Interested Article - Неотрицательное матричное разложение

- 2021-08-06
- 1
Неотрицательное матричное разложение ( НМР ), а также неотрицательное приближение матрицы , это группа алгоритмов в и линейной алгебре , в которых матрица V разлагается на (обычно) две матрицы W и H , со свойством, что все три матрицы имеют неотрицательные элементы. Эта неотрицательность делает получившиеся матрицы более простыми для исследования. В приложениях, таких как обработка спектрограмм аудиосигнала или данных мускульной активности, неотрицательность свойственна рассматриваемым данным. Поскольку задача в общем случае неразрешима, её обычно численно аппроксимируют.
НМР нашёл применение в таких областях как астрономия , компьютерное зрение , кластеризация документов , хемометрика , , рекомендательные системы , и биоинформатика .
История
В хемометрике неотрицательное матричное разложение имеет долгую историю под названием «метод автомодельного разрешения кривых» В этом контексте вектора в правой матрице являются непрерывными кривыми, а не дискретными векторами. Ранние работы по неотрицательному матричному разложению были проведены финской группой исследователей в середине 1990-х под названием положительное разложение матрицы . Метод стал более широко известен как неотрицательное матричное разложение , после того как Ли и Сын исследовали свойства алгоритма и опубликовали несколько простых полезных алгоритмов для двух видов разложения .
Предпосылки
Пусть матрица V является произведением матриц W и H ,

Умножение матриц может быть имплементировано через вычисление вектора-столбца матрицы V как линейной комбинации векторов-столбцов в W , используя коэффициенты из столбцов матрицы H . То есть каждый столбец матрицы V может быть вычислен следующим образом:

где v i является i -ым вектор-столбцом произведения матрицы V , а h i является i -ым вектор-столбцом матрицы H .
При умножении матриц размерности матриц-сомножителей могут быть существенно меньше, чем размерность произведения матриц, и это то свойство, которое подводит базис под НМР. НМР создаёт множители с существенно уменьшенными размерностями по сравнению с исходной матрицей. Например, если V является m × n матрицей, W является m × p матрицей, а H является p × n матрицей, то p может быть существенно меньше как m , так и n .
Вот пример на основе приложения анализа текста:
- Пусть входная матрица (разлагаемая матрица) будет V с 10000 строками и 500 столбцами, где слова соответствуют строкам, а документы соответствуют столбцам. То есть у нас есть 500 документов, проиндексированных 10000 словами. Отсюда следует, что вектор-столбец v в V представляет документ.
- Допустим, мы спрашиваем алгоритм найти 10 признаков в порядке образования матрицы признаков W с 10000 строк и 10 столбцами и матрицу коэффициентов H с 10 строками и 500 столбцами.
- Произведение W и H является матрицей с 10000 строками и 500 столбцами, те же размеры, что и входная матрица V и, если разложение работает, оно является приемлемым приближением входной матрицы V .
- Из описания умножения матриц выше следует, что каждый столбец в произведении матриц WH является линейной комбинацией 10 вектор-столбцов в матрице признаков W с коэффициентами, полученными из матрицы H .
Это последнее свойство является базисом НМР, поскольку мы можем рассматривать каждый оригинальный документ в нашем примере как построенный из небольшого набора скрытых признаков. НМР создаёт эти признаки.
Полезно думать о каждом признаке (вектор-столбце) в матрице признаков W как о прототипе документа, включающем набор слов, в котором каждая ячейка, соответствующая слову, определяет ранг слова в признаке — чем выше значение в ячейке слова, тем выше ранг слова в признаке. Столбец в матрице коэффициентов H представляет оригинальный документ со значениями ячеек, определяющих ранг документа для признака. Мы теперь можем восстановить документ (вектор-столбец) из нашей входной матрицы в виде линейной комбинации наших признаков (вектор-столбцов из W ), где каждый признак берётся с весом, определяемым значением признака из вектор-столбца матрицы H .
Свойство кластеризации
НМР имеет внутреннее свойство кластеризации , т.е. он автоматически кластеризует столбцы входных данных . Это то свойство, которое востребовано большинством приложений НМР.
 . Это то свойство, которое востребовано большинством приложений НМР.
. Это то свойство, которое востребовано большинством приложений НМР.
Более конкретно, приближение посредством достигается минимизацией функции ошибок
 посредством
посредством
 достигается минимизацией функции ошибок
достигается минимизацией функции ошибок
при условиях
 при условиях
при условиях

Более того, вычисленная матрица даёт индикатор кластеров, т.е. если , этот факт показывает, что входные данные принадлежат k -му кластеру. Вычисленная же матрица даёт центры кластеров, т.е. k -ый столбец задаёт центр k -го кластера. Это представление центров может быть существенно улучшено посредством выпуклого НМР.
 даёт индикатор кластеров, т.е. если
даёт индикатор кластеров, т.е. если
 , этот факт показывает, что входные данные
, этот факт показывает, что входные данные
 принадлежат
k
-му кластеру. Вычисленная же матрица
принадлежат
k
-му кластеру. Вычисленная же матрица
 даёт центры кластеров, т.е.
k
-ый столбец задаёт центр
k
-го кластера. Это представление центров может быть существенно улучшено посредством выпуклого НМР.
