Interested Article - Си (язык программирования)

- 2020-12-08
- 1
| ISO/IEC 9899 | |
| Information technology — Programming languages — C | |
| Издатель | Международная организация по стандартизации (ISO) |
| Сайт | |
| Комитет (разработчик) | ISO/IEC JTC 1/SC 22 |
| Сайт комитета | |
| 35.060 | |
| Текущая редакция | |
| Предыдущие редакции |
ISO/IEC 9899:1990/COR2:1996
ISO/IEC 9899:1999/COR3:2007 ISO/IEC 9899:2011/COR1:2012 |
Си (от лат. буквы C , англ. языка ) — компилируемый статически типизированный язык программирования общего назначения, разработанный в 1969—1973 годах сотрудником Bell Labs Деннисом Ритчи как развитие языка Би . Первоначально был разработан для реализации операционной системы UNIX , но впоследствии был перенесён на множество других платформ. Согласно дизайну языка, его конструкции близко сопоставляются типичным машинным инструкциям , благодаря чему он нашёл применение в проектах, для которых был свойственен язык ассемблера , в том числе как в операционных системах , так и в различном прикладном программном обеспечении для множества устройств — от суперкомпьютеров до встраиваемых систем . Язык программирования Си оказал существенное влияние на развитие индустрии программного обеспечения, а его синтаксис стал основой для таких языков программирования, как C++ , C# , Java и Objective-C .
История
Язык программирования Си разрабатывался в период с 1969 по 1973 годы в лабораториях Bell Labs , и к 1973 году на этот язык была переписана большая часть ядра UNIX , первоначально написанного на ассемблере PDP-11 /20. Название языка стало логическим продолжением старого языка « Би » , многие особенности которого были положены в основу.
По мере развития язык сначала стандартизировали как ANSI C , а затем этот стандарт был принят комитетом по международной стандартизации ISO как ISO C, ставший также известным под названием C90. В стандарте С99 язык получил новые возможности, такие как массивы переменной длины и встраиваемые функции. А в стандарте C11 в язык добавили реализацию потоков и поддержку атомарных типов. Однако с тех пор язык развивается медленно, и в стандарт C18 попали лишь исправления ошибок стандарта C11.
Общие сведения
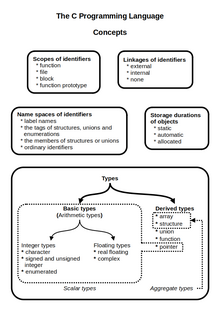
Язык Си разрабатывался как язык системного программирования, для которого можно создать однопроходный компилятор . Стандартная библиотека также невелика. Как следствие данных факторов — компиляторы разрабатываются сравнительно легко . Поэтому данный язык доступен на самых различных платформах. К тому же, несмотря на свою низкоуровневую природу, язык ориентирован на переносимость. Программы, соответствующие стандарту языка, могут компилироваться под различные архитектуры компьютеров.
Целью языка было облегчение написания больших программ с минимизацией ошибок по сравнению с ассемблером, следуя принципам процедурного программирования , но избегая всего, что может привести к дополнительным накладным расходам, специфичным для языков высокого уровня.
Основные особенности Си:
- простая языковая база, из которой в стандартную библиотеку вынесены многие существенные возможности, вроде математических функций или функций работы с файлами ;
- ориентация на процедурное программирование ;
- система типов , предохраняющая от бессмысленных операций;
- использование препроцессора для абстрагирования однотипных операций;
- доступ к памяти через использование указателей ;
- небольшое число ключевых слов;
- передача параметров в функцию по значению, а не по ссылке (передача по ссылке эмулируется с помощью указателей);
- наличие указателей на функции и статические переменные ;
- области видимости имён;
- структуры и объединения — определяемые пользователем собирательные типы данных, которыми можно манипулировать как одним целым.
В то же время в Си отсутствуют:
- вложенные функции;
- прямое возвращение нескольких значений из функций;
- сопрограммы ;
- средства автоматического управления памятью ;
- встроенные средства объектно-ориентированного программирования ;
- средства функционального программирования .
Часть отсутствующих возможностей может имитироваться встроенными средствами (например, сопрограммы можно имитировать с помощью функций
setjmp
и
longjmp
), часть добавляется с помощью сторонних библиотек (например, для поддержки многозадачности и для сетевых функций можно использовать библиотеки
pthreads
, sockets и тому подобные; существуют библиотеки для поддержки автоматической сборки мусора
), часть реализуется в некоторых компиляторах в виде расширений языка (например, вложенные функции в
GCC
).
Существует несколько громоздкая, но вполне работоспособная методика, позволяющая реализовывать на Си механизмы
ООП
, базирующаяся на фактической полиморфности указателей в Си и поддержке в этом языке указателей на функции. Механизмы ООП, основанные на данной модели, реализованы в библиотеке
GLib
и активно используются во фреймворке
GTK+
. GLib предоставляет базовый класс
GObject
, возможности наследования от одного класса
и реализации множества интерфейсов
.
После появления язык был хорошо принят, потому что он позволял быстро создавать компиляторы для новых платформ, а также позволял программистам довольно точно представлять, как выполняются их программы. Благодаря близости к языкам низкого уровня программы на Си работали эффективнее написанных на многих других языках высокого уровня, и лишь оптимизированный вручную код на ассемблере мог работать ещё быстрее, потому что давал полный контроль над машиной. На сегодняшний день развитие компиляторов и усложнение процессоров привело к тому, что вручную написанный ассемблерный код (кроме разве что очень коротких программ) практически не выигрывает по сравнению с кодом, генерируемым компиляторами, при этом Си продолжает оставаться одним из наиболее эффективных языков высокого уровня.
Синтаксис и семантика
Синтаксис языка Си достаточно сложный, а семантика неоднозначная . Основными двумя особенностями языка на момент его появления были унифицирование работы с массивами и указателями, а также схожесть того, как что-либо объявляется, с тем, как это в дальнейшем используется в выражениях . Однако в последующем эти две особенности языка были в числе наиболее критикуемых , и обе являются сложными для понимания среди начинающих программистов . Стандарт языка, определяя его семантику, не стал слишком сильно ограничивать реализации языка компиляторами, но этим самым сделал семантику недостаточно определённой. В частности, в стандарте есть 3 типа недостаточно определённой семантики: определяемое реализацией поведение, не заданное стандартом поведение и неопределённое поведение .
Типы данных
Примитивные типы
Целые числа
Размер целочисленных типов данных варьируется от не менее 8 до не менее 32 бит. Стандарт
C99
увеличивает максимальный размер целого числа — не менее 64 бит. Целочисленные типы данных используются для хранения целых чисел (тип
char
также используется для хранения ASCII-символов). Все размеры диапазонов представленных ниже типов данных минимальны и на отдельно взятой платформе могут быть больше
.
Как следствие минимальных размеров типов стандарт требует, чтобы для размеров целочисленных типов выполнялось условие:
1
=
sizeof
(
char
)
≤
sizeof
(
short
)
≤
sizeof
(
int
)
≤
sizeof
(
long
)
≤
sizeof
(
long
long
)
.
Таким образом, размеры некоторых типов по количеству байт могут совпадать, если будет удовлетворяться условие по минимальному количеству бит. Даже
char
и
long
могут иметь одинаковый размер, если один байт будет занимать 32 бита или более, но такие платформы будут очень редки или не будут существовать. Стандарт гарантирует, что тип
char
всегда
равен 1 байту. Размер байта в битах определяется константой
CHAR_BIT
из заголовочного файла
limits.h
, у
POSIX
-совместимых систем равен 8 битам
.
Минимальный диапазон значений целых типов по стандарту определяется с
-(2
N-1
-1)
по
2
N-1
-1
для знаковых типов и с
0
по
2
N
-1
— для беззнаковых, где N — разрядность типа. Реализация компиляторов может расширять этот диапазон по своему усмотрению. На практике для знаковых типов чаще используется диапазон с
-2
N-1
по
2
N-1
-1
. Минимальное и максимальное значения каждого типа указывается в файле
limits.h
в виде макроопределений.
Отдельное внимание стоит уделить типу
char
. Формально это отдельный тип, но фактически
char
эквивалентен либо
signed char
, либо
unsigned char
, в зависимости от компилятора
.
Для того, чтобы избежать путаницы между размерами типов стандарт C99 ввел новые типы данных, описанные в файле
stdint.h
. Среди них такие типы как:
int
N
_t
,
int_least
N
_t
,
int_fast
N
_t
, где
N
= 8, 16, 32 или 64. Приставка
least-
обозначает минимальный тип, способный вместить
N
бит, приставка
fast-
обозначает тип размером не менее 16 бит, работа с которым наиболее быстрая на данной платформе. Типы без приставок обозначают типы с фиксированном размером, равным
N
бит.
