Анализ взвешенных сетей коэкспрессии генов
(
англ.
weighted gene coexpression network analysis, WGCNA
), также известный как
анализ взвешенной сети корреляций
(
англ.
weighted correlation network analysis
) — метод
глубинного анализа данных
, основанный на попарных
корреляциях
между переменными
. Метод может быть использован для анализа широкого спектра многомерных наборов данных, но наиболее широкое распространение он получил в
геномике
. Метод позволяет определять
модули
(кластеры
коэкспрессирующихся
генов
), межмодульные хабы и узлы сети относительно принадлежности к модулю, изучать отношения между модулями коэкспрессии и сравнивать
топологии
различных сетей. WGCNA может быть использован как
метод снижения размерности
данных (связанный с непрямым
факторным анализом
), как метод
кластеризации
, как метод
отбора признаков
(например, для скрининга генов)
.
Содержание
История
Метод WGCNA был разработан
, профессором
Калифорнийского университета в Лос-Анджелесе
и членами его лаборатории (в частности, Питером Лангфелдером, Бином Чжаноми и Джуном Донгом) и опубликован в 2005 году. Большая часть метода появилась в ходе прикладных исследований. В частности, взвешенные корреляционные сети были разработаны в рамках совместных дискуссий с исследователями
рака
Полом Мишелем, Стэнли Ф. Нельсоном, и
нейробиологами
Дэниэлем Гешвиндом и Майклом Олдхэмом
. В 2008 году была опубликована программная реализация алгоритма
.
Алгоритм работы
Построение первичной сети
Исходные данные представляют собой матрицу экспрессии генов в нескольких образцах
, где
— число генов,
— число образцов. Для построения сети коэкспрессии для каждой пары генов
вычисляется параметр сходства,
, который должен лежать в
.
по умолчанию равен абсолютному значению
коэффициента корреляции Пирсона
:
,
где профили коэкспрессии генов
и
состоят из экспрессии генов i и j среди множества образцов. Для достижения большей устойчивости к выбросам можно использовать
«урезанный» коэффициент корреляции
, а для того, чтобы сохранить знак коэффициента можно использовать простое преобразование корреляции:
, так как использование абсолютного значения корреляции может привести к потере биологически значимой информации, поскольку при этом нельзя различить репрессию и активацию генов. Получается матрица сходства
.
Фильтрация рёбер по весу с применением мягкого безмасштабного критерия
Для вычисления
матрицы смежности
сети по матрице сходства необходима функция смежности, которая отображает интервал
в интервал
. Традиционной функцией смежности является
сигнум-функция
с жёстким порогом:
Такая жёсткая фильтрация рёбер применяется при построении невзвешенных сетей, а результат согласован с интуитивным пониманием концепции сети (связность узла совпадает с числом связанных с ним соседей). Однако такой подход часто приводит к потере информации: например, если установить
, то между узлами с параметром сходства 0.79 не будет никакой связи. Таким образом такие сети очень чувствительны к выбору гиперпараметра
.
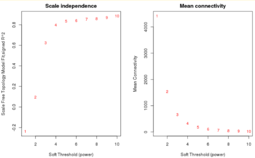
Анализ параметров топологии сети для различных значений параметра β. Рисунок слева отражает зависимость индекса безмасштабности сети от целочисленных значений β, правый рисунок — среднюю связанность сети от целочисленных значений β
Взвешенные сети лишены этого недостатка. В алгоритме WGCNA в качестве функции смежности используется
степенная функция
:
Значение
определяется с помощью топологического критерия
безмасштабности сети
для целочисленных значений
. Для разных целочисленных значений
строится
линейная модель
зависимости логарифма доли вершин сети со
степенью
от логарифма степени
. Выбирается наименьшее значение
, при котором
коэффициент детерминации
соответствующей линейной модели превосходит 0.8
.
«Мягкая» матрица смежности позволяет лишь проранжировать узлы сети согласно силе их связи с рассматриваемым узлом. Если необходимо определить ограниченный список соседей, вводится порог по силе связи. Такой способ «мягкой» фильтрации рёбер сети и называется взвешиванием сети
.
Сглаживание взвешенной сети
Для определения модулей сети и удаления шума производится операция сглаживания сети. Сначала вычисляется матрица топологического сходства (
topological overlap measure
)
:
,
где
— элемент матрицы смежности,
,
.
равна
, если узел
с меньшим числом соседей связан с узлом
с бо́льшим числом соседей и все соседи узла
являются соседями узла
.