даёт центры кластеров, т.е.
k
-ый столбец задаёт центр
k
-го кластера. Это представление центров может быть существенно улучшено посредством выпуклого НМР.
Если ортогональность не указана явно, ортогональность выполняется достаточно сильно и свойство кластеризации также имеет место. Кластеризация является главной целью большинства приложений НМР для data mining .
 не указана явно, ортогональность выполняется достаточно сильно и свойство кластеризации также имеет место. Кластеризация является главной целью большинства приложений НМР для
не указана явно, ортогональность выполняется достаточно сильно и свойство кластеризации также имеет место. Кластеризация является главной целью большинства приложений НМР для
Если в качестве функции ошибки используется расстояние Кульбака — Лейблера , НМР идентично вероятностному латентно-семантическому анализу , популярному методу кластеризации документов .
Типы
Приближённое неотрицательное разложение матрицы
Обычно число столбцов матрицы W и число строк матрицы H в НМР выбирается так, что произведение WH становится приближением к V . Полное разложение матрицы V тогда состоит из двух неотрицательных матриц W и H , а также из остаточной матрицы U , такой, что V = WH + U . Элементы остаточной матрицы могут быть и положительными, и отрицательными.
Если W и H меньше, чем V , их проще запомнить и с ними легче работать. Другая причина разложения V на меньшие матрицы W и H заключается в том, что если можно приблизительно представить элементы матрицы V существенно меньшим количеством данных, то можем заключить о некоторой неявной структуре данных.
Выпуклое неотрицательное разложение матрицы
В стандартном НМР множитель ,т.е. матрица W может быть любой в этом пространстве. Выпуклый НМР ограничивает столбцы матрицы W до выпуклых комбинаций входных векторов . Это существенно улучшает качество представления данных матрицы W . Более того, множитель H становится более разрежен и ортогонален.
 ,т.е. матрица
W
может быть любой в этом пространстве. Выпуклый НМР
ограничивает столбцы матрицы
W
до
,т.е. матрица
W
может быть любой в этом пространстве. Выпуклый НМР
ограничивает столбцы матрицы
W
до
 . Это существенно улучшает качество представления данных матрицы
W
. Более того, множитель
H
становится более разрежен и ортогонален.
. Это существенно улучшает качество представления данных матрицы
W
. Более того, множитель
H
становится более разрежен и ортогонален.
Разложение неотрицательного ранга
В случае, когда матрицы V равен обычному рангу, V = WH называется разложением неотрицательного ранга (НРР, англ. Nonnegative rank factorization , NRF) . Известно, что задача поиска НРР матрицы V , если такой существует, NP-трудна .
Различные функции цены и регуляризация
Существуют различные виды неотрицательного разложения матрицы. Различные виды возникают от использования различных функций цены для измерения расхождения между V и WH и возможной регуляризации матрицы W и/или матрицы H .
Две простые функции расхождения, которые изучали Ли и Сын, были квадратичное отклонение (или норма Фробениуса ) и расширение понятия расстояния Кульбака — Лейблера на положительные матрицы (изначально расстояние Кульбака — Лейблера было определено для вероятностных распределений). Каждая функция расхождения приводит к своему алгоритму НМР, который обычно минимизирует расхождение с помощью итеративных правил обновления.
Задача разложения в версии функции квадратичной ошибки для НМР может быть сформулирована следующим образом: Если дана матрица , нужно найти неотрицательные матрицы W и H, которые минимизируют функцию
 , нужно найти неотрицательные матрицы W и H, которые минимизируют функцию
, нужно найти неотрицательные матрицы W и H, которые минимизируют функцию

Другой вид НМР для изображений базируется на норме, определяемой полной вариацией .
Если L1 регуляризация (сходная с , англ. Least Absolute Shrinkage and Selection Operator) добавлена к НМР с целевой функцией, равной среднему квадрату ошибки, получающаяся задача может быть названа неотрицательным разреженным кодированием ввиду похожести на задачу разреженного кодирования , хотя она может упоминаться и под названием НМР .
Онлайн НМР
Многие стандартные НМР алгоритмы анализируют все данные вместе. Т.е. вся матрица доступна с самого начала. Это может оказаться неприемлемым для приложений, в которых данные занимают слишком много памяти, чтобы поместить их все в одновременно, или где данные поступают в виде потока . Такая ситуация характерна для коллаборативной фильтрации в рекомендательных системах , где может имеется много пользователей и много объектов для рекомендации, а пересчитывать всё было бы неэффективно, когда в систему добавляется пользователь или объект. Целевая функция для оптимизации в этих случаях может быть, а может и не быть такой же, как в стандартном НМР, но алгоритмы должны отличаться .
Алгоритмы
Есть несколько способов, каким может быть найдены W и H . Ли и Сына было популярно ввиду простоты имплементации.
Алгоритм:
- Инициализация: W и H не отрицательны.
- Обновляем значения в W и H путём вычисления (здесь — индекс итерации)
- и
- Пока W и H не стабилизируются.