Типы с приставками
least-
и
fast-
можно считать заменой типам
int
,
short
,
long
, с той лишь разницей, что первые дают программисту выбрать между скоростью и размером.
| Тип данных | Размер | Минимальный диапазон значений | Стандарт |
|---|---|---|---|
signed char
|
минимум 8 бит | от −127 (= -(2 7 −1)) до 127 | C90 |
int_least8_t
|
C99 | ||
int_fast8_t
|
|||
unsigned char
|
минимум 8 бит | от 0 до 255 (=2 8 −1) | C90 |
uint_least8_t
|
C99 | ||
uint_fast8_t
|
|||
char
|
минимум 8 бит | от −127 до 127 или от 0 до 255 в зависимости от компилятора | C90 |
short int
|
минимум 16 бит | от −32,767 (= -(2 15 −1)) до 32,767 | C90 |
int
|
|||
int_least16_t
|
C99 | ||
int_fast16_t
|
|||
unsigned short int
|
минимум 16 бит | от 0 до 65,535 (= 2 16 −1) | C90 |
unsigned int
|
|||
uint_least16_t
|
C99 | ||
uint_fast16_t
|
|||
long int
|
минимум 32 бита | от −2,147,483,647 до 2,147,483,647 | C90 |
int_least32_t
|
C99 | ||
int_fast32_t
|
|||
unsigned long int
|
минимум 32 бита | от 0 до 4,294,967,295 (= 2 32 −1) | C90 |
uint_least32_t
|
C99 | ||
uint_fast32_t
|
|||
long long int
|
минимум 64 бита | от −9,223,372,036,854,775,807 до 9,223,372,036,854,775,807 | C99 |
int_least64_t
|
|||
int_fast64_t
|
|||
unsigned long long int
|
минимум 64 бита | от 0 до 18,446,744,073,709,551,615 (= 2 64 −1) | |
uint_least64_t
|
|||
uint_fast64_t
|
|||
int8_t
|
8 бит | от −127 до 127 | |
uint8_t
|
8 бит | от 0 до 255 (=2 8 −1) | |
int16_t
|
16 бит | от −32,767 до 32,767 | |
uint16_t
|
16 бит | от 0 до 65,535 (= 2 16 −1) | |
int32_t
|
32 бита | от −2,147,483,647 до 2,147,483,647 | |
uint32_t
|
32 бита | от 0 до 4,294,967,295 (= 2 32 −1) | |
int64_t
|
64 бита | от −9,223,372,036,854,775,807 до 9,223,372,036,854,775,807 | |
uint64_t
|
64 бита | от 0 до 18,446,744,073,709,551,615 (= 2 64 −1) | |
| В таблице приведён минимальный диапазон значений согласно стандарту языка. Компиляторы языка Си могут расширять диапазон значений. | |||
Вспомогательные целочисленные типы
Также со стандарта C99 добавлены типы
intmax_t
и
uintmax_t
, соответствующие самым большим знаковому и беззнаковому типам соответственно. Данные типы удобны при использовании в макросах для хранения промежуточных или временных значений при операциях над целочисленными аргументами, так как позволяют уместить значения любого типа. Например, эти типы используются в макросах сравнения целочисленных значений библиотеки модульного тестирования
Check
для языка Си
.
В Си существует несколько дополнительных целочисленных типов для безопасной работы с типом данных указателей:
intptr_t
,
uintptr_t
и
ptrdiff_t
. Типы
intptr_t
и
uintptr_t
из стандарта C99 предназначены для хранения соответственно знакового и беззнакового значений, которые по размеру могут уместить в себе указатель. Эти типы часто применяются для хранения произвольного целого числа в указателе, например, как способ избавиться от лишнего выделения памяти при регистрации функций обратной связи
либо при использовании сторонних связных списков, ассоциативных массивов и прочих структур, в которых данные хранятся по указателю. Тип
ptrdiff_t
из заголовочного файла
stddef.h
предназначен для безопасного хранения разности двух указателей.
Для хранения размера предусмотрен беззнаковый тип
size_t
из заголовочного файла
stddef.h
. Данный тип способен уместить максимально возможное количество байт, доступное по указателю, и обычно используется для хранения размера в байтах. Значение именно этого типа возвращает оператор
sizeof
.
Приведение целочисленных типов
Преобразования целочисленных типов могут происходить как явно, с помощью оператора приведения типов, так и неявно. Значения типов, меньших по размеру, чем
int
, при участии в каких-либо операциях или при передаче в вызов функции автоматически приводятся к типу
int
, а в случае невозможности преобразования — к типу
unsigned int
. Зачастую подобные неявные приведения необходимы, чтобы результат вычисления оказался правильным, но иногда приводят к интуитивно-непонятным ошибкам в вычислениях. Например, если в операции участвуют числа типа
int
и
unsigned int
, а знаковое значение отрицательно, то преобразование отрицательного числа к беззнаковому типу приведёт к переполнению и возникновению очень большого положительного значения, что может привести к неверному результату операций сравнения
.
Знаковый и беззнаковый типы меньше, чем
int
|
Знаковый меньше беззнакового, а беззнаковый не менее
int
|
|---|---|
#include <stdio.h>
signed char x = -1;
unsigned char y = 0;
if (x > y) { // условие ложно
printf("Сообщение не будет показано.\n");
}
if (x == UCHAR_MAX) {
// условие ложно
printf("Сообщение не будет показано.\n");
}
|
#include <stdio.h>
signed char x = -1;
unsigned int y = 0;
if (x > y) { // условие истинно
printf("Переполнение в переменной x.\n");
}
if ((x == UINT_MAX) && (x == ULONG_MAX)) {
// условие всегда будет истинным
printf("Переполнение в переменной x.\n");
}
|
В данном примере оба типа, знаковый и беззнаковый, будут приведены к знаковому типу
int
, поскольку он позволяет уместить диапазоны обоих типов. Поэтому сравнение в условном операторе будет корректным.
|
Знаковый тип будет приведён к беззнаковому, поскольку беззнаковый больше или равен по размеру типу
int
, но произойдёт переполнение, поскольку в беззнаковом типе невозможно представить отрицательное значение.
|
Также автоматическое приведение типов сработает, если в выражении используется два или более разных целочисленных типа. Стандарт определяет ряд правил, согласно которым выбирается такое преобразование типов, которое может дать правильный результат вычислений. Разным типам назначены разные ранги в рамках преобразования, а сами ранги основаны на размере типа. При участии в выражении разных типов обычно выбирается приведение этих значений к типу большего ранга .
Вещественные числа
Числа с плавающей запятой
в языке Си представлены тремя основными типами:
float
,
double
и
long double
.
Вещественные числа имеют представление, сильно отличающее их от целых. Константы вещественных чисел разных типов, записанные в десятичном представлении, могут быть не равны друг другу. Например, условие
0.1 == 0.1f
будет ложным из-за потери точности у типа
float
, в то время как условие
0.5 == 0.5f
будет истинным, поскольку эти числа конечны в двоичном представлении. Однако условие с приведением
(float) 0.1 == 0.1f
также будет истинным, поскольку при приведении типа к менее точному теряются разряды, из-за которых в этих двух константах есть различия.
Арифметические операции с вещественными числами также являются неточными и зачастую имеют некоторую плавающую погрешность . Наибольшая погрешность будет возникать при операциях над значениями, близкими к минимально возможному для конкретного типа. Также погрешность может оказаться большой при вычислениях над одновременно очень маленькими (≪ 1) и очень большими по модулю числами (≫ 1). В ряде случаев погрешность может быть снижена изменением алгоритмов и методик вычислений. Например, при замене многократного сложения умножением погрешность может снизиться во столько раз, сколько изначально было операций сложения.
Также в заголовочном файле
math.h
присутствуют два дополнительных типа
float_t
и
double_t
, которые соответствуют как минимум типам
float
и
double
соответственно, но могут быть отличными от них. Типы
float_t
и
double_t
добавлены в стандарте
C99
, а их соответствие основным типам определяется значением макроса
FLT_EVAL_METHOD
.
| Тип данных | Размер | Стандарт |
|---|---|---|
float
|
32 бита | IEC 60559 ( IEEE 754 ), расширение F стандарта Си , число одинарной точности |
double
|
64 бита | IEC 60559 (IEEE 754), расширение F стандарта Си , число двойной точности |
long double
|
минимум 64 бита | зависит от реализации |
float_t
(C99)
|
минимум 32 бита | зависит от базового типа |
double_t
(C99)
|
минимум 64 бита | зависит от базового типа |
FLT_EVAL_METHOD
|
float_t
|
double_t
|
|---|---|---|
| 1 |
float
|
double
|
| 2 |
double
|
double
|
| 3 |
long double
|
long double
|
Строки
Нуль-терминированные строки
Хотя как такового специального типа для строк в Си не предусмотрено, в языке активно используются нуль-терминированные строки.
