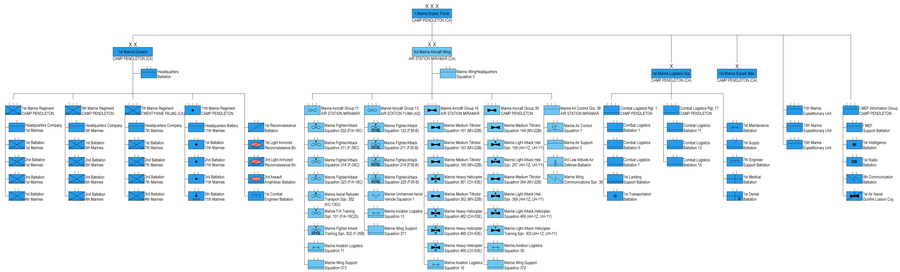
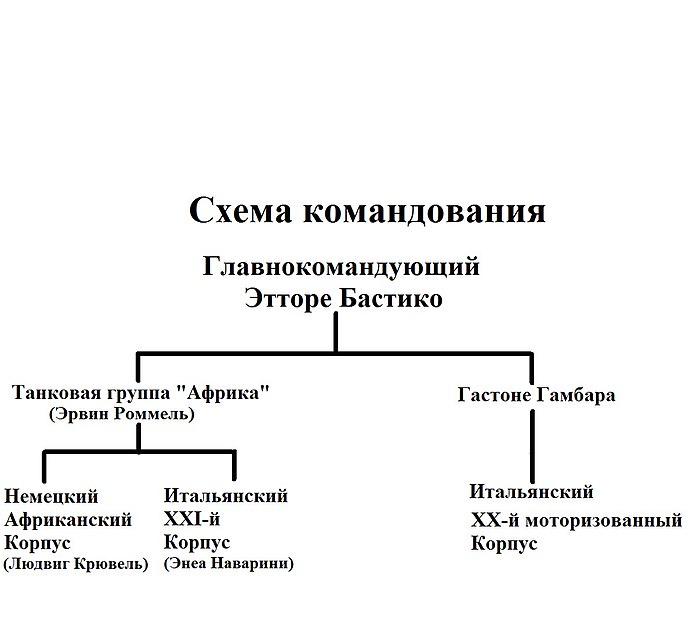
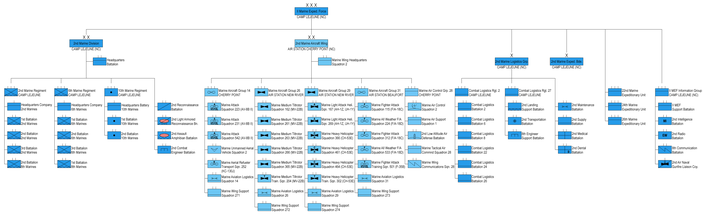
Второй корпус Потомакской армии
- 1 year ago
- 0
- 0
В лингвистике кóрпус (множественное число — кóрпусы ) — подобранная и обработанная по определённым правилам совокупность текстов, используемых в качестве базы для исследования языка. Они используются для статистического анализа и проверки статистических гипотез , подтверждения лингвистических правил в данном языке. Корпус текстов является предметом исследования корпусной лингвистики .
Среди множества определений корпуса можно выделить его главные свойства :

Классифицировать корпусы можно по различным признакам: цель создания корпуса, тип языковых данных, «литературность», жанр, динамичность, тип разметки, объём текстов и так далее. По критерию параллельности , например, корпусы можно разделить на одноязычные, двуязычные и многоязычные. Многоязычные и двуязычные делятся на два типа:
Разметка заключается в приписывании текстам и их компонентам специальных тегов : лингвистических и внешних (экстралингвистических). Выделяют следующие лингвистические типы разметки: морфологическая, семантическая, синтаксическая, анафорическая, просодическая, дискурсная и т. д. К некоторым корпусам применяются дальнейшие структурные уровни анализа. В частности, некоторые небольшие корпусы могут быть полностью синтаксически размечены. Такие корпусы обычно называют глубоко аннотированными или синтаксическими , а сама синтаксическая структура при этом является деревом зависимостей .
Ручная разметка (аннотирование) текстов — дорогостоящая и трудоемкая задача. На данный момент в открытом доступе представлены различные программные средства для разметки корпусов . Условно их можно разделить на обособленные (stand-alone) и веб-ориентированные (web-based) . При этом акцент разработчиков в последние годы сместился в сторону веб-приложений. Данные системы обладают рядом преимуществ:
Современные технологии позволяют создавать «веб-корпусы», то есть корпусы, полученные путём обработки интернет-источников:
Веб-корпус представляет собой особый вид лингвистического корпуса, который создан путем постепенной загрузки текстов из интернета при помощи автоматизированных процедур, которые на лету определяют язык и кодировку отдельных веб страниц, удаляют шаблоны, элементы навигации, ссылки и рекламу (т. н. boilerplate), осуществляют трансформацию на текст, фильтрацию, нормализацию и дедупликацию полученных документов, которые затем можно обработать традиционными инструментами корпусной лингвистики (токенизация, мирфосинтаксическая и синтаксическая аннотация) и внедрить в поисковую корпусную систему. Создание веб-корпуса не только намного дешевле, но прежде всего его размер может быть даже на порядок больше традиционных корпусов .
— Владимѝр Бенко ARANEA — СЕМЕЙСТВО МИЛЛИАРДНЫХ ВЕБ-КОРПУСОВ
Корпус — основное понятие и база данных корпусной лингвистики. Анализ и обработка разных типов корпусов являются предметом большинства работ в области компьютерной лингвистики (например, извлечение ключевых слов ), распознавания речи и машинного перевода , в которых корпусы часто применяются при создании скрытых марковских моделей для маркирования частей речи и других задач. Корпусы и частотные словари могут быть полезны в обучении иностранным языкам.
| Общие определения | |
|---|---|
| Анализ текста | |
| Реферирование |
|
| Машинный перевод | |
|
Идентификация
и сбор данных |
|
| Тематическая модель | |