 — индекс итерации)
— индекс итерации)
![{\displaystyle H_{[i,j]}^{n+1}\leftarrow H_{[i,j]}^{n}{\frac {((W^{n})^{T}V)_{[i,j]}}{((W^{n})^{T}W^{n}H^{n})_{[i,j]}}}}](/images/000/266/266938/19.jpg?rand=562754)
![{\displaystyle W_{[i,j]}^{n+1}\leftarrow W_{[i,j]}^{n}{\frac {(V(H^{n+1})^{T})_{[i,j]}}{(W^{n}H^{n+1}(H^{n+1})^{T})_{[i,j]}}}}](/images/000/266/266938/20.jpg?rand=559661)
Заметим, что обновление осуществляется поэлементно, не умножением матриц.
Недавно был разработан другой алгоритм. Некоторые подходы базируются на чередуемом
(МНКНВ) — на каждом шаге такого алгоритма фиксируется сначала
H
, а
W
ищется с помощью МНКНВ, затем фиксируется
W
и теперь находится
H
аналогично. Процедуры, используемые для поиска
W
и
H
, могут быть теми же самыми
или различными, так как некоторые варианты НМР регуляризуют одну из матриц
W
или
H
. Некоторые подходы включают, среди других, методы проецируемого
градиентного спуска
,
, метод оптимального градиента
и блочный метод главного ведущего элемента
.
Существующие в настоящее время алгоритмы субоптимальны, поскольку они гарантируют нахождение только локального, а не глобального минимума целевой функции. Доказанные оптимальные алгоритмы в ближайшем будущем вряд ли появятся, поскольку задача, как было показано, обобщает метод k-средних, который, как известно, NP-полон . Однако, как и во многих других задачах анализа данных, знание локального минимума тоже полезно.
Последовательный НМР
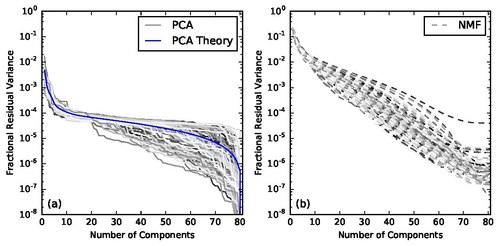
Последовательное построение компонент НМР ( W и H ) было первоначально использовано для связывания НМР с методом главных компонент (МГК) в астрономии . Вклады компонент МГК ранжируются по величине их соответствующих собственных значений. Для НМР его компоненты можно ранжировать эмпирически, если они строятся один за другим (последовательно), т.е. строим -ую компоненту с уже построенными первыми компонентами.
 -ую компоненту с уже построенными первыми
-ую компоненту с уже построенными первыми
 компонентами.
компонентами.
Вклады последовательных компонент НМР можно сравнивать по теореме Карунена — Лоэва с помощью графика собственных значений. Типичный выбор числа компонент в МГК базируется на точке «изгиба», тогда существование плоского участка свидетельствует, что МГК не воспринимает данные эффективно, а если существует неожиданное падение, это говорит о случайном шуме и попадании в режим чрезмерной подгонки . Для последовательного НМР график собственных значений приближается графиком относительной остаточной дисперсии, где кривая убывает непрерывно и сходится к большему значению, чем МГК , что говорит о меньшей чрезмерной подгонке последовательного НМР.
Точный НМР
Точные решения для вариантов НМР могут быть проверены (за полиномиальное время), если выполняются дополнительные ограничения для матрицы V . Алгоритм полиномиального времени решения неотрицательного рангового разложения, когда матрица V содержит мономиальную подматрицу с рангом, равным рангу матрицы дали Кэмпбелл и Пул в 1981 . Калофольяс и Галлопоулус (2012) решили симметричный аналог этой задачи, где V является симметричной и содержит диагональную главную подматрицу ранга r. Их алгоритм работает за время в плотном случае. Арора с группой исследователей предложили алгоритм полиномиального времени для точного НМР, который работает в случае, когда один из множителей W удовлетворяет условию отделимости .
 в плотном случае. Арора с группой исследователей предложили алгоритм полиномиального времени для точного НМР, который работает в случае, когда один из множителей W удовлетворяет условию отделимости
.
в плотном случае. Арора с группой исследователей предложили алгоритм полиномиального времени для точного НМР, который работает в случае, когда один из множителей W удовлетворяет условию отделимости
.
Связь с другими техниками
В статье Изучение частей объектов путём неотрицательных разложений матрицы Ли и Сын предложили НМР главным образом для основанного на частях разложения изображений. В статье НМР сравнивается с векторным квантованием и методом главных компонент и показывается, что, хотя эти три техники могут быть записаны как разложения, они воспринимают различные ограничения, а потому дают различные результаты.

 .
.
Позднее было показано, что некоторые типы НМР являются экземплярами более общей вероятностной модели, называемой «мультиномиальной МГК» . Если НМР получено путём минимизации расстояния Кульбака — Лейблера , это, фактически, эквивалентно другому экземпляру мультиномильной МГК, вероятностному латентно-семантическому анализу , настроенному с помощью оценки максимального правдоподобия . Этот метод обычно используется для анализа и кластеризации текстовых данных и он связан также с .