ASCII
-строки объявляются как массив типа
char
, последним элементом которого должен быть символ с кодом
0
(
'\0'
). В этом же формате принято хранить и строки в формате
UTF-8
. Однако все функции, работающие с ASCII-строками, рассматривают каждый символ как байт, что ограничивает применение стандартных функций при использовании данной кодировки.
Несмотря на широкое распространение идеи нуль-терминированных строк и удобство их использования в некоторых алгоритмах, у них есть несколько серьёзных недостатков.
- Необходимость добавления в конец строки терминального символа не даёт возможность получить подстроку без необходимости её копирования, а функций для работы с указателем на подстроку и её длиной в языке не предусмотрено.
- Если требуется заранее выделять память под результат алгоритма на основе входных данных, каждый раз требуется обходить всю строку для подсчёта её длины.
- При работе с большими объёмами текста подсчёт длины может оказаться узким местом .
- Работа со строкой, которая по ошибке не терминирована нулём, может приводить к неопределённому поведению программы, в том числе к ошибкам сегментирования , ошибкам переполнения буфера и к уязвимостям .
В современных условиях, когда производительность кода приоритетнее расхода памяти, может оказаться эффективнее и проще использовать структуры, содержащие в себе как саму строку, так и её размер , например:
struct string_t {
char *str; // указатель на строку
size_t str_size; // размер строки
};
typedef struct string_t string_t; // альтернативное имя для упрощения кода
Альтернативным вариантом хранения размера строки с низким потреблением памяти может оказаться подход добавления в начало строки её размера в формате . Подобный подход применяется в протокольных буферах , однако только на этапе передачи данных, но не их хранения.
Строковые литералы
Строковые литералы в Си по своей сути являются константами
. При объявлении заключаются в двойные кавычки, а терминирующий
0
добавляются компилятором автоматически. Допускается два способа присваивания строкового литерала: по указателю и по значению. При присваивании по указателю в переменную типа
char *
заносится указатель на неизменяемую строку, то есть формируется константная строка. Если же заносить строковый литерал в массив, то происходит копирование строки в область стека.
#include <stdio.h>
#include <string.h>
int main(void)
{
const char *s1 = "Константная строка";
char s2[] = "Строка, которую можно менять";
memcpy(s2, "с", strlen("с")); // замена первой буквы на маленькую
puts(s2); // выведется текст строки
memcpy((char *) s1, "к", strlen("к")); // ошибка сегментирования
puts(s1); // строка не будет исполнена
}
Поскольку строки являются обычными массивами символов, вместо литералов можно использовать инициализаторы, если каждый символ умещается в 1 байт:
char s[] = {'I', 'n', 'i', 't', 'i', 'a', 'l', 'i', 'z', 'e', 'r', '\0'};
Однако на практике такой подход имеет смысл только в крайне редких случаях, когда к ASCII-строке требуется не добавлять терминирующий ноль.
Широкие строки
| Платформа | Кодировка |
|---|---|
| GNU/Linux | USC-4 |
| macOS | |
| Windows | USC-2 |
| AIX | |
| FreeBSD |
Зависит от локали,
не документировано |
| Solaris |
Альтернативой обычным строкам могут служить широкие строки, в которых каждый символ хранится в специальном типе
wchar_t
. Данный тип по стандарту должен быть способен уместить в себе все символы самой большой из существующих
локалей
. Функции для работы с широкими строками описаны в заголовочном файле
wchar.h
, а функции для работы с широкими символами описаны в заголовочном файле
wctype.h
.
При объявлении строковых литералов для широких строк используется модификатор
L
:
const wchar_t *wide_str = L"Широкая строка";
В форматированном выводе используется спецификатор
%ls
, однако спецификатор размера, если задан, указывается в байтах, а не в символах
.
Тип
wchar_t
задумывался для того, чтобы в него мог поместиться любой символ, а широкие строки — для хранения строк любой локали, но в результате API оказался неудобным, а реализации — платформозависимыми. Так, на платформе
Windows
в качестве размера типа
wchar_t
было выбрано 16 бит, а позже появился стандарт UTF-32, таким образом тип
wchar_t
на платформе Windows уже не способен уместить в себе все символы из кодировки UTF-32, в результате чего теряется смысл данного типа
. В то же время на платформах Linux
и macOS данный тип занимает 32 бита, поэтому для реализации
кроссплатформенных
задач тип
wchar_t
не подходит.
Многобайтовые строки
Существует много разных кодировок, в которых отдельный символ может быть запрограммирован разным количеством байт. Такие кодировки называются многобайтовыми. К ним относится также и
UTF-8
. В Си существует набор функций для преобразования строк из многобайтовых в рамках текущей локали в широкие и наоборот. Функции для работы с многобайтовыми символами имеют префикс либо суффикс
mb
и описаны в заголовочном файле
stdlib.h
. Для поддержки многобайтовых строк в программах на языке Си, такие строки должны поддерживаться на уровне текущей
локали
. Для явного задания кодировки можно менять текущую локаль с помощью функции
setlocale()
из заголовочного файла
locale.h
. Однако задание кодировки для локали должно поддерживаться используемой стандартной библиотекой. Так, например, стандартная библиотека
Glibc
полностью поддерживает кодировку UTF-8 и способна преобразовывать текст во множество других кодировок
.
Начиная со стандарта C11 язык поддерживает также 16-битные и 32-битные широкие многобайтовые строки с соответствующими типами символа
char16_t
и
char32_t
из заголовочного файла
uchar.h
, а также объявление строковых литералов в формате UTF-8 с помощью модификатора
u8
. 16-битные и 32-битные строки могут использоваться для хранения кодировок
UTF-16
и
UTF-32
, если в заголовочном файле
uchar.h
заданы макроопределения
__STDC_UTF_16__
и
__STDC_UTF_32__
, соответственно. Для задания строковых литералов в данных форматах используются модификаторы:
u
для 16-битных строк и
U
для 32-битных строк. Примеры объявления строковых литералов для многобайтовых строк:
const char *s8 = u8"Многобайтовая строка в кодировке UTF-8";
const char16_t *s16 = u"16-битная многобайтовая строка";
const char32_t *s32 = U"32-битная многобайтовая строка";
Следует иметь в виду, что функция
c16rtomb()
для преобразования из 16-битной строки в многобайтовую работает не так, как задумывалось, и в стандарте C11 оказалась неспособной переводить из UTF-16 в UTF-8
. Исправление работы данной функции может зависеть от конкретной реализации компилятора.
Пользовательские типы
Перечисления
Перечисления
представляют собой набор именованных целочисленных констант и обозначаются с помощью ключевого слова
enum
. Если константе не сопоставлено число, то ей автоматически задаётся либо
0
для первой константы в списке, либо число на единицу бо́льшее, чем задано в предыдущей константе. При этом сам тип данных перечисления по факту может соответствовать любому знаковому или беззнаковому примитивному типу, в диапазон которого умещаются все значения перечислений; решение о выборе того или иного типа принимает компилятор. Однако явно заданные значения для констант должны быть выражениями типа
int
.
Тип перечисления может быть также анонимным, если не указано название перечисления. Константы, указанные в двух разных перечислениях, относятся к двум разным типам данных, независимо от того, являются ли перечисления именованными или анонимными.
На практике перечисления часто используются для обозначения состояний конечных автоматов , для задания вариантов режимов работы или значений параметров , для создания целочисленных констант, а также для перечисления каких-либо уникальных объектов или свойств .
Структуры
Структуры представляют собой объединение переменных разных типов данных в рамках одной области памяти; обозначаются ключевым словом
struct
. Переменные внутри структуры называются полями структуры. С точки зрения адресного пространства поля всегда идут друг за другом в том же порядке, в котором указаны, но компиляторы могут выравнивать адреса полей для оптимизации под ту или иную архитектуру. Таким образом, фактически поле может занимать бо́льший размер, чем указано в программе.
Каждое поле имеет определённое смещение относительно адреса структуры и размер. Смещение можно получить с помощью макроса
offsetof()
из заголовочного файла
stddef.h
. При этом смещение будет зависеть от выравнивания и размера предыдущих полей. Размер поля обычно определяется выравниванием структуры: если размер выравнивания типа данных поля меньше значения выравнивания структуры, то размер поля определяется выравниванием структуры. Выравнивание типов данных можно получить с помощью макроса
alignof()
из заголовочного файла
. Размер самой структуры является совокупным размером всех её полей с учётом выравнивания. При этом некоторые компиляторы предоставляют специальные атрибуты, позволяющие упаковывать структуры, убирая из них выравнивания
.