равна
, если узлы
и
не связаны и не имеют общих соседей. Так как
, то и
. Топологическое сходство двух узлов отражает их относительную внутрисвязанность
.
На основе матрицы топологического сходства строится матрица несходства
:
.
Модули сети выделяются согласно матрице несходства
.
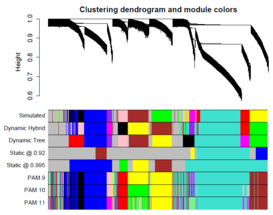
Пример выделения модулей в дендрограмме на симулированных данных разными подходами
Иерархическая кластеризация и выделение модулей
Для выделения модулей сети используется
иерархическая кластеризация
матрицы несходства
. Модули генов представляют собой ветви полученной
дендрограммы
. Для выделения модулей производится обрезка ветвей дендрограммы. Статический способ обрезки, который выделяет разветвления ниже определённого порога как отдельный кластер, производит модули, которые легко выделяются визуально, но не соответствуют строгому определению понятия «модуль»
.
В WGCNA используется метод динамического обрезания дендрограммы (
англ.
Dynamic Tree Cut
)
, который представляет собой адаптивный итеративный процесс разбиения и комбинации модулей, и останавливается, когда число модулей остаётся стабильным. Исходным набором модулей являются большие модули, определяемые статическим способом. Далее происходит рекурсивное разбиение на подмодули на основе наличия паттерна флуктуаций длины ветвей внутри одного исходного модуля. Маленькие модули объединяются с соседними, чтобы избежать чрезмерного дробления
.
Более поздние версии алгоритма используют гибридный динамический (
англ.
Dynamic Hybrid
) подход, который позволяет более успешно детектировать выбросы в каждом кластере
. В качестве зачатков модулей используются ветви, удовлетворяющие следующим критериям:
Содержат не менее установленного порога дочерних листьев (объектов);
Объекты, расположенные слишком далеко от модуля исключаются из него, даже если они принадлежат одной дочерней ветви на дендрограмме;
Каждый модуль должен быть различимым от его окружения;
После определения таких зачаточных модулей все остальные объекты, не попавшие в модулей на первом шаге, по возможности включаются в состав образованных модулей методом
. Объекты в составе одного итогового модуля могут не находиться рядом на дендрограмме, однако эта несогласованность является обманчивой и следует из ограничений отображения реальных данных в виде дендрограммы
.
Пример бутстрэп-анализа сети коэкспрессии генов методом WGCNA
Валидация модулей
Для валидации модулей используется
бутстрэп-анализ
на неполных выборках образцов
. Дальнейшему анализу подвергаются только те модули, которые были обнаружены в большом числе бутстрэп-реплик
.
Интерпретация результатов
Обобщение профиля экспрессии генов модуля
Модуль коэкспрессии
представляется собственным геном (
англ.
eigengene
)
, который является правым сингулярным вектором, соответствующим наибольшему правому сингулярному значению при
сингулярном разложении
матрицы экспрессии генов этого модуля
.
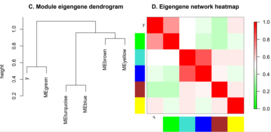
Тепловая карта корреляции собственных генов модулей коэкспрессии и биологических черт на примере данных экспрессии генов в клетках печени самок мышей
Соотнесение модулей с внешними характеристиками
Для определения значимости влияния экспрессии одного гена
на проявление черты
можно использовать модуль коэффициента корреляции
или
p-value
соответствующего
корреляционного
или
регрессионного
анализа
. Для определения значимости влияния экспрессии генов модуля
используются разные величины:
Среднее значение модулей коэффициентов корреляции между экспрессиями генов и проявления черты по данному модулю
;
Модуль коэффициента корреляции собственного гена и проявления черты
и соответствующий p-value
регрессионного анализа.
Чем больше величина значимости, тем более значимым является данный ген
или модуль генов
для проявления данной черты
.
Анализ сети собственных генов модулей, выделенных WGCNA. Слева: иерархическая кластеризация несхожести собственных генов, справа: тепловая карта матрицы смежности, построенной на основании коэффициентов корреляции собственных генов
Взаимодействие модулей
Для оценки взаимодействия (коэкспрессии) модулей используются как попарные корреляции между собственными генами модулей, так и построение мета-сети на основе матрицы коэкспрессии собственных генов модулей и выделение мета-модулей в этой мета-сети, в том числе с использованием информации о проявлении черт для определения значимости модулей
.
