О русском крестьянстве
- 1 year ago
- 0
- 0
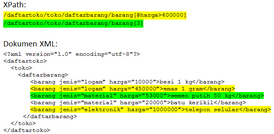
XPath (XML Path Language) — язык запросов к элементам XML -документа. Разработан для организации доступа к частям документа XML в файлах трансформации XSLT и является стандартом консорциума W3C . XPath призван реализовать навигацию по DOM в XML . В XPath используется компактный синтаксис, отличный от принятого в XML. В 2007 году завершилась разработка версии 2.0, которая теперь является составной частью языка XQuery 1.0. В декабре 2009 года началась разработка версии 2.1, которая использует XQuery 1.1.
На данный момент самой популярной версией является XPath 1.0. Это связано с отсутствием поддержки XPath 2.0 со стороны открытых библиотек. В частности, речь идёт о libxml2 , от которой зависит поддержка языка в браузерах, с одной стороны, и поддержка со стороны серверного интерпретатора, с другой.
XML имеет древовидную структуру. В самостоятельном XML-документе всегда имеется один корневой элемент (инструкция <?xml version="1.0"?> к дереву элементов отношения не имеет), в котором допустим ряд вложенных элементов, некоторые из которых тоже могут содержать вложенные элементы. Так же могут встречаться текстовые узлы, комментарии и инструкции. Можно считать, что XML-элемент содержит массив вложенных в него элементов и массив атрибутов.
У элементов дерева бывают элементы-предки и элементы-потомки (у корневого элемента предков нет, а у тупиковых элементов (листьев дерева) нет потомков). Каждый элемент дерева находится на определённом уровне вложенности (далее — «уровень»). Элементы упорядочены в порядке расположения в тексте XML, и поэтому можно говорить об их предыдущих и следующих элементах. Это очень похоже на организацию каталогов в файловой системе.
Строка XPath описывает способ выбора нужных элементов из массива элементов, которые могут содержать вложенные элементы. Начинается отбор с переданного множества элементов, на каждом шаге пути отбираются элементы, соответствующие выражению шага, и в результате оказывается отобрано подмножество элементов, соответствующих данному пути.
Для примера возьмём следующий XHTML -документ:
<html>
<body>
<div>Первый слой
<span>блок текста в первом слое</span>
</div>
<div>Второй слой</div>
<div>Третий слой
<span class="text">первый блок в третьем слое</span>
<span class="text">второй блок в третьем слое</span>
<span>третий блок в третьем слое</span>
</div>
<span>четвёртый слой</span>
<img />
</body>
</html>
XPath-путь
/html/body/*/span[@class]
будет соответствовать в нём двум элементам исходного документа —
<span class="text">первый блок в третьем слое</span>
и
<span class="text">второй блок в третьем слое</span>
.
Элементы пути преимущественно пишутся в XPath в краткой форме. Полная форма приведённого выше пути имеет вид /child::html/child::body/child::*/child::span[attribute::class]
Путь состоит из
шагов адресации,
которые разделяются символом «косая черта»
/
.
Каждый шаг адресации состоит из трёх частей:
@
) (см. ниже).
*
, который отберёт все элементы оси)
Анализ пути ведётся слева направо и начинается либо в контексте первого элемента корневого узла (в данном примере это элемент html), и тогда по оси child:: будут вложенные в него элементы (в данном примере это один элемент body), что удобно в случае обработки обычного XML-документа с одним корневым узлом, либо, если в начале XPath указан символ
/
, в контексте со всеми корневыми элементами переданого XML по оси child:: (в даном примере это будет один элемент html). На каждом шаге адресации в текущем контексте отбираются элементы, подходящие под указанные в шаге условия, и их перечень берётся как контекст для следующего шага или как возвращаемый результат.
Таким образом, первый шаг
/child::html
явным образом делает текущим контекстом для следующего шага перечень из одного элемента html, что было бы и так сделано неявно, если этот шаг не был обозначен.
На втором шаге адресации в данном примере (шаг child::body) контекстом является перечень из одного элемента html. Ось child:: говорит о том, что необходимо смотреть на имена вложенных элементов в текущем контексте, а условие проверки body говорит о том, что в формируемый набор элементов нужно включить те узлы, у которых имя - body. Таким образом, в ходе второго шага адресации получаем набор узлов, состоящий всего из одного элемента body, который и становится контекстом для третьего шага.