Полям структур можно явно задавать размер в битах через двоеточие после определения поля и указание количества бит, что ограничивает диапазон их возможных значений, несмотря на тип поля. Подобный подход может использоваться как альтернатива флагам и битовым маскам для обращения к ним. Однако указание количества бит не отменяет возможного выравнивания полей структур в памяти. Работа с битовыми полями имеет ряд ограничений: к ним невозможно применить оператор
sizeof
или макрос
alignof()
, на них невозможно получить указатель.
Объединения
Объединения
необходимы в тех случаях, когда требуется обращаться к одной и той же переменной как к разным типам данных; обозначаются ключевым словом
union
. Внутри объединения может быть объявлено произвольное количество пересекающихся полей, которые по факту предоставляют доступ к одной и той же области памяти как к разным типам данных. Размер объединения выбирается компилятором исходя из размера самого большого поля в объединении. Следует иметь в виду, что изменение одного поля объединения приводит к изменению и всех других полей, но гарантированно правильным будет только значение того поля, которое менялось.
Объединения могут служить более удобной альтернативной приведению указателя к произвольному типу. К примеру, с помощью объединения, помещённого в структуру, можно создавать объекты с динамически меняющимся типом данных:
#include <stddef.h>
enum value_type_t {
VALUE_TYPE_LONG, // целое число
VALUE_TYPE_DOUBLE, // вещественное число
VALUE_TYPE_STRING, // строка
VALUE_TYPE_BINARY, // произвольные данные
};
struct binary_t {
void *data; // указатель на данные
size_t data_size; // размер данных
};
struct string_t {
char *str; // указатель на строку
size_t str_size; // размер строки
};
union value_contents_t {
long as_long; // значение как целое число
double as_double; // значение как вещественное число
struct string_t as_string; // значение как строка
struct binary_t as_binary; // значение как произвольные данные
};
struct value_t {
enum value_type_t type; // тип значения
union value_contents_t contents; // содержимое значения
};
Массивы
Массивы в языке Си примитивны и являются лишь синтаксическим абстрагированием над . Сам по себе массив является указателем на область памяти, поэтому вся информация о размерности массива и его границах может быть доступна только на этапе компиляции согласно описанию типа. Массивы могут быть как одномерными, так и многомерными, но обращение к элементу массива сводится к простому вычислению смещения относительно адреса начала массива. Поскольку массивы основаны на адресной арифметике, с ними возможно работать без использования индексов . Так, например, следующие два примера считывания с потока ввода 10 чисел идентичны друг другу:
| Код примера работы через индексы | Код примера работы через адресную арифметику |
|---|---|
#include <stdio.h>
int a[10] = {0}; // Инициализация нулями
unsigned int count = sizeof(a) / sizeof(a[0]);
for (int i = 0; i < count; ++i) {
int *ptr = &a[i]; // Указатель на текущий элемента массива
int n = scanf("%8d", ptr);
if (n != 1) {
perror("Не удалось считать значение");
// Обработка ошибки
break;
}
}
|
#include <stdio.h>
int a[10] = {0}; // Инициализация нулями
unsigned int count = sizeof(a) / sizeof(a[0]);
int *a_end = a + count; // Указатель на элемент, следующий за последним
for (int *ptr = a; ptr != a_end; ++ptr) {
int n = scanf("%8d", ptr);
if (n != 1) {
perror("Не удалось считать значение");
// Обработка ошибки
break;
}
}
|
Длина массивов с заранее известным размером вычисляется на этапе компиляции. В стандарте
C99
появилась возможность объявлять массивы переменной длины, у которых длина может задаваться на этапе выполнения. Под такие массивы выделяется память из области стека, поэтому их необходимо использовать с осторожностью, если их размер может задаваться извне программы. В отличие от выделения динамической памяти, превышение допустимого размера в области стека может повлечь непредсказуемые последствия, а отрицательная длина массива —
неопределённое поведение
. Начиная с
C11
массивы переменной длины являются опциональными для компиляторов, а отсутствие поддержки определяется наличием макроса
__STDC_NO_VLA__
.
Массивы фиксированного размера, объявляемые как локальные или глобальные переменные, можно инициализировать, задавая им начальное значение с помощью фигурных скобок и перечисления элементов массива через запятую. В инициализаторах глобальных массивов допускается использовать только такие выражения, которые вычисляются на этапе компиляции
. Переменные, используемые в таких выражениях должны объявляться как константы, с модификатором
const
. У локальных массивов инициализаторы могут содержать выражения с вызовами функций и использованием других переменных, в том числе можно заносить указатель на сам объявляемый массив.
Со стандарта C99 последним элементом структур допускается объявлять массив произвольной длины, что широко используется на практике и поддерживается различными компиляторами. Размер такого массива зависит от объёма памяти, выделяемого под структуру. При этом нельзя объявлять массив таких структур и нельзя их помещать в другие структуры. В операциях над такой структурой массив произвольной длины обычно игнорируется, в том числе и при вычислении размера структуры, а выход за пределы массива влечёт за собой неопределённое поведение .
Язык Си не предусматривает какого-либо контроля выхода за пределы массива, поэтому программист сам должен следить за работой с массивами. Ошибки при обработке массивов не всегда явно влияют на ход исполнения программы, но могут приводить к ошибкам сегментирования и уязвимостям .
Синонимы типов
Язык Си допускает создание собственных названий типов с помощью оператора
typedef
. Альтернативные названия можно задавать как системным типам, так и пользовательским. Такие названия объявляются в глобальном пространстве имён и не конфликтуют с названиями типов структур, перечислений и объединений.
Альтернативные названия могут применяться как для упрощения кода, так и для создания уровней абстракции. Например, некоторые системные типы можно сократить для повышения читабельности кода или унифицирования его написания в пользовательском коде:
#include <stdint.h>
typedef int32_t i32_t;
typedef int_fast32_t i32fast_t;
typedef int_least32_t i32least_t;
typedef uint32_t u32_t;
typedef uint_fast32_t u32fast_t;
typedef uint_least32_t u32least_t;
Примером абстрагирования могут служить названия типов в заголовочных файлах операционных системах. Так, стандарт
POSIX
определяет тип
pid_t
, предназначенный для хранения числового идентификатора процесса. На самом деле данный тип является альтернативным названием для какого-либо примитивного типа, например:
typedef int __kernel_pid_t;
typedef __kernel_pid_t __pid_t
typedef __pid_t pid_t;
Поскольку типы с альтернативными названиями являются лишь синонимами оригинальным типам, то между ними сохраняется полная совместимость и взаимозаменяемость.
Препроцессор
Препроцессор работает до компиляции и преобразует текст файла программы согласно встреченным в нём или переданным в препроцессор
директивам
. Технически препроцессор может быть реализован по-разному, но логически его удобно представлять именно как отдельный модуль, целиком обрабатывающий каждый предназначенный для компиляции файл и формирующий текст, попадающий затем на вход компилятора. Препроцессор ищет в тексте строки, начинающиеся с символа
#
, вслед за которым должны следовать директивы препроцессора. Всё, что не относится к директивам препроцессора и не исключено из компиляции согласно директивам, передаётся на вход компилятора в неизменном виде.
В число возможностей препроцессора входит:
-
подмена заданной лексемы текстом с помощью директивы
#define, включая возможность создания параметризованных шаблонов текста (вызываются аналогично функциям), а также отменять подобные подмены, что даёт возможность осуществлять подмену на ограниченных участках текста программы; -
условное встраивание и удаление кусков из текста, включая сами директивы, с помощью условных команд
#ifdef,#ifndef,#if,#elseи#endif; -
встраивание в текущий файл текста из другого файла с помощью директивы
#include.
Важно понимать, что препроцессор обеспечивает только подстановку текста, не учитывая синтаксис и семантику языка. Так, например, макроопределения
#define
могут встречаться внутри функций или определений типов, а директивы условной компиляции могут приводить к исключению из компилируемого текста программы любой части кода, без оглядки на грамматику языка. Вызов параметрического макроса также отличается от вызова функции, поскольку не происходит анализа семантики аргументов, разделяемых запятой. Так, например, в аргументы параметрического макроса невозможно передать инициализацию массива, поскольку его элементы тоже разделяются запятой:
#define array_of(type, array) (((type) []) (array))
int *a;
a = array_of(int, {1, 2, 3}); // ошибка компиляции:
// в макрос "array_of" передано 4 аргумента, но он принимает лишь 2
Макроопределения часто используются для обеспечения совместимости с разными версиями библиотек, у которых изменился API , включая те или иные участки кода в зависимости от версии библиотеки. Для этих целей библиотеки часто предоставляют макроопределения с описанием своей версии , а иногда и макросы с параметрами для сравнения текущей версии с заданной в рамках препроцессора . Также макроопределения применяются для условной компиляции отдельных кусков программы, например для включения поддержки какого-либо дополнительного функционала.
