
Машинный перевод на основе трансформации
- 1 year ago
- 0
- 0
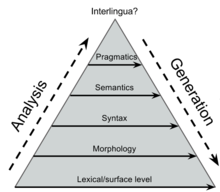

Статистический машинный перевод ( англ. Statistical machine translation — SMT) — разновидность машинного перевода, где перевод генерируется на основе статистических моделей, параметры которых являются производными от анализа двуязычных корпусов текста (text corpora).
Статистический машинный перевод противопоставляют системам машинного перевода, основанным на правилах Rule-Based Machine Translation (RBMT) и на примерах Example-Based MT (EBMT).
Первые идеи статистического машинного перевода были опубликованы Уорреном Уивером (Warren Weaver), в 1949 году. «Вторая волна» — начало 1990-х, IBM . «Третья волна» — Google, Microsoft, Language Weaver, Яндекс .
Разработчики систем машинного перевода для улучшения качества вводят некоторые «сквозные» правила, тем самым превращая чисто статистические системы в Гибридный машинный перевод . Добавление некоторых правил, то есть создание гибридных систем, несколько улучшает качество переводов, особенно при недостаточном объёме входных данных, используемых при построении индекса машинного переводчика.
В качестве языковой модели в системах статистического перевода используются преимущественно различные модификации n-граммной модели, утверждающей, что « грамматичность » выбора очередного слова при формировании текста определяется только тем, какие (n-1) слов идут перед ним .
|
Подходы к
машинному переводу
|
|
|---|---|
| Общие определения | |
|---|---|
| Анализ текста | |
| Реферирование |
|
| Машинный перевод | |
|
Идентификация
и сбор данных |
|
| Тематическая модель | |
|
|
Это
заготовка статьи
об
информационных технологиях
и
вычислительной технике
. Помогите Википедии, дополнив её.
|