НМР с целевой функцией метода наименьших квадратов эквивалентен ослабленной форме метода k-средних — матричный множитель W содержит центроиды кластеров, а H содержит индикаторы принадлежности кластерам . Это даёт теоретическое обоснование для применения НМР для кластеризации данных. Однако k-средние не обеспечивают неотрицательности на центроидах, так что наиболее близкой аналогией является, фактически, «полу-НМР» .
НМР можно рассматривать как двухуровневую ориентированную графическую модель с одним уровнем наблюдаемых случайных переменных и одним уровнем скрытых случайных переменных .
НМР можно расширить с матриц до тензоров произвольного порядка . Это расширение можно рассматривать как неотрицательный аналог, например, модели .
Другие расширения НМР включают совместное разложение нескольких матриц и тензоров, где некоторые сомножители одинаковы. Такие модели полезны для сочетания датчиков и обучению связям .
НМР является экземпляром неотрицательного квадратичного программирования (НКП), точно так же, как и метод опорных векторов (МОВ). Однако МОВ и НМР связаны более тесно, чем просто через НКП, что позволяет прямое применение алгоритмов, разработанных для решений любого из двух методов, к задачам обоих областей .
Единственность
Разложение не единственно — матрица и её обратная могут быть использованы для преобразования двух матриц разложения посредством, например, ,

Если две новые матрицы и неотрицательны , они образуют другую параметризацию разложения.
 и
и

Неотрицательность и следует, если, по меньшей мере, B является неотрицательной . В этом простом случае она соответствует просто масштабированию и перестановке .
 и
и
 следует, если, по меньшей мере,
B
является неотрицательной
. В этом простом случае она соответствует просто масштабированию и
следует, если, по меньшей мере,
B
является неотрицательной
. В этом простом случае она соответствует просто масштабированию и
Дополнительный контроль над неоднозначностью НМР приобретается ограничением заполненности матриц .
Приложения
Астрономия
В астрономии НМР является многообещающим методом для понижения размерности в смысле, что астрофизические сигналы являются неорицательными. НМР применяется для спектроскопических наблюдений и прямых наблюдений как метод изучения общих свойств астрономического объекта и постобработки астрономических наблюдений. Продвижение в спектроскопических наблюдениях исследователей Блэнтона и Роуиза (2007) связано с принятием во внимание неопределённости астрономических наблюдений, что позднее улучшил Зу (2016) , который рассматривал также отсутствие данных и использовал параллельные вычисления . Их методы затем приспособили Рен и др. (2018) для прямого поля наблюдения как один из методов обнаружения экзопланет , особенно для прямого наблюдения околозвёздных дисков .
Рен и др. (2018) смогли показать стабильность компонент НМР, когда они строятся последовательно (т.е. одна за другой), что обеспечивает линейность процесса моделирования НМР. Свойство линейности использовалось для отделения света звезды от рассеянного света экзопланет и околозвёздных дисков .
При прямом наблюдении для выделения тусклых экзопланет и околозвёздных дисков от окружающего звезду яркого света, который имеет типичную контрастность от 10⁵ до 10¹⁰, были приспособлены различные статистические методы , однако выделение света от экзопланет или околозвёздных дисков обычно страдает переподгонкой, так что для обнаружения истинного течения должно быть применено последующее моделирование . Моделирование на настоящее время оптимизировано для точечных источников , но не для структур с нерегулярными формами, такими как s околозвёздные диски. В этой ситуации НМР является отличным методом, менее страдающим от переподгонки в смысле неотрицательности и разреженности коэффициентов моделирования НМР, поэтому моделирование может быть осуществлено с несколькими масштабирующими множителями вместо вычислительно ёмкой переобработки данных на полученных моделях.
Интеллектуальный анализ текста
НМР может быть использована для интеллектуального анализа текста . В этом процессе строится терм-документная матрица с весами различных объектов (обычно — взвешенная информация о частоте встречаемости слов) из набора документов. Матрица разлагается на матрицы объект-признак и признак-документ . Признаки получаются из контекста документов, а матрица признак-документ описывает кластеры данных связанных документов.
Одно из приложений использует иерархический НМР на небольшом подмножестве научных абстракций из PubMed . Другая группа исследователей сгруппировала множество email компании Enron (65033 сообщений и 91133 объектов) в 50 кластеров . НМР применяется также для данных о цитировании, с одним примером кластеризации статей английской Википедии и научных журналов , основываясь на научных цитатах в английской Википедии .
Арора и др. предложили алгоритмы полиномиального времени для обучения тематических моделей с помощью НМР. Алгоритм предполагает, что тематическая матрица удовлетворяет условию отделимости, что часто выполняется в таких условиях .
Спектральный анализ данных
НМР используется также в анализе спектральных данных. Одно из таких применений — классификация межпланетных объектов и обломков .
Предсказание масштабируемого сетевого расстояния
НМР используется в предсказании масштабируемого сетевого расстояния в интернете (время оборота пакета). Для сети с хостами с помощью НМР расстояния всех соединений от точки до точки могут быть предсказаны после проведения лишь измерений. Этот вид метода был впервые предложен в «Сервисе оценки интернет-расстояния» ( англ. Internet Distance Estimation Service , IDES) . Впоследствии, как полностью децентрализованный подход, была предложена сетевая координатная система Phoenix ( англ. Phoenix network coordinate system) . Она достигла лучшей предсказуемости путём введения концепции веса.