Макроопределения с параметрами широко используются в Си-программах для создания аналогов
обобщённых функций
. Ранее они также применялись для реализации встраиваемых функций, но начиная со стандарта С99 эта необходимость исчезла благодаря добавлению
inline
-функций. Однако в связи с тем, что макроопределения с параметрами функциями не являются, но вызываются аналогичным образом, по ошибке программиста могут возникать неожиданные проблемы, включая отработку только части кода из макроопределения
и неправильные приоритеты выполнения операций
. В качестве примера ошибочного кода можно привести макрос возведения числа в квадрат:
#include <stdio.h>
int main(void)
{
#define SQR(x) x * x
printf("%d", SQR(5)); // всё верно, 5*5=25
printf("%d", SQR(5 + 0)); // предполагалось 25, но будет выведено 5 (5+0*5+0)
printf("%d", SQR(4 / 3)); // всё верно, 1 (т. к. 4/3=1, 1*4=4, 4/3=1)
printf("%d", SQR(5 / 2)); // предполагалось 4 (2*2), но будет выведено 5 (5/2*5/2)
return 0;
}
В приведённом выше примере ошибкой является то, что содержимое аргумента макроса подставляется в текст как есть, без учёта приоритетов операций. В таких случаях необходимо использовать
inline
-функции либо явно расставлять приоритеты операций в выражениях, использующих параметры макроса, с помощью круглых скобок:
#include <stdio.h>
int main(void)
{
#define SQR(x) ((x) * (x))
printf("%d", SQR(4 + 1)); // верно, 25
return 0;
}
Программирование на Си
Структура программы
Модули
Программа представляет собой набор файлов с кодом на языке Си, которые могут компилироваться в
объектные файлы
. Объектные файлы затем проходят этап
компоновки
друг с другом, а также со внешними библиотеками, в результате чего получается итоговый
исполняемый файл
или
библиотека
. Связь файлов друг с другом, равно как и с библиотеками, требует описания прототипов используемых функций, внешних переменных и необходимых типов данных в каждом файле. Такие данные принято выносить в отдельные
заголовочные файлы
, которые подключаются с помощью
директивы
#include
в тех файлах, где требуется та или иная функциональность, и позволяют организовывать систему, похожую на систему модулей. Модулем в таком случае может выступать:
- набор отдельных файлов с исходным кодом, для которых представлен интерфейс в виде заголовочных файлов;
- объектная библиотека или её часть, с соответствующими заголовочными файлами;
- самодостаточный набор из одного или более заголовочных файлов (интерфейсная библиотека);
- статическая библиотека или её часть с соответствующими заголовочными файлами;
- динамическая библиотека или её часть с соответствующими заголовочными файлами.
Поскольку директива
#include
лишь подставляет текст другого файла на этапе
препроцессора
, многократное подключение одного и того же файла может приводить к ошибкам этапа компиляции. Поэтому в таких файлах используется
защита от повторного включения
с помощью
макрокоманд
#define
и
#ifndef
.
Файлы исходного кода
Текст файла исходного кода на языке Си состоит из набора глобальных определений данных, типов и функций. Глобальные переменные и функции, объявленные со спецификаторами
static
и
inline
, доступны только в пределах того файла, в котором они объявлены, либо при включении одного файла в другой через директиву
#include
. При этом функции и переменные, объявленные в заголовочном файле со словом
static
, будут создаваться заново при каждом подключении заголовочного файла к очередному файлу с исходным кодом. Глобальные переменные и прототипы функции, объявленные со спецификатором extern, считаются подключаемыми из других файлов. То есть их допускается использовать в соответствии с описанием; предполагается, что после сборки программы они будут связаны
компоновщиком
с оригинальными объектами и функциями, описанными в своих файлах.
Глобальные переменные и функции, кроме
static
и
inline
, могут быть доступны из других файлов при условии их надлежащего объявления там со спецификатором
extern
. Переменные и функции, объявленные с модификатором
static
, также могут быть доступны в других файлах, но лишь при передаче их адреса по указателю. Объявления типов
typedef
,
struct
и
union
не могут импортироваться в других файлах. При необходимости использования в других файлах они должны быть там продублированы либо вынесены в отдельный заголовочный файл. То же самое относится и к
inline
-функциям.
Точка входа программы
Для исполняемой программы стандартной точкой входа является функция с именем
main
, которая не может быть статической и должна быть единственной в программе. Исполнение программы начинается с первого оператора функции
main()
и продолжается до выхода из неё, после чего программа завершается и возвращает операционной системе абстрактный целочисленный код результата своей работы.
| Без аргументов | С аргументами командной строки |
|---|---|
int main(void);
|
int main(int argc, char** argv);
|
В переменную
argc
при вызове передаётся количество аргументов, переданных программе, включая и путь к самой программе, поэтому обычно переменная argc содержит значение не меньшее, чем 1. В переменную
argv
передаётся сама строка запуска программы в виде массива текстовых строк, последним элементом которого является
NULL
. Компилятор гарантирует, что на момент запуска функции
main()
все глобальные переменные в программе будут инициализированы
.
В качестве результата функция
main()
может вернуть любое целое число в диапазоне значений типа
int
, которое будет передано операционной системе или другому окружению в качестве
кода возврата
программы
. Стандарт языка не определяет смысла кодов возврата
. Обычно операционная система, где работают программы, имеет те или иные средства, позволяющие получить значение кода возврата и проанализировать его. Иногда существуют определённые соглашения о значениях этих кодов. Общим является соглашение о том, что нулевое значение кода возврата сигнализирует об успешном завершении программы, а ненулевое представляет собой код возникшей ошибки. Заголовочный файл
stdlib.h
определяет два общих макроопределения
EXIT_SUCCESS
и
EXIT_FAILURE
, которые соответствуют успешному и неуспешному завершению работы программы
. Коды возврата также могут использоваться в рамках приложений, включающих в себя множество процессов, для обеспечения взаимодействия между этими процессами, в случае чего приложение само определяет смысловое значение для каждого кода возврата.
Работа с памятью
Модель памяти
В Си предусмотрено 4 способа выделения памяти, которые определяют время жизни переменной и момент её инициализации .
| Способ выделения | Целевые объекты | Время выделения | Время освобождения | Накладные расходы |
|---|---|---|---|---|
| Статическое выделение памяти |
Глобальные переменные и переменные, помеченные ключевым словом
static
(но без
_Thread_local
)
|
При старте программы | По завершении работы программы | Отсутствуют |
| Выделение памяти на уровне потока |
Переменные, помеченные ключевым словом
_Thread_local
|
При старте потока | По завершении потока | При создании потока |
| Автоматическое выделение памяти | Аргументы функций и возвращаемые ими значения, локальные переменные функций, в том числе регистры и массивы переменной длины | При вызове функций на уровне стека . | Автоматически по завершении функций | Незначительны, поскольку изменяется лишь указатель на вершину стека |
| Динамическое выделение памяти |
Память, выделяемая через функции
malloc()
,
calloc()
и
realloc()
|
Вручную из кучи в момент вызова используемой функции. |
Вручную с помощью функции
free()
|
Большие как на выделение, так и на освобождение |
Все эти способы хранения данных пригодны в различных ситуациях и имеют свои преимущества и недостатки. Глобальные переменные не позволяют писать реентерабельные алгоритмы, а автоматическое выделение памяти не позволяет возвращать произвольную область памяти из вызова функции. Автоматическое выделение также не подходит для выделения больших объёмов памяти, поскольку может привести к порче стека или кучи . Динамическая память лишена этих недостатков, но имеет большие накладные расходы при её использовании и более сложна в использовании.
Там, где это возможно, предпочтительным является автоматическое или статическое выделение памяти: такой способ хранения объектов управляется компилятором , что освобождает программиста от трудностей ручного выделения и освобождения памяти, как правило, служащего источником трудно отыскиваемых ошибок утечек памяти, ошибок сегментирования и повторного освобождения в программе. К сожалению, многие структуры данных имеют переменный размер во время выполнения программы, поэтому из-за того, что автоматически и статически выделенные области должны иметь известный фиксированный размер во время компиляции, очень часто требуется использовать динамическое выделение.
Для автоматически выделяемых переменных с помощью модификатора
register
можно давать подсказку компилятору о необходимости быстрого доступа к ним. Такие переменные могут помещаться в регистры процессора. Из-за ограниченного количества регистров и возможных оптимизаций компилятора переменные могут оказаться в обычной памяти, но тем не менее из программы на них невозможно будет получить указатель
. Модификатор
register
является единственным, который можно указывать в аргументах функций
.
