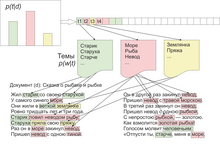
Построение тематической модели документа: :
— матрица искомых условных распределений слов по темам :
матрица искомых условных распределений тем по документам :
— документ :
— слово :
— наблюдаемые переменные :
— тема (скрытая переменная)
Тематическое моделирование
— способ построения модели коллекции текстовых документов, которая определяет, к каким темам относится каждый из документов
.
Тематическая модель
(
англ.
topic model
) коллекции текстовых документов определяет, к каким темам относится каждый документ и какие слова (термины) образуют каждую тему
.
Переход из пространства терминов в пространство найденных тематик помогает разрешать синонимию и полисемию терминов, а также эффективнее решать такие задачи, как тематический
поиск
,
классификация
,
суммаризация
и аннотация коллекций документов и новостных потоков.
Тематическое моделирование как вид статистических моделей для нахождения скрытых тем, встреченных в коллекции документов, нашло своё применение в таких областях, как
машинное обучение
и
обработка естественного языка
. Исследователи используют различные тематические модели для анализа текстов, текстовых архивов документов, для анализа изменения тем в наборах документов
. Интуитивно понимая, что документ относится к определённой теме, в документах, посвящённых одной теме, можно встретить некоторые слова чаще других. Например: «собака» и «кость» встречаются чаще в документах про собак, «кошки» и «молоко» будут встречаться в документах о котятах, предлоги «и» и «в» будут встречаться в обеих тематиках. Обычно документ касается нескольких тем в разных пропорциях, таким образом, документ в котором 10 % темы составляют кошки, а 90 % темы — собаки, можно предположить, что слов про собак в 9 раз больше. Тематическое моделирование отражает эту интуицию в математической структуре, которая позволяет на основании изучения коллекции документов и исследования частотных характеристик слов в каждом документе сделать вывод, что каждый документ — это некоторый баланс тем.
Вероятностные тематические модели осуществляют «мягкую» кластеризацию, позволяя документу или термину относиться сразу к нескольким темам с различными вероятностями. Вероятностные тематические модели описывает каждую тему
дискретным распределением
на множестве терминов, каждый документ — дискретным распределением на множестве тем. Предполагается, что коллекция документов — это последовательность терминов, выбранных случайно и независимо из смеси таких распределений, и ставится задача восстановления компонентов смеси по выборке
.
Хотя тематическое моделирование традиционно описывалось и применялось в обработке естественного языка, оно нашло своё применение и в других областях, например, таких как
биоинформатика
.
Содержание
История
Первое описание тематического моделирования появилось в работе Рагавана, Пападимитриу, Томаки и Вемполы 1998 года
. Томас Хофманн в 1999 году
предложил вероятностное скрытое семантическое индексирование (PLSI). Одна из самых распространенных тематических моделей — это
латентное размещение Дирихле
(LDA), эта модель является обобщением вероятностного семантического индексирования и разработана
(
англ.
),
Эндрю Ыном
и
(
англ.
) в 2002 году
. Другие тематические модели как правило являются расширением LDA, например,
размещение патинко
улучшает LDA за счёт введения дополнительных корреляционных коэффициентов для каждого слова, которое составляет тему.
Тематические исследования
Тэмплтон сделал обзор работ по тематическому моделированию в гуманитарных науках, сгруппированных по синхронному и диахроническому подходу
. Синхронные подходы выделяют темы в некоторый момент времени, например, Джокерс с помощью тематической модели исследовал, о чём писали блогеры в День Цифровых Гуманитарных наук в 2010 году
.
Диахронические подходы, включая определение Блока и Ньюмана о временной динамике тем в Пенсильванской газете 1728—1800 года
. Грифитс и Стейверс использовали тематическое моделирование для обзоров журнала
PNAS
, определяли изменения популярности тем с 1991 по 2001 год
. Блевин создал тематическую модель дневника Марты Балладс
. Мимно использовал тематическое моделирование для анализа 24 журналов по классической филологии и археологии за 150 лет, чтобы определить изменения популярности тем и узнать, насколько сильно изменились журналы за это время
.
Алгоритмы тематического моделирования
В работе Дэвида Блея «Введение в тематическое моделирование» рассмотрен наиболее популярный алгоритм Латентное размещение Дирихле
. На практике исследователи используют одну из эвристик метода максимального правдоподобия, методы
сингулярного разложения
(SVD),
метод моментов
, алгоритм, основанный на неотрицательной матрице факторизации (NMF), вероятностные тематические модели, вероятностный латентно-семантический анализ, латентное размещение Дирихле. В работе Воронцова К. В. рассмотрены вариации основных алгоритмов тематического моделирования: робастная тематическая модель, тематические модели классификации, динамические тематические модели, иерархические тематические модели, многоязычные тематические модели, модели текста как последовательности слов, многомодальные тематические модели
.