 хостами с помощью НМР расстояния всех
хостами с помощью НМР расстояния всех
 соединений от точки до точки могут быть предсказаны после проведения лишь
соединений от точки до точки могут быть предсказаны после проведения лишь
 измерений. Этот вид метода был впервые предложен в «Сервисе оценки интернет-расстояния» (
измерений. Этот вид метода был впервые предложен в «Сервисе оценки интернет-расстояния» (
Удаление нестационарного шума из разговора
Удаление шума из разговора является давней проблемой в . Есть большое число алгоритмов удаления шума, если шум стационарен. Например, фильтр Винера пригоден для аддитивного гауссова шума . Однако, если шум не стационарен, классические алгоритмы удаления шума обычно имеют плохую производительность, поскольку статистическую информацию о нестационарном шуме трудно оценить. Шмидт и др. использовали НМР для удаления нестационарного шума в разговоре, что полностью отличается от классических статистических подходов. Ключевой идеей является то, что чистый сигнал может быть представлен словарём разговора, а нестационарный шум представлен быть не может. Аналогично, нестационарный шум может быть представлен словарём шумов, а разговор не может.
Алгоритм для удаления шума с помощью НМР работает следующим образом. Необходимо обучить офлайн два словаря, один для разговора, другой для шума. Как только подаётся разговор с шумом, сначала вычисляем величину оконного преобразования Фурье . Затем разделяем его на две части с помощью НМР, одна часть может быть представлена словарём разговора, а другая часть может быть представлена словарём шума. На третьем шаге часть, представленная словарём разговора, оценивается как чистый разговор.
Биоинформатика
НМР успешно применяется в биоинформатике для кластеризации данных экспрессии генов и метилирования ДНК и поиска генов, наиболее представляющих кластеры . В анализе мутаций рака это используется для выделения общих механизмов возникновения мутации, которые случаются во многих случаях рака и, возможно, имеют различные причины .
Радионуклидная визуализация
НМР, упоминаемый в этой области как факторный анализ, используется здесь с 1980-ых годов для анализа последовательности изображений в ОФЭКТ и ПЭТ . Неоднозначность НМР решалась наложением ограничения разреженности .
Текущие исследования
Текущие исследования (с 2010 года) по разложению неотрицательных матриц включают, но не ограничиваются следующими вопросами
- Алгоритмические вопросы: поиск глобального минимума множителей и инициализация множителя .
- Вопросы масштабирования: как разложить матрицы размером миллион-на-миллиард, которые возникают при анализе данных в сетях. См. статьи «Распределённое неотрицательное разложение матрицы (DNMF)» и «Масшабируемое неотрицательное разложение матрицы (ScalableNMF)» .
- Онлайн-обработка: как обновлять разложение, когда приходят новые данные, без полного вычисления с нуля .
- Совместное разложение: разложение нескольких внутренне связанных матриц для многопозиционной кластеризации, см. CoNMF и MultiNMF .
- Задача Коэна и Ротблюма 1993 года: всегда ли рациональная матрица имеет НМР минимальной внутренней размерности, множители которой также рациональны. Недавно на этот вопрос был получен отрицательный ответ .
См. также
Примечания
- ↑ .
- .
- ↑ , с. 734-754.
- ↑ , с. 104.
- ↑ , с. 69–77.
- .
- , с. e28898.
- , с. 617+.
- , с. 111–126.
- , с. 1705-1718.
- ↑ , с. 788-791.
- ↑ , с. 556-562.
- ↑ , с. 606-610.
- , с. 3913-3927.
- ↑ , с. 45-55.
- , с. 161–172.
- .
- , с. 393–394.
- , с. 1364–1377.
- , с. 1824–183.
- ↑ .
- ↑ , с. e46331.
- , с. 1064.
- (неопр.) . Дата обращения: 16 октября 2018. 24 сентября 2015 года.
- , с. 284–287.
- , с. 1087–1099.
- ↑ , с. 2756–2779.
- , с. 1589–1596.
- , с. 713-730.
- , с. 2882–2898.
- , с. 3261-3281.
- , с. 285-319.
- ↑ Zhu, Guangtun B. (2016-12-19), Nonnegative Matrix Factorization (NMF) with Heteroscedastic Uncertainties and Missing data, arΧiv : [astro-ph.IM].
- ↑ , с. L28.
- ↑ , с. 117.
- , с. 175–182.
- , с. 421–435.
- ↑ .
- , с. 788–791.
- , с. 23–34.
- , с. 601–602.
- .
- .
- , с. 854-888.
- , с. 1255-1261.
- , с. 311-326.
- .
- , с. 1218–1229.
- , с. 267-273.
- , с. 2529-2533.
- .
- , с. 948.
- , с. A24.
- , с. 520–522.
- .
- , с. 249-264.
- .
- , с. 155-173.
- , с. 2273-2284.
- , с. 334–347.
- , с. 431–436.
- , с. e1000029.
- , с. 1495-1502.
- , с. 359-371.
- , с. 246–259.
- , с. 1310–21.
- , с. 216–25.
- , с. 1350–1362.
- .
- .
- , с. 44–56.
- .
- , с. 252–260.