Адресация памяти
Язык Си унаследовал линейную адресацию памяти при работе со структурами, массивами и выделенными областями памяти. Стандарт языка также допускает выполнение операций сравнения над нулевым указателем и над адресами в рамках массивов, структур и выделенных областей памяти. Также допускается работа с адресом элемента массива, следующим за последним, что сделано для облегчения написания алгоритмов. Однако сравнение указателей адресов, полученных для разных переменных (или областей памяти) не должно осуществляться, так как результат будет зависеть от реализации конкретного компилятора .
Представление в памяти
Представление памяти программы зависит от аппаратной архитектуры, от операционной системы и от компилятора. Так, например, на большинстве архитектур стек растёт вниз, но существуют архитектуры, где стек растёт вверх . Граница между стеком и кучей может быть частично защищена от переполнения стека специальной областью памяти . А расположение данных и кода библиотек может зависеть от параметров компиляции . Стандарт Си абстрагируется над реализацией и позволяет писать переносимый код, однако понимание устройства памяти процесса помогает в отладке и написании безопасных и отказоустойчивых приложений.
Типовое представление памяти процесса в Unix-подобных ОС
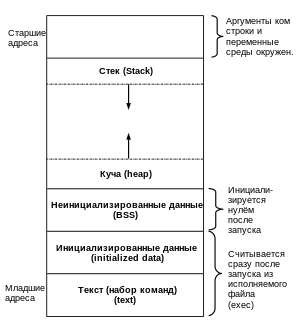
При запуске программы из исполняемого файла в оперативную память импортируются инструкции процессора (машинный код) и инициализированные данные. В то же время в старшие адреса импортируются аргументы командной строки (доступные в функции
main()
со следующей сигнатурой во втором аргументе
int argc, char ** argv
) и переменные окружения.
Область неинициализированных данных содержит глобальные переменные (в том числе, объявленные как
static
), которые не были проинициализированы в программном коде. Такие переменные по умолчанию инициализируются нулями после старта программы. Область инициализированных данных — сегмент данных — тоже содержит глобальные переменные, но в эту область попадают те переменные, которым было задано начальное значение. Неизменяемые данные, включающие в себя переменные, объявленные с модификатором
const
, строковые литералы и другие составные литералы, помещаются в сегмент текста программы. Сегмент текста программы содержит также исполняемый код и доступен только на чтение, поэтому попытка изменения данных из этого сегмента приведёт к неопределённому поведению в виде
ошибки сегментации
.
Область стека предназначена для размещения данных, связанных с
вызовом функций
, и локальных переменных. Перед каждым запуском функции стек увеличивается для размещения в нём аргументов, передаваемых в функцию. В ходе своей работы функция может размещать в стеке локальные переменные и выделять в нём память под массивы переменной длины, а некоторые компиляторы предоставляют также средства выделения памяти в рамках стека посредством вызова
alloca()
, который не входит в стандарт языка. После завершения работы функции стек уменьшается до того значения, которое было перед вызовом, однако этого может не происходить при некорректной работе со стеком. Память, выделенная динамически, предоставляется из
кучи
.
Немаловажной деталью является наличие случайного отступа между стеком и верхней областью , а также между областью инициализированных данных и кучей . Делается это в целях безопасности, например, для предотвращения встраивания в стек других функций.
Динамически подключаемые библиотеки и отображения файлов с файловой системы находятся между стеком и кучей .
Обработка ошибок
В Си отсутствуют какие-либо встроенные механизмы контроля ошибок, но существует несколько общепринятых способов их обработки средствами языка. В общем виде практика обработки ошибок языка Си в отказоустойчивом коде вынуждает писать громоздкие, часто повторяющиеся конструкции, в которых алгоритм совмещён с обработкой ошибок .
Маркеры ошибок и errno
В языке Си активно используется специальная переменная
errno
из заголовочного файла
errno.h
, в которую функции заносят код ошибки, возвращая при этом значение, являющееся маркером ошибки. Для проверки результата на ошибки результат сравнивают с маркером ошибки, и, если они совпадают, то можно проанализировать код ошибки, сохранённый в
errno
, для корректировки работы программы или вывода отладочного сообщения. В стандартной библиотеке стандарт зачастую лишь определяет возвращаемые маркеры ошибок, а выставление
errno
зависит от конкретной реализации
.
В качестве маркеров ошибок обычно выступают следующие значения:
-
-1для типаintв случаях, когда отрицательный диапазон результата не используется ; -
-1для типаssize_t(POSIX) ; -
(size_t) -1для типаsize_t; -
(time_t) -1при использовании некоторых функций для работы со временем ; -
NULLдля указателей ; -
EOFпри потоковой работе с файлами ; - ненулевой код ошибки .
Практика возвращения маркера ошибки, вместо кода ошибки, хоть и экономит количество передаваемых в функции аргументов, но в ряде случаев приводит к ошибкам в результате человеческого фактора. Например, программистами часто игнорируется проверка результата типа
ssize_t
, а сам результат используется дальше в вычислениях, что приводит к трудно уловимым ошибкам, если возвращается
-1
.
Ещё сильнее способствует появлению ошибок возврат в качестве маркера ошибки корректного значения
, что также вынуждает программиста делать больше проверок, а соответственно и писать больше однотипного повторяющегося кода. Такой подход практикуется в потоковых функциях, работающих с объектами типа
FILE *
: маркером ошибки является значение
EOF
, одновременно являясь и маркером конца файла. Поэтому по
EOF
иногда приходится проверять поток символов как на конец файла с помощью функции
feof()
, так и наличие ошибки с помощью
ferror()
. При этом некоторые функции, которые могут вернуть
EOF
по стандарту не обязаны выставлять
errno
.
Отсутствие единой практики обработки ошибок в стандартной библиотеке приводит к появлению собственных способов обработки ошибок и комбинированию часто используемых способов в сторонних проектах. Например, в проекте
systemd
совместили идеи возвращения кода ошибки и числа
-1
в качестве маркера — возвращается отрицательный код ошибки
. А в библиотеке
GLib
ввели в практику возвращение в качестве маркера ошибки значение
булева типа
, в то время как подробная информация об ошибке помещается в специальную структуру, указатель на которую возвращается через последний аргумент функции
. Схожее решение использует проект
Enlightenment
, в котором в качестве маркера тоже используется булев тип, но информация об ошибке возвращается по аналогии со стандартной библиотекой — через отдельную функцию
, которую необходимо проверять, если был возвращён маркер.
Возврат кода ошибки
Альтернативой маркерам ошибок является возвращение кода ошибки напрямую, а результата работы функции — через аргументы по указателю. По такому пути пошли разработчики стандарта POSIX, в функциях которого принято возвращать код ошибки в виде числа типа
int
. Однако возвращение значения типа
int
явно не даёт понять, что возвращается именно код ошибки, а не маркер, что может вести к ошибкам, если результат таких функций будет проверяться на значение
-1
. В расширении K стандарта C11 представлен специальный тип
errno_t
для хранения кода ошибки. Существуют рекомендации использовать именно этот тип в пользовательском коде для возвращения ошибок, а если он не предоставлен стандартной библиотекой, то объявлять его самостоятельно
:
#ifndef __STDC_LIB_EXT1__
typedef int errno_t;
#endif
Такой подход, помимо повышения качества кода, избавляет от необходимости использования
errno
, что позволяет делать библиотеки с
реентерабельными
функциями без необходимости подключения дополнительных библиотек, таких как
POSIX Threads
для правильного определения
errno
.
Ошибки в математических функциях
Более сложной является обработка ошибок в математических функциях из заголовочного файла
math.h
, в которых могут возникать 3 типа ошибок
:
- выход за пределы диапазона входных значений;
- получение бесконечного результата для конечных входных данных;
- выход результата за пределы диапазона используемого типа данных.
Предотвращение двух из трёх типов ошибок сводится к проверкам входных данных на область допустимых значений. Однако предсказать выход результата за пределы типа крайне сложно. Поэтому стандартом языка предусмотрена возможность анализа математических функций на ошибки. Начиная со стандарта C99 такой анализ возможен двумя способами, в зависимости от значения, хранимого в макросе
math_errhandling
.
-
Если выставлен бит
MATH_ERRNO, то переменнуюerrnoнеобходимо предварительно сбросить в0, а после вызова математической функции — проверить на ошибкиEDOMиERANGE. -
Если выставлен бит
MATH_ERREXCEPT, то возможные математические ошибки предварительно сбрасываются функциейfeclearexcept()из заголовочного файлаfenv.h, а после вызова математической функции —тестируются с помощью функцииfetestexcept().
При этом способ обработки ошибок определяется конкретной реализацией стандартной библиотеки и может отсутствовать совсем. Поэтому в платформонезависимом коде может потребоваться проверка результата сразу двумя способами, в зависимости от значения
math_errhandling
.