Выделение важных генов
Одним из ключевых моментов в анализе построенной сети является выделение
центральных
узлов (хабов) — генов, которые высоко скоррелированы со многими другими генами сети. Две метрики связности узла: стандартная
и топологическая
— могут быть вычислены как по всей сети (полносетевая связность,
англ.
whole-network connectivity
), так и только по генам того же модуля (внутримодальная связность,
англ.
intramodular connectivity
). Стандартная и топологическая полносетевая и внутримодальная связности обозначаются как
,
,
и
, соответственно.
Использование внутримодульной связности (нормированной на максимальное значение связности внутри модуля) является более предпочтительным по сравнению с полносетевой связностью при сравнении генов из различных модулей, так как сильно связный ген но из маленького по размеру, но важного модуля может иметь гораздо меньшее значение полносетевой связности по сравнению с геном, имеющим среднюю степень связности из большого по размеру, но не очень важного модуля.
В свою очередь, внутримодульная связность гена отражает то, насколько связан или коэкспрессирован рассматриваемый ген по отношению к генам этого модуля. Эта метрика может быть интерпретирована как мера принадлежности к модулю.
Также выделяют метрики
и
. Высокое среднее значение
для генов модуля (даже превышающее среднее значение
) может означать то, что этот модуль является ядром сети и важным с биологической точки зрения в изучаемых условиях. Высокое значение
, напротив, означает, что общая связанность больше, чем связанность внутри модуля, то есть гены, входящие в состав этого модуля, стабильны и слабо меняют экспрессию в исследуемых условиях
.
Взвешенная мера принадлежности к модулю
Бинарная мера принадлежности к модулю может быть не самой подходящей мерой для ряда применений, поэтому в качестве меры принадлежности гена к модулю можно использовать непрерывную величину (
англ.
fuzzy measure of module membership
). В качестве такой меры можно использовать
или меру связности, основанная на собственных векторах модулей,
. Последняя определяется как корреляция гена
и собственного гена модуля
:
. Высокое значение
(близкое к
или
) говорит о сильной связанности гена
и модуля
, значение, близкое к
, говорит о том, что ген
не принадлежит модулю
. Метрики
и
связаны между собой: внутримодальные хабы обладают тенденцией иметь высокое значение
для соответствующего модуля
.
Сравнение взвешенных и невзвешенных сетей корреляций
Взвешенная корреляционная сеть может рассматриваться как частный случай
взвешенной сети
, сети зависимостей или корреляционной сети
. Анализ взвешенных корреляционных сетей имеет следующие достоинства по сравнению с невзвешенными сетями:
Построение сети (на основе мягкого порога коэффициента корреляции) сохраняет непрерывный характер исходной информации о корреляции. Например, взвешенные корреляционные сети, построенные на основе корреляций между числовыми переменными не требуют выбора жёсткого порога. Дихотомическое деление информации и (жёсткий) выбор порога может привести к потере информации
;
Взвешенные корреляционные сети облегчают геометрическую интерпретацию на основе угловой интерпретации корреляции
;
Полученная статистика сети может быть использована для улучшения результатов стандартных методов глубокого анализа данных, таких как кластерный анализ, так как меры несхожести зачастую могут быть преобразованы во взвешенные сети
;
WGCNA предоставляет обширные статистические данные о консервативности модулей, которые могут быть использованы для количественного представления возможности встретить их в другом состоянии. Также статистика консервативности модулей позволяет исследовать различия между модульной структурой сетей
;
Взвешенные и корреляционные сети часто можно аппроксимировать
факторизуемыми сетями
. Таких приближений бывает сложно добиться для разреженных, невзвешенных сетей. Таким образом, взвешенные (корреляционные) сети позволяют использовать экономную параметризацию (в терминах модулей и принадлежности к модулям)
.
Применение
WGCNA широко применяется для анализа данных об экспрессии генов, например, для поиска межмодульных хабов
.
Эта методика часто используется в качестве шага снижения размерности данных в применении к системной генетике, где модули представлены собственными генами
. Собственные гены модулей могут быть использованы для расчёта корреляции с экспериментальными данными
.
WGCNA можно применять для
метаанализа
данных, полученных из разных источников
.
