3+3*3)/2) mod N , … - треугольные числа .
- : интервал между ячейками фиксирован, как при линейном пробировании, но, в отличие от него, размер интервала вычисляется второй, вспомогательной хеш-функцией, а значит, может быть различным для разных ключей. Значения этой хеш-функции должны быть ненулевыми и взаимно-простыми с размером хеш-таблицы, что проще всего достичь, взяв простое число в качестве размера, и потребовав, чтобы вспомогательная хеш-функция принимала значения от 1 до N — 1.
Ниже представлен код, демонстрирующий двойное хеширование:
// DICT_CELL_COUNT должно быть простым числом! #define DICT_CELL_COUNT 30011 char* szWordAr[ DICT_CELL_COUNT ]; unsigned int uWordArSize = 0; #define WORD_IDX_BAD ((unsigned int)-1) unsigned int uWordIdxByHashAr[ DICT_CELL_COUNT ]; // необходимо инициализировать элементы значением WORD_IDX_BAD #define STRIDE_1 17 #define STRIDE_2 13 // Функция GetOrAddWordIdx(..) возвращает индекс слова pcszWord в массиве szWordAr. // При этом происходит добавление слова pcszWord в словарь szWordAr, если его там нет. unsigned int GetOrAddWordIdx(const char* const pcszWord) { unsigned int uHash1 = 0, uHash2 = 0; const unsigned char* cbtWordCharCur = (const unsigned char*)pcszWord; // Вычислим два хеша слова pcszWord: // uHash1 лежит в диапазоне [ 0 .. DICT_CELL_COUNT - 1 ] // uHash2 лежит в диапазоне [ 1 .. DICT_CELL_COUNT - 1 ] do { uHash1 *= STRIDE_1; uHash1 += (STRIDE_2 * *cbtWordCharCur); uHash2 *= STRIDE_2; uHash2 += (STRIDE_1 * *cbtWordCharCur); } while(*(cbtWordCharCur++)); // NB: инкремент! // #1: cbtWordCharCur указывает на символ за посл. '\0' в pcszWord, // будет использовано в #2 uHash1 %= DICT_CELL_COUNT; uHash2 %= (DICT_CELL_COUNT - 1); ++uHash2; while(uWordIdxByHashAr[ uHash1 ] != WORD_IDX_BAD) { if (!strcmp(pcszWord, szWordAr[ uWordIdxByHashAr[ uHash1 ] ])) return uWordIdxByHashAr[ uHash1 ]; uHash1 += uHash2; uHash1 %= DICT_CELL_COUNT; } strcpy(szWordAr[ uWordIdxByHashAr[ uHash1 ] = // NB: присвоение! uWordArSize ] = // NB: присвоение! (char*)malloc(// длина pcszWord плюс 1: (const char*)cbtWordCharCur - // #2: используем значение cbtWordCharCur из #1 pcszWord), pcszWord); return uWordArSize++; // NB: инкремент! } // unsigned int GetOrAddWordIdx(const char* const pcszWord)
См. также
Литература
- Кормен, Т. , Лейзерсон, Ч. , Ривест, Р. , Штайн, К. Глава 11. Хеш-таблицы. // Алгоритмы: построение и анализ = Introduction to Algorithms / Под ред. И. В. Красикова. — 2-е изд. — М. : Вильямс, 2005. — 1296 с. — ISBN 5-8459-0857-4 .
- 2020-09-15
- 1