Освобождение ресурсов
Как правило возникновение ошибки требует завершения работы функции с возвращением индикатора ошибки. Если в функции ошибка может возникнуть в разных её частях, требуется освобождать ресурсы, выделенные в ходе её работы, чтобы предотвратить утечки. Хорошей практикой освобождения ресурсов считается их чистка в обратном порядке перед возвратом из функции, а в случае ошибок — освобождение в обратном порядке после основного
return
. В отдельные части такого освобождения можно сделать переход с помощью оператора
goto
. Подобный подход позволяет вынести не связанные с реализуемым алгоритмом участки кода за пределы самого алгоритма, повышая читабельность кода, и схож с работой оператора
defer
из языка программирования
Go
. Пример освобождения ресурсов приведён ниже, в разделе примеров
.
Для освобождения ресурсов в рамках программы предусмотрен механизм обработчиков выхода из программы. Обработчики назначаются с помощью функции
atexit()
и исполняются как по завершении функции
main()
через оператор
return
, так и по исполнению функции
exit()
. При этом обработчики не исполняются по функциям
abort()
и
_Exit()
.
В качестве примера освобождения ресурсов по завершении программы можно привести освобождение памяти, выделенной под глобальные переменные. Несмотря на то, что память так или иначе освобождается по завершении работы программы операционной системой, и допускается не освобождать ту память, которая требуется на протяжении всей работы программы , явное освобождение предпочтительнее, так как облегчает поиск утечек памяти сторонними средствами и уменьшает шанс на возникновение утечек памяти в результате ошибки:
#include <stdio.h>
#include <stdlib.h>
int numbers_count;
int *numbers;
void free_numbers(void)
{
free(numbers);
}
int main(int argc, char **argv)
{
if (argc < 2) {
exit(EXIT_FAILURE);
}
numbers_count = atoi(argv[1]);
if (numbers_count <= 0) {
exit(EXIT_FAILURE);
}
numbers = calloc(numbers_count, sizeof(*numbers));
if (!numbers) {
perror("Ошибка выделения памяти под массив");
exit(EXIT_FAILURE);
}
atexit(free_numbers);
// ... работа с массивом numbers
// Здесь будет автоматически вызван обработчик free_numbers()
return EXIT_SUCCESS;
}
Недостатком данного подхода является то, что формат назначаемых обработчиков не предусматривает передачу произвольных данных в функцию, что позволяет создавать обработчики только для глобальных переменных.
Примеры программ на Си
Минимальная программа на Си
Минимальная программа на Си, не требующая обработки аргументов, имеет следующий вид:
int main(void){}
Допускается не писать оператор
return
у функции
main()
. В таком случае, согласно стандарту, функция
main()
возвращает 0, исполняя все обработчики, назначенные на функцию
exit()
. При этом подразумевается, что программа успешно завершилась
.
Hello, world!
Программа Hello, world! приведена ещё в первом издании книги « Язык программирования Си » Кернигана и Ритчи:
#include <stdio.h>
int main(void) // Не принимает аргументы
{
printf("Hello, world!\n"); // '\n' - новая строка
return 0; // Удачное завершение программы
}
Эта программа печатает сообщение « Hello, world! » на стандартном устройстве вывода .
Обработка ошибок на примере чтения файла
Многие функции языка Си могут вернуть ошибку, не выполнив требуемых от них действий. Ошибки требуется проверять и правильно на них реагировать, в том числе часто требуется пробрасывать ошибку из функции на уровень выше для анализа. При этом функцию, в которой произошла ошибка, можно делать реентерабельной , в таком случае по ошибке функция не должна изменять входные или выходные данные, что позволяет безопасно перезапускать её после исправления ошибочной ситуации.
В примере реализована функция чтения файла на языке Си, однако она требует соответствия функций
fopen()
и
fread()
стандарту
POSIX
, иначе они могут не выставлять переменную
errno
, что сильно усложняет как отладку, так и написание универсального и безопасного кода. На платформах, не соответствующих POSIX, поведение данной программы будет неопределённым в случае ошибки
. Освобождение ресурсов по ошибкам находится за основным алгоритмом для повышения читабельности, а переход осуществляется с помощью
goto
.
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
// Определяем тип для хранения кода ошибки, если он не определён
#ifndef __STDC_LIB_EXT1__
typedef int errno_t;
#endif
enum {
EOK = 0, // значение errno_t при успешном завершении
};
// Функция чтения содержимого файла
errno_t get_file_contents(const char *filename,
void **contents_ptr,
size_t *contents_size_ptr)
{
FILE *f;
f = fopen(filename, "rb");
if (!f) {
// В POSIX fopen() выставляет errno по ошибке
return errno;
}
// Получаем размер файла
fseek(f, 0, SEEK_END);
long contents_size = ftell(f);
if (contents_size == 0) {
*contents_ptr = NULL;
*contents_size_ptr = 0;
goto cleaning_fopen;
}
rewind(f);
// Переменная для хранения возвращаемого кода ошибки
errno_t saved_errno;
void *contents;
contents = malloc(contents_size);
if (!contents) {
saved_errno = errno;
goto aborting_fopen;
}
// Читаем содержимое файла целиком по указателю contents
size_t n;
n = fread(contents, contents_size, 1, f);
if (n == 0) {
// Не проверяем на feof(), т. к. буферизировано после fseek()
// В POSIX fread() выставляет errno по ошибке
saved_errno = errno;
goto aborting_contents;
}
// Возвращаем выделенную память и её размер
*contents_ptr = contents;
*contents_size_ptr = contents_size;
// Секция освобождения ресурсов по успешному завершению
cleaning_fopen:
fclose(f);
return EOK;
// Отдельная секция для освобождения ресурсов по ошибке
aborting_contents:
free(contents);
aborting_fopen:
fclose(f);
return saved_errno;
}
int main(int argc, char **argv)
{
if (argc < 2) {
return EXIT_FAILURE;
}
const char *filename = argv[1];
errno_t errnum;
void *contents;
size_t contents_size;
errnum = get_file_contents(filename, &contents, &contents_size);
if (errnum) {
char buf[1024];
const char *error_text = strerror_r(errnum, buf, sizeof(buf));
fprintf(stderr, "%s\n", error_text);
exit(EXIT_FAILURE);
}
printf("%.*s", (int) contents_size, contents);
free(contents);
return EXIT_SUCCESS;
}
Средства разработки
Компиляторы
Некоторые компиляторы идут в комплекте с компиляторами других языков программирования (включая C++ ) или являются составной частью среды разработки программного обеспечения .
- GNU Compiler Collection (GCC) полностью поддерживает стандарты C99 и C17 ( C11 с исправлениями) . Также поддерживает расширения GNU, защиту кода с помощью санитайзеров и набор дополнительных возможностей, в том числе атрибуты.
- Clang также полностью поддерживает стандарты C99 и C17 . Разрабатывается во многом совместимым с компилятором GCC, в том числе поддерживает расширения GNU и защиту кода санитайзерами.
Реализации стандартной библиотеки
Несмотря на то, что стандартная библиотека входит в стандарт языка, её реализации идут отдельно от компиляторов. Поэтому стандарты языка, поддерживаемые компилятором и библиотекой, могут различаться.
- Открытая библиотека glibc является основной во многих дистрибутивах GNU/Linux , поддерживает стандарты C11 и POSIX.1-2008 , а также предоставляет набор исправлений и дополнительных возможностей от GNU .
- Открытая библиотека musl задумывалась в качестве более легковесной замены для glibc, используется как библиотека по умолчанию в дистрибутиве Alpine Linux , Void Linux .
- Библиотека CRT от Microsoft поддерживает стандарт C99, поставляется как компонент в составе Windows 10 .
Интегрированные среды разработки
- CLion полностью поддерживает C99, но поддержка С11 — частичная , сборка основана на CMake.
- Code::Blocks — свободная кроссплатформенная интегрированная среда разработки для языков Си, C++, D, Fortran. Поддерживает более двух десятков компиляторов. С компилятором GCC доступен Си всех версий от C90 до C17.
- Eclipse — свободная интегрированная среда разработки, поддерживающая язык Си стандарта С99. Имеет модульную архитектуру, что даёт возможность подключения поддержки разных языков программирования и дополнительных возможностей. Доступен модуль для интеграции с Git , однако отсутствует интеграция с CMake .
- KDevelop — свободная интегрированная среда разработки, поддерживающая некоторые особенности языка Си из стандарта C11. Позволяет управлять проектами, использующими разные языки программирования, включая C++ и Python , поддерживает систему сборки CMake. Имеет встроенную поддержку Git на уровне работы с файлами и настраиваемое форматирование исходного кода для разных языков.