Программная реализация алгоритма
Пакет программного обеспечения R
Пакет WGCNA
программного обеспечения R
предоставляет функции для осуществления всех элементов анализа взвешенных сетей (построение модулей, выбор генов хабов, статистика консервативности модулей, дифференциальный анализ сети, статистика сети). Пакет WGCNA доступен в
CRAN
, стандартном
репозитории
пакетов дополнений для R, однако для работы WGCNA необходимы пакеты, доступные в репозитории
Bioconductor
. Пакету посвящён отдельный сайт, где опубликованы краткие руководства с демонстрацией возможностей пакета
, а также существует блог одного из авторов метода, в котором публикуются тематические статьи, руководства и новости пакета
.
Экспорт результатов для анализа в дочерних программах
Пакет содержит функции для визуализации полученных сетей в VisANT и
Cytoscape
. Также разработан пакет anRichment для расширенной функциональной аннотации генов в модулях, выделенных WGCNA
.
iterativeWGCNA
Существует расширение базового пакета R под названием iterativeWGCNA, реализованное на языке
Python
. Расширение позволяет усилить устойчивость детектируемых модулей и уменьшить потерю информации. Для этого гены, не попавшие в модули, а также гены со слабым значением связности к своим модулям снова подвергаются WGCNA-анализу и для них заново определяются модули
.
Анализ полногеномных данных
Анализ сетей коэкспрессии для наборов данных с большим числом образцов в полногеномном масштабе является вычислительно сложной задачей, требующей большого количества оперативной памяти и времени вычисления. Из-за того, что в процессе построения сети вычисляется коэффициент корреляции между узлами, то анализ сети с
узлами требует
оперативной памяти и
времени вычислений
. Существует две стратегии для решения этой проблемы
.
Анализ ограниченного набора генов
Можно сократить число анализируемых генов до 4000-5000, которые имеют наибольшее значение какого-либо параметра: значение дисперсии профиля экспрессии генов в массиве данных
, значение p-value теста уровня экспрессии генов между различными группами образцов
, доля образцов, в которых детектируется экспрессия генов
и другие. Основными недостатками такого подхода являются потеря информации об оставшихся генах, систематическая
и неверное распределение генов по функциям
.
Эвристические методы определения модулей
Один подход состоит в том, что сначала выделяются модули на некой подвыборке генов, а затем оставшиеся гены добавляются к выделенным модулям на основании метрики
: для каждого гена вычисляется, с каким из модулей он сильнее всего коррелирует. Но если данный ген не коррелирует ни с каким модулем выше заданного порога, то он не включается ни в один модуль
.
Другой подход состоит в том, что на начальном этапе гены разбиваются на блоки заранее заданного размера с помощью метода
k-ближайших соседей
, а дальнейшее выделение модулей производится уже внутри этих блоков. Полученные модули сливаются и соотносятся между собой согласно корреляции их собственных генов. Такой подход реализован в пакете WGCNA и для блоков размера
требует
оперативной памяти и
вычислений
.
Примечания
↑
Peter Langfelder, Steve Horvath.
// BMC bioinformatics. — 2008-12-29. —
Т. 9
. —
С. 559
. —
ISSN
. —
doi
:
.
28 апреля 2020 года.
↑
Zhang B., Horvath S.
(англ.)
// Statistical Applications in Genetics and Molecular Biology. — 2005-08-12. —
Vol. 4
,
iss. 1
. —
doi
:
.
28 сентября 2020 года.
↑
Steve Horvath.
. — New York: Springer-Verlag, 2011. —
ISBN 978-1-4419-8818-8
.
18 сентября 2020 года.
↑
Langfelder P., Zhang B., Horvath S.
(англ.)
// Bioinformatics. — 2007-11-16. —
Vol. 24
,
iss. 5
. —
P. 719—720
. —
doi
:
.
11 февраля 2016 года.
Peter Langfelder.
(англ.)
. Insights from a billion correlations (31 декабря 2018). Дата обращения: 19 апреля 2020.
27 сентября 2020 года.
Peter Langfelder and Steve Horvath.
(неопр.)
.
Fast functions for correlation and hierarchical clustering
R code examples
(15 октября 2014).
↑
Horvath S., Dong J.
(англ.)
// PLoS Comput Biol. — 2008-08-15. —
Vol. 4
,
iss. 8
. —
doi
:
.
30 декабря 2014 года.
Peter Langfelder and Steve Horvath.
[
Tutorial for the WGCNA package for R:
I. Network analysis of liver expression data in female mice
3. Relating modules to external information and identifying important
genes]
(неопр.)
.
Tutorials for the WGCNA package
(25 ноября 2014). Дата обращения: 19 апреля 2020.
17 января 2021 года.
Peter Langfelder, Steve Horvath.