- Chistikov, Dmitry; Kiefer, Stefan; Marušić, Ines; Shirmohammadi, Mahsa & Worrell, James (2016-05-22), Nonnegative Matrix Factorization Requires Irrationality, arΧiv : [cs.CC].
Литература
- Max Welling, Michal Rosen-zvi, Geoffrey E. Hinton. Exponential Family Harmoniums with an Application to Information Retrieval // . — 2004.
- Julian Eggert, Edgar Körner. Sparse coding and NMF // . — 2004.
- Schmidt M.N., Larsen J., Hsiao F.T. Wind noise reduction using non-negative sparse coding // Machine Learning for Signal Processing, IEEE Workshop. — 2007.
- Ron Zass, Amnon Shashua . A Unifying Approach to Hard and Probabilistic Clustering // . — Beijing, China, 2005.
- Ding C., Li T., Jordan M.I. Convex and semi-nonnegative matrix factorizations // IEEE Transactions on Pattern Analysis and Machine Intelligence. — 2010.
- Pentti Paatero. The Multilinear Engine: A Table-Driven, Least Squares Program for Solving Multilinear Problems, including the n-Way Parallel Factor Analysis Model // . — 1999. — Т. 8 , вып. 4 . — С. 854–888 . — doi : . — JSTOR .
- Max Welling, Markus Weber. Positive Tensor Factorization // . — 2001. — Т. 22 , вып. 12 . — doi : .
- Jingu Kim, Haesun Park. Fast Nonnegative Tensor Factorization with an Active-set-like Method // . — Springer, 2012. — С. 311–326.
- Kenan Yilmaz, A. Taylan Cemgil, Umut Simsekli. Generalized Coupled Tensor Factorization // . — 2011.
- Vamsi K. Potluru, Sergey M. Plis, Morten Morup, Vince D. Calhoun, Terran Lane. Efficient Multiplicative updates for Support Vector Machines // Proceedings of the 2009 SIAM Conference on Data Mining (SDM). — 2009. — С. 1218–1229.
- Wei Xu, Xin Liu, Yihong Gong. Document clustering based on non-negative matrix factorization // . — New York: Association for Computing Machinery , 2003.
- Rashish Tandon, Suvrit Sra. . — 2010. — (Technical Report).
- Rainer Gemulla, Erik Nijkamp, Peter J Haas, Yannis Sismanis. Large-scale matrix factorization with distributed stochastic gradient descent // . — 2011. — С. 69–77. (недоступная ссылка)
- Yang Bao. TopicMF: Simultaneously Exploiting Ratings and Reviews for Recommendation // . — 2014.
- Ben Murrell. Non-Negative Matrix Factorization for Learning Alignment-Specific Models of Protein Evolution // PLoS ONE. — 2011. — Т. 6 , вып. 12 . — doi : . — . — PMC .
- Ding C., Li T., Peng W. // Computational Statistics & Data Analysis. — 2008. — Вып. 52 . 4 марта 2016 года.
- William H. Lawton, Edward A. Sylvestre. Self modeling curve resolution // . — 1971. — Т. 13 , вып. 3 . — doi : . — JSTOR .
- Paatero P., Tapper U. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values // . — 1994. — Т. 5 , вып. 2 . — doi : .
- Pia Anttila, Pentti Paatero, Unto Tapper, Olli Järvinen. Source identification of bulk wet deposition in Finland by positive matrix factorization // . — 1995. — Т. 29 , вып. 14 . — doi : . — Bibcode : .
- Daniel D. Lee, H. Sebastian Seung. Learning the parts of objects by non-negative matrix factorization // Nature . — 1999. — Т. 401 , вып. 6755 . — doi : . — Bibcode : . — .
- Daniel D. Lee, H. Sebastian Seung. Algorithms for Non-negative Matrix Factorization // . — MIT Press , 2001.
- Zhang T., Fang B., Liu W., Tang Y. Y., He G., Wen J. Total variation norm-based nonnegative matrix factorization for identifying discriminant representation of image patterns // . — 2008. — Т. 71 , вып. 10–12 . — doi : .
- Berman A., Plemmons R.J. Inverses of nonnegative matrices // Linear and Multilinear Algebra. — 1974. — Т. 2 , вып. 2 . — С. 161–172 . — doi : .
- Berman A., Plemmons R.J. Nonnegative matrices in the Mathematical Sciences. — Philadelphia: SIAM, 1994.
- Thomas L.B. Problem 73-14, Rank factorization of nonnegative matrices // SIAM Rev.. — 1974. — Т. 16 , вып. 3 . — doi : .
- Vavasis S.A. On the complexity of nonnegative matrix factorization // SIAM J. Optim.. — 2009. — Т. 20 , вып. 3 . — doi : . — arXiv : .
- Inderjit S. Dhillon, Suvrit Sra. Generalized Nonnegative Matrix Approximations with Bregman Divergences // . — 2005.
- Campbell S.L., Poole G.D. Computing nonnegative rank factorizations // Linear Algebra Appl.. — 1981. — Т. 35 . — doi : .
- Kalofolias V., Gallopoulos E. // Linear Algebra Appl. — 2012. — Т. 436 , вып. 2 . — doi : .