Третий шаг адресации: child::* . Ось child:: содержит все непосредственные потомки элемента body, а условие проверки * говорит о том, что в формируемый перечень нужно включить элементы основного типа с любым именем. В ходе этого шага получаем перечень, состоящий из трёх элементов div, одного span и одного элемента img — итого, пять элементов.
Четвёртый шаг адресации: child::span/@class. Его контекстом является перечень из пяти элементов, поэтому исходящий перечень создаётся в пять проходов (за пять итераций). При первой итерации узлом контекста становится первый div. Согласно заданной оси child:: и правилу проверки span, в набор должны включаться непосредственные потомки этого div'а, имя которых равно span. Там такой один. При второй итерации в набор ничего добавляться не будет, так как у второго div нет потомков. Третья итерация увидит сразу три элемента span. Четвёртая ничего не увидит, так как у элемента span нет потомков span, а то, что он сам span — не важно, ведь просматриваются именно потомки. Пятая тоже ничего не увидит, у элемента img тоже нет потомков span. Итак, в ходе проверки мог бы быть получен набор узлов, состоящий из четырёх элементов span. Это и было бы контекстом для последующей обработки, не будь на этом шаге указано предиката.
Но так как предикат на четвёртом шаге есть, по мере выполнения каждого из пяти проходов будет производиться дополнительная фильтрация отбираемых элементов. В данном случае у предиката ось attribute:: говорит о необходимости проверить, есть ли у отбираемого узла атрибуты, а условие class требует оставить лишь те узлы, у которых задан атрибут с именем class. И поэтому на первой итерации единственный найденный span фильтрацию предикатом не пройдёт, на третьей итерации фильтрацию пройдут два элемента из трёх, и в итоге, несмотря на то, что фильтрация происходит за пять итераций, в окончательный набор попадают только два элемента span.
Оси — это база языка XPath. Для некоторых осей существуют сокращённые обозначения.
/descendant::node()/
можно сокращать до
//
.
//span
отберёт все узлы
span
документа, независимо от их положения в иерархии, взглянув как на имя корневого, так и на имена всех его дочерних элементов, на всю глубину их вложенности.
..
.
@
xmlns
).
В рамках содержимого оси отбор выполняется согласно выражению, определяющему отбираемые элементы.
В качестве выражения может быть
*
, что отберёт все элементы оси
Функции делятся на 5 групп:
| Функция | Описание |
|---|---|
node-set
node
()
|
Возвращает сам узел. Вместо этой функции часто используют заменитель
*
, но, в отличие от звёздочки, функция
node()
возвращает и
текстовые
узлы
|
string
text
()
|
Возвращает узел, если он текстовый |
node-set
current
()
|
Возвращает множество из одного элемента, который является текущим. Если мы делаем обработку множества с предикатами, то единственным способом дотянуться из этого предиката до текущего элемента будет данная функция |
number
position
()
|
Возвращает позицию элемента в множестве элементов оси. Корректно работает только в цикле
<xsl:for-each/>
|
number
last
()
|
Возвращает номер последнего элемента в множестве элементов оси. Корректно работает только в цикле
<xsl:for-each/>
|
number
count
(node-set)
|
Возвращает количество элементов в
node-set
.
|
string
name
(node-set?)
|
Возвращает полное имя первого тега в множестве |
string
namespace-url
(node-set?)
|
Возвращает ссылку на URL, определяющий пространство имён |
string
local-name
(node-set?)
|
Возвращает имя первого тега в множестве, без пространства имён |
node-set
id
(object)
|
Находит элемент с уникальным идентификатором |
| Функция | Описание |
|---|---|
string
string
(object?)
|
Возвращает текстовое содержимое элемента. По сути, возвращает объединённое множество текстовых элементов на один уровень ниже |
string
concat
(string, string, string*)
|
Соединяет строки, указанные в аргументах |
number
string-length
(string?)
|
Возвращает длину строки |
boolean
contains
(string, string)
|
Возвращает
true
, если первая строка содержит вторую, иначе —
false
|
string
substring
(string, number, number?)
|
Возвращает строку, вырезанную из строки, начиная с указанного номера, и, если указан второй номер, — количество символов |
string
substring-before
(string, string)
|
Если найдена вторая строка в первой, возвращает строку до первого вхождения второй строки |
string
substring-after
(string, string)
|
Если найдена вторая строка в первой, возвращает строку после первого вхождения второй строки |
boolean
starts-with
(string, string)
|
Возвращает
true
, если вторая строка входит в начало первой, иначе —
false
|
boolean
ends-with
(string, string)
|
Возвращает
true
, если вторая строка входит в конец первой, иначе —
false
|
string
normalize-space
(string?)