// BMC Systems Biology. — 2007-11-21. —
Т. 1
,
вып. 1
. —
ISSN
. —
doi
:
.
Peter Langfelder, Rui Luo, Michael C. Oldham, Steve Horvath.
// PLoS Computational Biology. — 2011-01-20. —
Т. 7
,
вып. 1
. —
С. e1001057
. —
ISSN
. —
doi
:
.
↑
John Michael Ranola, Peter Langfelder, Kenneth Lange, Steve Horvath.
// BMC Systems Biology. — 2013-03-14. —
Т. 7
,
вып. 1
. —
С. 21
. —
ISSN
. —
doi
:
.
Peter Langfelder, Paul S. Mischel, Steve Horvath.
(англ.)
// PLOS ONE. — 2013-04-17. —
Vol. 8
,
iss. 4
. —
P. e61505
. —
ISSN
. —
doi
:
.
23 марта 2022 года.
S. Horvath, B. Zhang, M. Carlson, K. V. Lu, S. Zhu.
// Proceedings of the National Academy of Sciences. — 2006-11-07. —
Т. 103
,
вып. 46
. —
С. 17402–17407
. —
ISSN
. —
doi
:
.
Yanqing Chen, Jun Zhu, Pek Yee Lum, Xia Yang, Shirly Pinto.
(англ.)
// Nature. — 2008-03. —
Vol. 452
,
iss. 7186
. —
P. 429–435
. —
ISSN
. —
doi
:
.
25 мая 2021 года.
Christopher L. Plaisier, Steve Horvath, Adriana Huertas-Vazquez, Ivette Cruz-Bautista, Miguel F. Herrera.
(англ.)
// PLOS Genetics. — 2009-11-09. —
Vol. 5
,
iss. 9
. —
P. e1000642
. —
ISSN
. —
doi
:
.
23 апреля 2022 года.
Irina Voineagu, Xinchen Wang, Patrick Johnston, Jennifer K. Lowe, Yuan Tian.
(англ.)
// Nature. — 2011-06. —
Vol. 474
,
iss. 7351
. —
P. 380–384
. —
ISSN
. —
doi
:
.
6 сентября 2019 года.
Michael J. Hawrylycz, Ed S. Lein, Angela L. Guillozet-Bongaarts, Elaine H. Shen, Lydia Ng.
(англ.)
// Nature. — 2012-09. —
Vol. 489
,
iss. 7416
. —
P. 391–399
. —
ISSN
. —
doi
:
.
11 декабря 2019 года.
Haja N. Kadarmideen, Nathan S. Watson-Haigh, Nicholas M. Andronicos.
(англ.)
// Molecular BioSystems. — 2011-01-01. —
Vol. 7
,
iss. 1
. —
P. 235–246
. —
ISSN
. —
doi
:
.
15 апреля 2019 года.
Lisette J. A. Kogelman, Susanna Cirera, Daria V. Zhernakova, Merete Fredholm, Lude Franke.
// BMC Medical Genomics. — 2014-09-30. —
Т. 7
,
вып. 1
. —
С. 57
. —
ISSN
. —
doi
:
.
Zhigang Xue, Kevin Huang, Chaochao Cai, Lingbo Cai, Chun-yan Jiang.
(англ.)
// Nature. — 2013-08. —
Vol. 500
,
iss. 7464
. —
P. 593–597
. —
ISSN
. —
doi
:
.
2 декабря 2019 года.
Steve Horvath, Yafeng Zhang, Peter Langfelder, René S. Kahn, Marco PM Boks.
// Genome Biology. — 2012-10-03. —
Т. 13
,
вып. 10
. —
С. R97
. —
ISSN
. —
doi
:
.
Dyna I. Shirasaki, Erin R. Greiner, Ismael Al-Ramahi, Michelle Gray, Pinmanee Boontheung.
// Neuron. — 2012-07-12. —
Т. 75
,
вып. 1
. —
С. 41–57
. —
ISSN
. —
doi
:
.
18 декабря 2012 года.
Maomeng Tong, Xiaoxiao Li, Laura Wegener Parfrey, Bennett Roth, Andrew Ippoliti.
// PLoS ONE. — 2013-11-19. —
Т. 8
,
вып. 11
. —
ISSN
. —
doi
:
.
Jeanette A Mumford, Steve Horvath, Michael C. Oldham, Peter Langfelder, Daniel H. Geschwind.
// NeuroImage. — 2010-10-01. —
Т. 52
,
вып. 4
. —
С. 1465–1476
. —
ISSN
. —
doi
:
.
