 и скрытый
и скрытый
 слои сети. Связи между слоями задаются с помощью
слои сети. Связи между слоями задаются с помощью
 (размера
m
×
n
), а также смещений
(размера
m
×
n
), а также смещений
 для видимого слоя и
для видимого слоя и
 для скрытого слоя.
для скрытого слоя.



 —
—
 для всех возможных сетей (иными словами,
для всех возможных сетей (иными словами,
 — константа нормализации, которая гарантирует, что сумма всех вероятностей равна единице). Определение вероятности для отдельного входного вектора (маргинальное распределение) проводится аналогично через сумму конфигураций всевозможных скрытых слоёв
:
— константа нормализации, которая гарантирует, что сумма всех вероятностей равна единице). Определение вероятности для отдельного входного вектора (маргинальное распределение) проводится аналогично через сумму конфигураций всевозможных скрытых слоёв
:

 видимых элементов и для
видимых элементов и для
 скрытых элементов условные вероятности
v определяются через произведения вероятностей
h :
скрытых элементов условные вероятности
v определяются через произведения вероятностей
h :


 и
и

 —
—

 (матрицы, в которой каждая строка соответствует одному образцу видимого вектора
(матрицы, в которой каждая строка соответствует одному образцу видимого вектора
 ), определяемой как произведение вероятностей
), определяемой как произведение вероятностей

![{\displaystyle \arg \max _{W}\mathbb {E} [\log P(v)].}](/images/000/267/267011/25.jpg?rand=967085)
 , его предложил
, его предложил
 поправляется на разность позитивного и негативного градиента, помноженного на множитель, задающий скорость обучения:
поправляется на разность позитивного и негативного градиента, помноженного на множитель, задающий скорость обучения:
 .
.
 ,
,
 .
.

Машина Больцмана
- 1 year ago
- 0
- 0

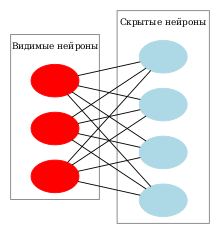
Ограниченная машина Больцмана ( англ. restricted Boltzmann machine), сокращённо RBM — вид генеративной стохастической нейронной сети , которая определяет распределение вероятности на входных образцах данных.
Первая ограниченная машина Больцмана была построена в 1986 году Полом Смоленски под названием Harmonium , но приобрела популярность только после изобретения Хинтоном быстрых алгоритмов обучения в середине 2000-х годов.
Такое название машина приобрела как модификация обычной машины Больцмана , в которой нейроны разделили на видимые и скрытые, а связи допустимы только между нейронами разного типа, таким способом ограничив связи. Значительно позже, в 2000-х годах, ограниченные машины Больцмана приобрели большую популярность и стали рассматриваться уже не как вариации машины Больцмана, а как особые компоненты в архитектуре сетей глубинного обучения . Объединение нескольких каскадов ограниченных машин Больцмана формирует глубокую сеть доверия , особый вид многослойных нейронных сетей, которые могут самообучаться без учителя при помощи алгоритма обратного распространения ошибки .
Особенностью ограниченных машин Больцмана является возможность проходить обучение без учителя , но в определённых приложениях ограниченные машины Больцмана обучаются с учителем. Скрытый слой машины представляет собой глубокие признаки в данных, которые выявляются в процессе обучения (см. также Data mining ).
Ограниченные машины Больцмана имеют широкий спектр применений — это задачи снижения размерности данных , задачи классификации , коллаборативная фильтрация , выделение признаков ( англ. feature learning) и тематическое моделирование .
В ограниченной машине Больцмана нейроны образуют двудольный граф , с одной стороны графа находятся видимые нейроны (вход), а с другой стороны — скрытые, причём перекрёстные связи устанавливаются между каждым видимым и каждым скрытым нейроном. Такая система связей позволяет применить при обучении сети метод градиентного спуска с контрастивной дивергенцией .
Ограниченная машина Больцмана базируется на бинарных элементах с распределением Бернулли , составляющие видимый и скрытый слои сети. Связи между слоями задаются с помощью матрицы весов (размера m × n ), а также смещений для видимого слоя и для скрытого слоя.
Вводится понятие энергии сети ( v , h ) как
или в матричной форме
Подобной функцией энергии обладает также Сеть Хопфилда . Как и для обычной машины Больцмана , через энергию определяется вероятность распределения на векторах видимого и скрытого слоя :
где — статсумма , определяемая как для всех возможных сетей (иными словами, — константа нормализации, которая гарантирует, что сумма всех вероятностей равна единице). Определение вероятности для отдельного входного вектора (маргинальное распределение) проводится аналогично через сумму конфигураций всевозможных скрытых слоёв :
По причине структуры сети как двудольного графа, отдельные элементы скрытого слоя независимы друг от друга и активируют видимый слой, и наоборот отдельные элементы видимого слоя независимы друг от друга и активируют скрытый слой . Для видимых элементов и для скрытых элементов условные вероятности v определяются через произведения вероятностей h :
и наоборот условные вероятности h определяются через произведение вероятностей v :
Конкретные вероятности активации для одного элемента определяются как
где — логистическая функция для активации слоя.
Видимые слои могут иметь также мультиномиальное распределение , в то время как скрытые слои распределены по Бернулли . В случае мультиномиальности вместо логистической функции используется softmax :
где K — количество дискретных значений видимых элементов. Такое представление используется в задачах тематического моделирования и в рекомендательных системах .
Ограниченная машина Больцмана представляет собой частный случай обычной машины Больцмана и марковской сети . Их графовая модель соответствует графовой модели факторного анализа .
Целью обучения является максимизация вероятности системы с заданным набором образцов (матрицы, в которой каждая строка соответствует одному образцу видимого вектора ), определяемой как произведение вероятностей
или же, что одно и то же, максимизации логарифма произведения:
Для тренировки нейронной сети используется алгоритм контрастивной дивергенции (CD) с целью нахождения оптимальных весов матрицы , его предложил Джеффри Хинтон , первоначально для обучения моделей PoE («произведение экспертных оценок») . Алгоритм использует семплирование по Гиббсу для организации процедуры градиентного спуска , аналогично методу обратного распространения ошибок для нейронных сетей.
В целом один шаг контрастивной дивергенции (CD-1) выглядит следующим образом:
Практические указания по реализации процесса обучения можно найти на личной странице Джеффри Хинтона .
|deadlink=
(
справка
)
|deadlink=
(
справка
)

