Вероятностные тематические модели основаны на следующих предположениях
:
Порядок документов в коллекции не имеет значения
Порядок слов в документе не имеет значения, документ — мешок слов
Слова, встречающиеся часто в большинстве документов, не важны для определения тематики
Коллекцию документов можно представить как выборку пар документ-слово
,
,
Каждая тема
описывается неизвестным распределением
на множестве слов
Каждый документ
описывается неизвестным распределением
на множестве тем
Гипотеза условной независимости
Построить тематическую модель — значит, найти матрицы
и
по коллекции
В более сложных вероятностных тематических моделях некоторые из этих предположений заменяются более реалистичными.
Вероятностный латентно-семантический анализ
Вероятностный латентно-семантический анализ (PLSA).
— документ,
— слово,
— наблюдаемые переменные,
— тема (скрытая переменная),
— априорное распределение на множестве документов,
— искомые условные распределения,
— коллекция документов,
— длина документа в словах
Вероятностный латентно-семантический анализ
(PLSA) предложен Томасом Хофманном в 1999 году.
Вероятностная модель появления пары «документ-слово» может быть записана тремя эквивалентными способами:
где
— множество тем;
— неизвестное априорное распределение тем во всей коллекции;
— априорное распределение на множестве документов, эмпирическая оценка
, где
— суммарная длина всех документов;
— априорное распределение на множестве слов, эмпирическая оценка
, где
— число вхождений слова
во все документы;
Искомые условные распределения
выражаются через
по формуле Байеса:
Для идентификации параметров тематической модели по коллекции документов применяется
принцип максимума правдоподобия
, который приводит к задаче максимизации функционала
при ограничениях нормировки
где
— число вхождений слова
в документ
.
Для решения данной оптимизационной задачи обычно применяется
EM-алгоритм
.
Основные недостатки PLSA:
Число параметров растёт линейно по числу документов в коллекции, что может приводить к
переобучению
модели.
При добавлении нового документа
в коллекцию распределение
невозможно вычислить по тем же формулам, что и для остальных документов, не перестраивая всю модель заново.
Латентное размещение Дирихле
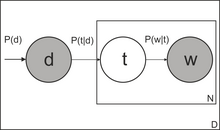
Латентное размещение Дирихле LDA. :
— слово (наблюдаемая переменная) :
— тема (скрытая переменная) :
— коллекция документов :
— длина документа в словах :
— количество тем в коллекции :
— распределение тем в документе :
— распределение слов в теме
вектора документов
порождаются одним и тем же вероятностным распределением на нормированных
-мерных векторах; это распределение удобно взять из параметрического семейства распределений Дирихле
;
вектора тем
порождаются одним и тем же вероятностным распределением на нормированных векторах размерности
; это распределение удобно взять из параметрического семейства распределений Дирихле
.
Для идентификации параметров модели LDA по коллекции документов применяется
семплирование Гиббса
, вариационный байесовский вывод или
(англ.)
(
(Expectation propagation).
См. также
Примечания
.
↑
.
.
.
.
.
.
.
.
.
.
.
.
.
, с. 229.
, с. 6.
, с. 5.
, с. 5.
К. В. Воронцов.
(рус.)
. Дата обращения: 26 октября 2013.
24 июля 2014 года.
Литература
Коршунов Антон, Гомзин Андрей.
// Труды Института системного программирования РАН : журнал. — 2012.
Марк Стейверс, Tom Griffiths.
//
/ T. Landauer, D. McNamara, S. Dennis, W. Kintsch. — Psychology Press, 2007. —
ISBN 978-0-8058-5418-3
.
от 24 июня 2013 на
Wayback Machine
Daud Ali, Li Juanzi, Zhou Lizhu, Muhammad Faqir.
// www.researchgate.net : web. — 2010.
Christos Papadimitriou, Prabhakar Raghavan, Hisao Tamaki, Santosh Vempala.
// Proceedings of ACM PODS. — 1998.
9 мая 2013 года.
Thomas Hoffman.
// Proceedings of the Twenty-Second Annual International SIGIR Conference on Research and Development in Information Retrieval. — 1999.
14 декабря 2010 года.
David M. Blei, Andrew Y. Ng, Michael I. Jordan.
// Journal of Machine Learning Research. — 2003.
1 мая 2012 года.
David Blei, J.D. Lafferty.
: web. — 2009.
31 мая 2013 года.
David Blei, J.D. Lafferty.
// Annals of Applied Statistics. — 2007. —
С. 17–35
. —
doi
:
.
15 февраля 2017 года.
David Mimno.
// Journal on Computing and Cultural Heritag : журнал. — 2012. —
doi
:
.
Matthew L. Jockers.
: web. — 2010.
E. Микс.
: web. — 2011.
C. Тэмплтон.
// Maryland Institute for Technology in the Humanities Blog : web. — 2011.
T. Гифитс, М. Стейверс.
Нахождение научных тем // Proceedings of the National Academy of Sciences : журнал. — 2004. —
doi
:
. —
.
T. Янг, A Торгет и Р. Mihalcea.
// Proceedings of the 5th ACL-HLT Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities. The Association for Computational Linguistics, Madison : журнал. — 2011. —
С. 96–104
.
27 марта 2014 года.
С. Блок.
// Common-place The Interactive Journal of Early American Life : журнал. — 2006.
Д. Ньюман, С. Блок.
// Journal of the American Society for Information Science and Technology : журнал. — 2006. —
doi
:
.