A. E. Ivliev, P. A. C. 't Hoen, M. G. Sergeeva.
(англ.)
// Cancer Research. — 2010-12-15. —
Vol. 70
,
iss. 24
. —
P. 10060–10070
. —
ISSN
. —
doi
:
.
Alexander E. Ivliev, Peter A. C. 't Hoen, Willeke M. C. van Roon-Mom, Dorien J. M. Peters, Marina G. Sergeeva.
(англ.)
// PLOS ONE. — 2012-04-25. —
Vol. 7
,
iss. 4
. —
P. e35618
. —
ISSN
. —
doi
:
.
17 апреля 2022 года.
Jeremy A. Miller, Steve Horvath, Daniel H. Geschwind.
(англ.)
// Proceedings of the National Academy of Sciences. — 2010-07-13. —
Vol. 107
,
iss. 28
. —
P. 12698–12703
. —
ISSN
. —
doi
:
.
(неопр.)
horvath.genetics.ucla.edu. Дата обращения: 19 апреля 2020.
22 июля 2020 года.
↑
(неопр.)
. horvath.genetics.ucla.edu. Дата обращения: 21 апреля 2020.
23 октября 2020 года.
(англ.)
. Insights from a billion correlations. Дата обращения: 21 апреля 2020.
10 августа 2020 года.
Peter Langfelder and Steve Horvath.
[
Tutorial for the WGCNA package for R:
I. Network analysis of liver expression data in female mice
6. Exporting a gene network to external visualization software]
(неопр.)
.
Tutorials for the WGCNA package
(25 ноября 2014).
Peter Langfelder.
(англ.)
. Insights from a billion correlations (25 ноября 2018). Дата обращения: 21 апреля 2020.
4 августа 2020 года.
Emily Greenfest-Allen, Jean-Philippe Cartailler, Mark A. Magnuson, Christian J. Stoeckert.
(англ.)
// bioRxiv. — 2017-12-14. —
P. 234062
. —
doi
:
.
9 апреля 2019 года.
↑
Ивлиев, Александр Евгеньевич.
Анализ генных сетей коэкспрессии для изучения транскриптома опухолей мозга и предсказания функций генов
(рус.)
// Место защиты: Ин-т проблем передачи информации им. А.А. Харкевича РАН : диссертация ... кандидата биологических наук : 03.01.09. — 2011.
Angela P. Presson, Eric M. Sobel, Jeanette C. Papp, Charlyn J. Suarez, Toni Whistler.
(англ.)
// BMC Systems Biology. — 2008-11-06. —
Vol. 2
,
iss. 1
. —
P. 95
. —
ISSN
. —
doi
:
.
Anastasia Murat, Eugenia Migliavacca, Thierry Gorlia, Wanyu L. Lambiv, Tal Shay.
(англ.)
// Journal of Clinical Oncology. — 2008-06-20. —
Т. 26
,
вып. 18
. —
С. 3015–24
. —
ISSN
. —
doi
:
.
4 августа 2020 года.
↑
Xia Yang, Eric E. Schadt, Susanna Wang, Hui Wang, Arthur P. Arnold.
(англ.)
// Genome Research. — 2006-08-01. —
Vol. 16
,
iss. 8
. —
P. 995–1004
. —
ISSN
. —
doi
:
.
18 ноября 2019 года.
![{\displaystyle X_{n\times m}=[x_{il}]}](/images/004/916/4916897/2.jpg?rand=424854)




![[0;1]](/images/004/916/4916897/7.jpg?rand=789110)





![{\displaystyle S_{n\times n}=[s_{ij}]}](/images/004/916/4916897/13.jpg?rand=151339)
![{\displaystyle A_{n\times n}=[a_{ij}]}](/images/004/916/4916897/14.jpg?rand=531777)
![[0;1]](/images/004/916/4916897/15.jpg?rand=724338)
![[0;1]](/images/004/916/4916897/16.jpg?rand=202839)











![{\displaystyle \Omega _{n\times n}=[\omega _{ij}]}](/images/004/916/4916897/29.jpg?rand=559208)
















![{\displaystyle D_{n\times n}=[d_{ij}^{\omega }]}](/images/004/916/4916897/46.jpg?rand=506567)



![{\displaystyle X_{n^{(q)}\times m}^{(q)}=[x_{ij}^{(q)}]}](/images/004/916/4916897/52.jpg?rand=569812)