- Sanjeev Arora, Rong Ge, Yoni Halpern, David Mimno, Ankur Moitra, David Sontag, Yichen Wu, Michael Zhu. A practical algorithm for topic modeling with provable guarantees // . — 2013.
- Daniel D Lee, H Sebastian Seung. // Nature . — 1999. — Т. 401 , вып. 6755 . — doi : . — Bibcode : . — .
- Wray Buntine. Variational Extensions to EM and Multinomial PCA // . — 2002. — Т. 2430. — (LNAI).
- Eric Gaussier, Cyril Goutte. Relation between PLSA and NMF and Implications // . — 2005. от 28 сентября 2007 на Wayback Machine
- Patrik O. Hoyer. Non-negative sparse coding // . — 2002.
- Leo Taslaman, Björn Nilsson. A framework for regularized non-negative matrix factorization, with application to the analysis of gene expression data // PLoS One . — 2012. — Т. 7 , вып. 11 . — С. e46331 . — doi : . — Bibcode : . — . — PMC .
- Hsieh C. J., Dhillon I. S. Fast coordinate descent methods with variable selection for non-negative matrix factorization // . — 2011. — ISBN 9781450308137 . — doi : .
- Yik-Hing Fung, Chun-Hung Li, William K. Cheung. . — IEEE Computer Society, 2007. — Ноябрь.
- Naiyang Guan, Dacheng Tao, Zhigang Luo, Bo Yuan. Online Nonnegative Matrix Factorization With Robust Stochastic Approximation // IEEE Transactions on Neural Networks and Learning Systems. — 2012. — Июль (т. 23 , вып. 7). — doi : . — .
- Chih-Jen Lin. // . — 2007. — Т. 19 , вып. 10 . — С. 2756–2779 . — doi : . — .
- Chih-Jen Lin. On the Convergence of Multiplicative Update Algorithms for Nonnegative Matrix Factorization // IEEE Transactions on Neural Networks. — 2007. — Т. 18 , вып. 6 . — doi : .
- Hyunsoo Kim, Haesun Park. // . — 2008. — Т. 30 , вып. 2 . — С. 713–730 . — doi : .
- Naiyang Guan, Dacheng Tao, Zhigang Luo, Bo Yuan. NeNMF: An Optimal Gradient Method for Nonnegative Matrix Factorization // IEEE Transactions on Signal Processing. — 2012. — Июнь (т. 60 , вып. 6). — С. 2882–2898 . — doi : . — Bibcode : .
- Jingu Kim, Haesun Park. // . — 2011. — Т. 58 , вып. 6 . — doi : . (недоступная ссылка)
- Jingu Kim, Yunlong He, Haesun Park. // . — 2013. — Т. 33 , вып. 2 . — С. 285–319 . — doi : .
- Ding C., He X., Simon H.D. On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering // . — 2005. — Т. 4. — ISBN 978-0-89871-593-4 . — doi : .
- Michael R. Blanton, Sam Roweis. K-corrections and filter transformations in the ultraviolet, optical, and near infrared // The Astronomical Journal. — 2007. — Т. 133 , вып. 2 . — doi : . — Bibcode : . — arXiv : .
- Bin Ren, Laurent Pueyo, Guangtun B. Zhu, Gaspard Duchêne. Non-negative Matrix Factorization: Robust Extraction of Extended Structures // The Astrophysical Journal. — 2018. — Т. 852 , вып. 2 . — С. 104 . — doi : . — Bibcode : . — arXiv : .
- David Lafrenière, Christian Maroid, René Doyon, Travis Barman. HST/NICMOS Detection of HR 8799 b in 1998 // The Astrophysical Journal Letters. — 2009. — Т. 694 , вып. 2 . — С. L148 . — doi : . — Bibcode : . — arXiv : .
- Adam Amara, Sascha P. Quanz. PYNPOINT: an image processing package for finding exoplanets // Monthly Notices of the Royal Astronomical Society. — 2012. — Т. 427 , вып. 2 . — doi : . — Bibcode : . — arXiv : .
- Rémi Soummer, Laurent Pueyo, James Larkin. Detection and Characterization of Exoplanets and Disks Using Projections on Karhunen-Loève Eigenimages // The Astrophysical Journal Letters. — 2012. — Т. 755 , вып. 2 . — doi : . — Bibcode : . — arXiv : .
- Zahed Wahhaj, Lucas A. Cieza, Dimitri Mawet, Bin Yang, Hector Canovas, Jozua de Boer, Simon Casassus, François Ménard, Matthias R. Schreiber, Michael C. Liu, Beth A. Biller, Eric L. Nielsen, Thomas L. Hayward. Improving signal-to-noise in the direct imaging of exoplanets and circumstellar disks with MLOCI // Astronomy & Astrophysics. — 2015. — Т. 581 , вып. 24 . — С. A24 . — doi : . — Bibcode : . — arXiv : .
- Laurent Pueyo. Detection and Characterization of Exoplanets using Projections on Karhunen Loeve Eigenimages: Forward Modeling // The Astrophysical Journal. — 2016. — Т. 824 , вып. 2 . — doi : . — Bibcode : . — arXiv : .
- Finn Årup Nielsen, Daniela Balslev, Lars Kai Hansen. Mining the posterior cingulate: segregation between memory and pain components // . — 2005. — Т. 27 , вып. 3 . — С. 520–522 . — doi : . — .
