Interested Article - Фильтр Блума
- 2021-03-17
- 1
Фи́льтр Блу́ма ( англ. Bloom filter ) — это вероятностная структура данных , придуманная Бёртоном Блумом в 1970 году , позволяющая проверять принадлежность элемента к множеству . При этом существует возможность получить ложноположительное срабатывание (элемента в множестве нет, но структура данных сообщает, что он есть), но не ложноотрицательное .
Фильтр Блума может использовать любой объём памяти , заранее заданный пользователем, причём чем он больше, тем меньше вероятность ложного срабатывания. Поддерживается операция добавления новых элементов в множество, но не удаления существующих (если только не используется модификация со счётчиками).
Описание структуры данных
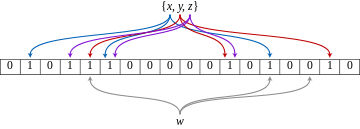


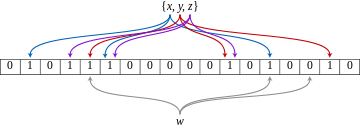
Фильтр Блума представляет собой битовый массив из m бит . Изначально, когда структура данных хранит пустое множество , все m бит обнулены. Пользователь должен определить k независимых хеш-функций h 1 , …, h k , каждая из которых отображает множество элементов в множество мощностью m. (Иными словами, каждому элементу хеш-функция сопоставляет число от 1 до m.) Для каждого элемента e биты массива с номерами h 1 ( e ), …, h k ( e ) равными значениям хеш-функций устанавливаются в 1.
Для проверки принадлежности элемента e к множеству хранимых элементов необходимо проверить состояние битов h 1 ( e ), …, h k ( e ). Если хотя бы один из них равен нулю, элемент не может принадлежать множеству (иначе бы при его добавлении все эти биты были установлены). Если все они равны единице, то структура данных сообщает, что е может принадлежать множеству. При этом может возникнуть две ситуации: либо элемент действительно принадлежит множеству, либо все эти биты оказались установлены по случайности при добавлении других элементов, что и является источником ложных срабатываний в этой структуре данных.
Независимость хеш-функций обеспечивает минимальную вероятность повторения индексов h k ( e ), минимизируя число бит установленных в 1 несколько раз. (А это главный источник ложноположительных срабатываний.)
Вероятность ложноположительного срабатывания

Пусть размер битового массива равен m бит и задано k хеш-функций. Предположим, что множество хеш-функций выбирается случайно, и для любого элемента x каждая хеш-функция h i назначает ему одно из мест в битовом массиве с равной вероятностью

и, кроме того, значения являются независимыми в совокупности случайными величинами (для упрощения последующего анализа).

Тогда вероятность того, что в некоторый p -й бит не будет записана единица во время операции вставки очередного элемента равна

А вероятность того, что p -й бит останется равным нулю после вставки n различных элементов x 1 , …, x n в изначально пустой фильтр Блума равна

для достаточно большого m ввиду второго замечательного предела .
Ложноположительное срабатывание состоит в том, что для некоторого элемента y , не равного ни одному из вставленных, все k бит с номерами h i ( y ) окажутся ненулевыми, и фильтр Блума ошибочно ответит, что y входит во множество вставленных элементов. Вероятность такого события примерно равна

Очевидно, что эта вероятность уменьшается с ростом m (размера битового массива) и увеличивается с ростом n (числа вставленных элементов). Для фиксированных m и n оптимальное число k (число хеш-функций), минимизирующих её, равно

При этом сама вероятность ложного срабатывания равна

Как следствие, заметим, что для того, чтобы фильтр Блума поддерживал заданную ограниченную вероятность ложного срабатывания, размер битового массива должен быть линейно пропорционален числу вставленных элементов.
Свойства
- В отличие от многих других структур данных (например, хеш-таблиц ), также хранящих множество элементов, фильтр Блума может представлять универсальное множество всех возможных элементов. В этом случае все биты в его битовом массиве равны единице.
- Объединение и пересечение двух фильтров Блума одинакового размера и c одинаковым множеством хеш-функций может быть реализовано побитовыми операциями OR и AND над их битовыми массивами.
Применение
По сравнению с хеш-таблицами фильтр Блума может обходиться на несколько порядков меньшими объёмами памяти, жертвуя детерминизмом. Обычно он используется для уменьшения числа запросов к несуществующим данным в структуре данных с более дорогостоящим доступом (например, расположенной на жестком диске или в сетевой базе данных), то есть для «фильтрации» запросов к ней.
Примеры практических применений:
- Прокси-сервер Squid использует фильтры Блума для опции .
- Google BigTable использует фильтры Блума для уменьшения числа обращений к жесткому диску при проверке на существование заданной строки или столбца в таблице базы данных.
- Компьютерные программы для проверки орфографии.
См. также
Примечания
- Bloom, Burton H. (1970), "Space/time trade-offs in hash coding with allowable errors", Communications of the ACM , 13 (7): 422—426, doi :
- . Дата обращения: 30 июля 2012. 8 февраля 2015 года.
- 2021-03-17
- 1