Interested Article - Лексический анализ
- 2021-02-27
- 1
В информатике лексический анализ («токенизация», от англ. tokenizing ) — процесс аналитического входной последовательности символов на распознанные группы — лексемы — с целью получения на выходе идентифицированных последовательностей, называемых « токенами » (подобно группировке букв в словах ).
Смысл
В простых случаях понятия «лексема» и «токен» идентичны, но более сложные токенизаторы дополнительно классифицируют лексемы по различным типам («идентификатор», «оператор», «часть речи» и т. п.). Лексический анализ используется в компиляторах и интерпретаторах исходного кода языков программирования , и в различных парсерах слов естественных языков .
Как правило, лексический анализ производится с точки зрения определённого формального языка или набора языков. Язык, а точнее, его грамматика , задаёт определённый набор лексем, которые могут встретиться на входе процесса.
Традиционно принято организовывать процесс лексического анализа, рассматривая входную последовательность символов как поток символов. При такой организации процесс самостоятельно управляет выборкой отдельных символов из входного потока.
Распознавание лексем в контексте грамматики обычно производится путём их идентификации (или классификации) согласно идентификаторам (или классам) токенов, определяемых грамматикой языка. При этом любая последовательность символов входного потока (лексема), которая согласно грамматике не может быть идентифицирована как токен языка, обычно рассматривается как специальный токен-ошибка.
Каждый токен можно представить в виде структуры, содержащей идентификатор токена (или идентификатор класса токена) и, если нужно, последовательность символов лексемы , выделенной из входного потока (строку, число и т. д.).
Цель такой конвертации обычно состоит в том, чтобы подготовить входную последовательность для другой программы, например для грамматического анализатора , и избавить его от определения лексических подробностей в контекстно-свободной грамматике (что привело бы к усложнению грамматики).
Пример
Для примера, исходный код следующей строки программы
net_worth_future = (assets — liabilities);
может быть преобразован в следующий поток токенов:
ИМЯ "net_worth_future" ПРИСВАИВАНИЕ ОТКРЫВАЮЩАЯ_СКОБКА ИМЯ "assets" МИНУС ИМЯ "liabilities" ЗАКРЫВАЮЩАЯ_СКОБКА ТОЧКА_С_ЗАПЯТОЙ
Лексический анализатор

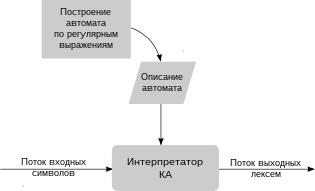
Лексический анализатор ( англ. lexical analyzer , lexer ; или «токенизатор» от tokenizer ) — это программа или часть программы, выполняющая лексический анализ. Лексический анализатор обычно работает в две стадии: сканирование и оценка .
На первой стадии, сканировании, лексический анализатор обычно реализуется в виде конечного автомата , определяемого регулярными выражениями . В нём кодируется информация о возможных последовательностях символов, которые могут встречаться в токенах. Например, токен «целое число» может содержать любую последовательность десятичных цифр. Во многих случаях первый непробельный символ может использоваться для определения типа следующего токена, после чего входные символы обрабатываются один за другим, пока не встретится символ, не входящий во множество допустимых символов для данного токена. В некоторых языках правила разбора лексем несколько более сложные и требуют возвратов назад по читаемой последовательности.
Полученный таким образом токен содержит необработанный исходный текст (строку). Для того, чтобы получить токен со значением, соответствующим типу (напр. целое или дробное число), выполняется оценка этой строки — проход по символам и вычисление значения.
Токен с типом и соответственно подготовленным значением передаётся на вход синтаксического анализатора .
Генераторы лексических анализаторов
- lex — стандартный генератор в Unix
- Flex — альтернативный вариант классической утилиты lex
- re2c — генерирует оптимизированные нетабличные лексеры, ориентирован на работу с Си, C++, Go, Rust
- — генератор на Java
- ANTLR
См. также
Литература
- Альфред В. Ахо , Моника С. Лам , , Джеффри Д. Ульман . Компиляторы: принципы, технологии и инструментарий = Compilers: Principles, Techniques, and Tools. — 2-е изд. — М. : , 2008. — ISBN 978-5-8459-1349-4 .
- . Основные концепции компиляторов = The Essence of Compilers. — М. : , 2002. — С. 256. — ISBN 5-8459-0360-2 .
Ссылки
- Козиев И. , из документации к системе парсинга естественных языков « »
- 2021-02-27
- 1