|
Убирает лишние и повторные пробелы, а также управляющие символы, заменяя их пробелами |
string
translate
(string, string, string)
|
Заменяет символы первой строки, которые встречаются во второй строке, на соответствующие позиции символам из второй строки символы из третьей строки. Например,
translate("bar", "abc", "ABC")
вернёт BAr.
|
| Символ, оператор | Значение |
|---|---|
or
|
логическое «или» |
and
|
логическое «и» |
=
|
логическое «равно» |
<
(<)
|
логическое «меньше» |
>
(>)
|
логическое «больше» |
<=
(<=)
|
логическое «меньше либо равно» |
>=
(>=)
|
логическое «больше либо равно» |
| Функция | Описание |
|---|---|
boolean
boolean
(object)
|
Приводит объект к логическому типу |
boolean
true
()
|
Возвращает истину |
boolean
false
()
|
Возвращает ложь |
boolean
not
(boolean)
|
Отрицание, возвращает истину если аргумент ложь и наоборот |
| Символ, оператор | Значение |
|---|---|
+
|
сложение |
−
|
вычитание |
*
|
умножение |
div
|
обычное деление ( не нацело! ) |
mod
|
остаток от деления |
| Функция | Описание |
|---|---|
number
number
(object?)
|
Переводит объект в число |
number
sum
(node-set)
|
Вернёт сумму множества. Каждый тег множества будет преобразован в строку и из него получено число |
number
floor
(number)
|
Возвращает наибольшее целое число, не большее, чем аргумент (округление к меньшему) |
number
ceiling
(number)
|
Возвращает наименьшее целое число, не меньшее, чем аргумент (округление к большему) |
number
round
(number)
|
Округляет число по математическим правилам |
| Функция | Описание |
|---|---|
node-set
document
(object, node-set?)
|
Возвращает документ, указанный в параметре
object
|
string
format-number
(number, string, string?)
|
Форматирует число согласно образцу, указанному во втором параметре. Третий параметр указывает именованный формат числа, который должен быть учтён |
string
generate-id
(node-set?)
|
Возвращает строку, являющуюся уникальным идентификатором |
node-set
key
(string, object)
|
Возвращает множество с указанным ключом (аналогично функции
id
для идентификаторов)
|
string
unparsed-entity-uri
(string)
|
Возвращает непроанализированный URI. Если такового нет, возвращает пустую строку |
boolean
element-available
(string)
|
Проверяет, доступен ли элемент или множество, указанное в параметре. Параметр рассматривается как XPath |
boolean
function-available
(string)
|
Проверяет, доступна ли функция, указанная в параметре. Параметр рассматривается как XPath |
object
system-property
(string)
|
Параметры, возвращающие системные переменные. Могут быть:
Если используется неизвестный параметр, функция возвращает пустую строку |
boolean
lang
(string)
|
Возвращает
true
, если у текущего тега имеется атрибут
xml: lang
, либо родитель тега имеет атрибут
xml: lang
и в нём указан совпадающий строке символ
|
Предикаты - это логические выражения в квадратных скобках, составленные по тем же принципам, что и выражение отбора. Выражения, возвращающие не логическое значение, а пустой набор элементов, считаются ложными. Выражение, возвращающее число, считается выражением, сравнивающим число с position(). Когда предикатов более одного, каждый из них фильтрует результаты фильтрации предыдущим предикатом.
| Обозначение | Описание |
|---|---|
*
|
Обозначает
любое
имя или набор символов по указанной оси, например:
*
— любой дочерний узел;
@*
— любой атрибут
|
$name
|
Обращение к переменной.
name
— имя переменной или параметра
|
[]
|
Дополнительные условия выборки (или предикат шага адресации). Должен содержать логическое значение. Если содержит числовое, считается что это порядковый номер узла, что эквивалентно приписыванию перед этим числом выражения
position()=
|
{}
|
Если применяется внутри тега другого языка (например HTML), то XSLT-процессор рассматривает содержимое фигурных скобок как XPath |
/
|
Определяет уровень дерева, то есть разделяет шаги адресации |
|
|
Объединяет результат. То есть, в рамках одного пути можно написать несколько путей разбора через знак
|
, и в результат такого выражения войдёт всё, что будет найдено любым из этих путей
|
|
Продукты
и стандарты |
|
||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Организации |
|
||||||||||||||
| ПО |
|
||||||||||||||
| Конференции | |||||||||||||||