UTF-16
- 1 year ago
- 0
- 0

UTF-8 (от англ. Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования символов , позволяющий более компактно хранить и передавать символы Юникода , используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII . Стандарт UTF-8 официально закреплён в документах и ISO/IEC 10646 Annex D.
Кодировка UTF-8 сейчас является доминирующей в веб-пространстве. Она также нашла широкое применение в UNIX-подобных операционных системах .
Формат UTF-8 был разработан 2 сентября 1992 года Кеном Томпсоном и Робом Пайком , и реализован в Plan 9 . Идентификатор кодировки в Windows — 65001 .
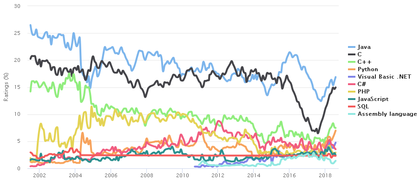
UTF-8, по сравнению с UTF-16 , наибольший выигрыш в компактности даёт для текстов на латинице , поскольку латинские буквы без диакритических знаков , цифры и наиболее распространённые знаки препинания кодируются в UTF-8 лишь одним байтом, и коды этих символов соответствуют их кодам в ASCII .
Алгоритм кодирования в UTF-8 стандартизирован в RFC 3629 и состоит из 3 этапов:
1. Определить количество октетов ( байтов ), требуемых для кодирования символа. Номер символа берётся из стандарта Юникода.
| Диапазон номеров символов | Требуемое количество октетов |
|---|---|
00000000-0000007F
|
1 |
00000080-000007FF
|
2 |
00000800-0000FFFF
|
3 |
00010000-0010FFFF
|
4 |
Для символов Юникода с номерами от
U+0000
до
U+007F
(занимающими один байт c нулём в старшем бите) кодировка UTF-8 полностью соответствует 7-битной кодировке US-ASCII.
2. Установить старшие биты первого октета в соответствии с необходимым количеством октетов, определённом на первом этапе:
Если для кодирования требуется больше одного октета, то в октетах 2-4 два старших бита всегда устанавливаются равными 10 2 (10xxxxxx). Это позволяет легко отличать первый октет в потоке, потому что его старшие биты никогда не равны 10 2 .
| Количество октетов | Значащих бит | Шаблон |
|---|---|---|
| 1 | 7 |
0xxxxxxx
|
| 2 | 11 |
110xxxxx 10xxxxxx
|
| 3 | 16 |
1110xxxx 10xxxxxx 10xxxxxx
|
| 4 | 21 |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
|
3. Установить значащие биты октетов в соответствии с номером символа Юникода , выраженном в двоичном виде. Начать заполнение с младших битов номера символа, поставив их в младшие биты последнего октета, продолжить справа налево до первого октета. Свободные биты первого октета, оставшиеся незадействованными, заполнить нулями.
| Символ | Двоичный код символа | UTF-8 в двоичном виде | UTF-8 в шестнадцатеричном виде | |
|---|---|---|---|---|
| $ |
U+0024
|
0100100
|
0
0100100
|
24
|
| ¢ |
U+00A2
|
10
100010
|
110
00010
10
100010
|
C2
A2
|
| € |
U+20AC
|
10
0000
10
101100
|
1110
0010
10
000010
10
101100
|
E2
82
AC
|
| 𐍈 |
U+10348
|
1 0000
0011 01
001000
|
11110
000
10
010000
10
001101
10
001000
|
F0
90
8D
88
|
Для указания, что файл или поток содержит символы Юникода, в начале файла или потока может быть вставлен
маркер последовательности байтов
(
англ.
Byte order mark, BOM
), который в случае кодирования в UTF-8 принимает форму трёх байтов:
EF BB BF
16
.
| 1-й байт | 2-й байт | 3-й байт | |
|---|---|---|---|
| Двоичный код |
1110 1111
|
1011 1011
|
1011 1111
|
| Шестнадцатеричный код |
EF
|
BB
|
BF
|
Изначально кодировка UTF-8 допускала использование до шести байтов для кодирования одного символа, однако в ноябре 2003 года стандарт
запретил использование пятого и шестого байтов, а диапазон кодируемых символов был ограничен символом
U+10FFFF
. Это было сделано для обеспечения совместимости с UTF-16.
Не всякая последовательность байтов является допустимой. Декодер UTF-8 должен понимать и адекватно обрабатывать такие ошибки:
|
Исторические
кодировки |
|
|---|---|
|
современное
8-битное представление |
|
| Многобайтные | |
|
Форматы
cериализационных
цифровых данных
|
|
|---|---|
| Текстовые | |
| Интернет и телекоммуникации | |
| Медиа | |
| Другие | |