- William Cohen. . — 2005. — Апрель.
- Michael W. Berry, Murray Browne. Email Surveillance Using Non-negative Matrix Factorization // . — 2005. — Т. 11 , вып. 3 . — doi : .
- Finn Årup Nielsen. // Wikimania . — 2008.
- Berry M.W., Browne M., Langville A.N., Pauca V.P., Plemmons R.J. Algorithms and Applications for Approximate Nonnegative Matrix Factorization // Computational Statistics and Data Analysis. — 2007.
- Yun Mao, Lawrence Saul, Jonathan M. Smith. IDES: An Internet Distance Estimation Service for Large Networks // . — 2006. — Т. 24 , вып. 12 . — С. 2273–2284 . — doi : .
- Yang Chen, Xiao Wang, Cong Shi. . — 2011. — Т. 8 , вып. 4 . — doi : . 14 ноября 2011 года.
- Devarajan K. Nonnegative Matrix Factorization: An Analytical and Interpretive Tool in Computational Biology // PLoS Computational Biology . — 2008. — Т. 4 , вып. 7 . — doi : . — Bibcode : . — . — PMC .
- Hyunsoo Kim, Haesun Park. // . — 2007. — Т. 23 , вып. 12 . — doi : . — .
- Schwalbe E. DNA methylation profiling of medulloblastoma allows robust sub-classification and improved outcome prediction using formalin-fixed biopsies // . — 2013. — Т. 125 , вып. 3 . — doi : . — . — PMC .
- Ludmil B. Alexandrov, Serena Nik-Zainal, David C. Wedge, Peter J. Campbell, Michael R. Stratton. Deciphering signatures of mutational processes operative in human cancer // Cell Reports. — 2013. — Январь (т. 3 , вып. 1). — ISSN . — doi : . — . — PMC .
- Di Paola R., Bazin J.P., Aubry F., Aurengo A., Cavailloles F., Herry J.Y., Kahn E. Handling of dynamic sequences in nuclear medicine // . — 1982. — Т. NS-29 , вып. 4 . — doi : . — Bibcode : .
- Sitek A., Gullberg G.T., Huesman R.H. Correction for ambiguous solutions in factor analysis using a penalized least squares objective // . — 2002. — Т. 21 , вып. 3 . — doi : . — .
- Boutsidis C., Gallopoulos E. SVD based initialization: A head start for nonnegative matrix factorization // Pattern Recognition. — 2008. — Т. 41 , вып. 4 . — С. 1350–1362 . — doi : .
- Chao Liu, Hung-chih Yang, Jinliang Fan, Li-Wei He, Yi-Min Wang. // Proceedings of the 19th International World Wide Web Conference. — 2010.
- Jiangtao Yin, Lixin Gao, Zhongfei (Mark) Zhang. // Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases. — 2014.
- Dong Wang, Ravichander Vipperla, Nick Evans, Thomas Fang Zheng. // IEEE Transactions on Signal Processing. — 2013. — Т. 61 , вып. 1 . — С. 44–56 . — doi : . — Bibcode : . 19 апреля 2015 года.
- Xiangnan He, Min-Yen Kan, Peichu Xie, Xiao Chen. // Proceedings of the 23rd International World Wide Web Conference. — 2014. 2 апреля 2015 года.
- Jialu Liu, Chi Wang, Jing Gao, Jiawei Han. . — Proceedings of SIAM Data Mining Conference. — 2013. — С. 252–260. — ISBN 978-1-61197-262-7 . — doi : .
Дополнительная литература
- Shen J., Israël G. W. // . — 1989. — Т. 23 , вып. 10 . — С. 2289–2298 . — doi : . — Bibcode : .
- Pentti Paatero. Least squares formulation of robust non-negative factor analysis // . — 1997. — Т. 37 , вып. 1 . — С. 23–35 . — doi : .
- Raul Kompass. A Generalized Divergence Measure for Nonnegative Matrix Factorization // . — 2007. — Т. 19 , вып. 3 . — С. 780–791 . — doi : . — .
- Liu W.X., Zheng N.N., You Q.B. // . — 2006. — Т. 51 , вып. 17–18 . — С. 7–18 . — doi : . — Bibcode : . (недоступная ссылка)
- Ngoc-Diep Ho, Paul Van Dooren, Vincent Blondel. Descent Methods for Nonnegative Matrix Factorization. — 2008.
- Andrzej Cichocki, Rafal Zdunek, Shun-ichi Amari. Nonnegative Matrix and Tensor Factorization // . — 2008. — Т. 25 , вып. 1 . — С. 142–145 . — doi : . — Bibcode : .
- Cédric Févotte, Nancy Bertin, Jean-Louis Durrieu. Nonnegative Matrix Factorization with the Itakura-Saito Divergence: With Application to Music Analysis // . — 2009. — Т. 21 , вып. 3 . — С. 793–830 . — doi : . — .
- Ali Taylan Cemgil. // . — 2009. — Т. 2009 , вып. 2 . — С. 1–17 . — doi : . — . — PMC . (недоступная ссылка)
- 2021-08-06
- 1