- Microsoft Visual Studio лишь частично поддерживает стандарты C99 и C11, поскольку ориентируется на разработку под C++, однако имеет встроенную поддержку CMake.
Средства модульного тестирования
Поскольку язык Си не предоставляет средств для безопасного написания кода, а многие элементы языка способствуют появлению ошибок, написание качественного и отказоустойчивого кода можно гарантировать только с помощью создания автоматизированных тестов. Для упрощения такого тестирования существуют различные реализации сторонних библиотек модульного тестирования .
-
Библиотека
Check
предоставляет
фреймворк
для тестирования программного кода на языке Си в общепринятом стиле
xUnit
. Среди возможностей можно упомянуть запуск тестов в отдельных процессах через
fork(), что позволяет распознавать в тестах ошибки сегментирования , а также даёт возможность задавать максимальное время исполнения отдельных тестов. - Библиотека Google Test также предоставляет тестирование по принципам xUnit, но предназначена для тестирования кода на языке C++ , что позволяет её использовать для тестирования кода и на языке Си. Также поддерживает изолированное тестирование отдельных частей программы. Одним из достоинств библиотеки является разделение макросов тестирования на утверждения и ошибки, что может облегчить отладку кода.
Существует также много других систем для тестирования кода на Си, таких как AceUnit, GNU Autounit, cUnit и других, но они либо не осуществляют тестирование в изолированных окружениях, либо предоставляют мало возможностей , либо перестали развиваться.
Средства отладки
По проявлениям ошибок не всегда можно сделать однозначный вывод о проблемном месте в коде, однако локализовать проблему часто помогают различные средства отладки.
- Gdb — интерактивный консольный отладчик для различных языков, в том числе и для Си.
- Valgrind является средством динамического анализа кода , может выявлять ошибки в коде непосредственно во время выполнения программы. Поддерживает выявление: утечек, обращений в неинициализированную память, обращений по неверным адресам (в том числе переполнение буфера). Также поддерживает исполнение в режиме профилирования с помощью профайлера callgrind .
- — графический интерфейс для визуализации результатов профилирования, полученных с помощью профайлера callgrind .
Компиляторы на динамические языки и платформы
Иногда, в целях переноса тех или иных библиотек, функций и инструментов, написанных на Си, в иную среду, требуется компиляция Си-кода на язык более высокого уровня или в код виртуальной машины , предназначенной для такого языка. Следующие проекты предназначены для этих целей:
- Emscripten — компилятор из LLVM-байт-кода (например, полученный из C++ ) в JavaScript .
- (старое название — Alchemy) — компилятор из Си/ C++ в ActionScript Virtual Machine (AVM2). Позволяет использовать Си-библиотеки в Flash - и Adobe AIR -приложениях.
- Clue — компилятор из ANSI Си в Lua , JavaScript , Perl , Java , Common Lisp .
- AMPC — компилятор из Си в виртуальную машину Java .
Дополнительные инструменты
Также для Си существуют и другие инструменты, облегчающие и дополняющие разработку, включая статические анализаторы и утилиты для форматирования кода. Статический анализ помогает выявлять потенциальные ошибки и уязвимости. А автоматическое форматирование кода упрощает организацию совместной работы в системах контроля версий, минимизируя конфликты из-за стилевых правок.
- Cppcheck — статический анализатор кода для языков Си и C++ с открытыми исходными текстами , иногда выдаёт ложные срабатывания, которые можно подавлять специально оформленными комментариями в коде.
- — утилита командной строки для форматирования исходного кода согласно заданному стилю, который может указываться в специально оформленном файле конфигурации. Обладает множеством параметров и несколькими встроенными стилями. Разрабатывается в рамках проекта Clang .
- Утилиты и GNU Indent также предоставляют форматирование кода, но параметры форматирования задаются в виде опций командной строки .
Область применения
Язык широко применяется при разработке операционных систем, на уровне прикладного интерфейса операционных систем, во встраиваемых системах, а также для создания высокопроизводительного или критического в плане обработки ошибок кода. Одной из причин широкого распространения для программирования на низком уровне является возможность писать кроссплатформенный код, который может по-разному обрабатываться на разном оборудовании и на разных операционных системах.
Возможность писать высокопроизводительный код обеспечивается за счёт полной свободы действий программиста и отсутствия строгого контроля со стороны компилятора. Так, например, на языке Си написаны первые реализации языков Java , Python , Perl и PHP . При этом во многих программах наиболее требовательные к ресурсам части принято писать на языке Си. Ядро программы Mathematica написано на Си, а MATLAB , изначально написанный на Фортране , был переписан на Си в 1984 году .
Также Си иногда используется как промежуточный язык при компиляции более высокоуровневых языков. Например, по такому принципу работали первые реализации языков C++ , Objective-C и Go , — код, написанный на этих языках, транслировался в промежуточное представление на языке Си. Современными языками, работающими по такому же принципу, являются язык Vala и Nim .
Ещё одной областью применения языка Си являются приложения реального времени , которые требовательны по части отзывчивости кода и времени его исполнения. Такие приложения должны начинать исполнение действий в жёстко ограниченных временных рамках, а сами действия должны укладываться в определённый временной промежуток. В частности, стандарт POSIX.1 предоставляет набор функций и возможностей для создания приложений реального времени , однако поддержка жёсткого реального времени должна быть также реализована и со стороны операционной системы .
Языки-потомки
Язык Си был и остаётся одним из самых распространённых языков программирования в течение более чем сорока лет. Естественно, что его влияние можно проследить в той или иной мере во многих более поздних языках. Тем не менее среди языков, достигших определённого распространения, прямых потомков у Си немного.
Часть языков-потомков надстраивает Си дополнительными средствами и механизмами, добавляющими поддержку новых парадигм программирования ( ООП , функциональное программирование , обобщённое программирование и пр.). К таким языкам относятся, прежде всего, C++ и Objective-C , а опосредованно — их потомки Swift и D . Также известны попытки улучшить Си, исправив его наиболее существенные недостатки, но сохранив его привлекательные черты. Среди них можно упомянуть исследовательский язык Cyclone (и его потомок Rust ). Иногда оба направления развития объединяются в одном языке, примером может служить Go .
Отдельно необходимо упомянуть о целой группе языков, которые в большей или меньшей мере унаследовали базовый синтаксис Си (использование фигурных скобок в качестве ограничителей блоков кода, описание переменных, характерные формы операторов
for
,
while
,
if
,
switch
с параметрами в скобках, комбинированные операции
++
,
--
,
+=
,
-=
и другие), из-за чего программы на этих языках имеют характерный внешний вид, ассоциирующийся именно с Си. Это такие языки как
Java
,
JavaScript
,
PHP
,
Perl
,
AWK
,
C#
. В действительности структура и семантика этих языков сильно отличается от Си, и обычно они предназначены для тех сфер применения, где оригинальный Си никогда не использовался.
C++
Язык программирования C++ был создан из Си и унаследовал его синтаксис, дополнив его новыми конструкциями в духе языков Simula-67, Smalltalk, Modula-2, Ada, Mesa и Clu . Основными дополнениями стали поддержка ООП (описание классов, множественное наследование, полиморфизм, основанный на виртуальных функциях) и обобщённого программирования (механизм шаблонов). Но помимо этого в язык внесено множество самых различных дополнений. На данный момент C++ является одним из наиболее распространённых языков программирования в мире и позиционируется как язык общего назначения с уклоном в системное программирование .
Изначально C++ сохранял совместимость с Си, которая была заявлена как одно из преимуществ нового языка. Первые реализации C++ просто переводили новые конструкции в чистый Си, после чего код обрабатывался обычным Си-компилятором. Для сохранения совместимости создатели C++ отказались от исключения из него некоторых часто критикуемых особенностей Си, вместо этого создав новые, «параллельные» механизмы, которые рекомендуется применять при разработке нового кода на C++ (шаблоны вместо макроопределений, явное приведение типов вместо автоматического, контейнеры стандартной библиотеки вместо ручного динамического выделения памяти и так далее). Однако в дальнейшем языки развивались независимо, и сейчас Си и C++ последних выпущенных стандартов являются лишь частично совместимыми: не гарантируется успешная компиляция программы на Си компилятором C++, а в случае успеха нет гарантии, что откомпилированная программа будет работать правильно. Особенно неприятны некоторые тонкие семантические различия, которые могут приводить к разному поведению одного и того же кода, синтаксически корректного для обоих языков. Например, символьные константы (символы, заключённые в одинарные кавычки) имеют тип
int
в Си и тип
char
в
C++
, так что объём памяти, занимаемый такими константами, в разных языках различается.
Если программа чувствительна к размеру символьной константы, она будет работать по-разному, будучи откомпилирована трансляторами Си и C++.
Подобные различия затрудняют написание программ и библиотек, которые могли бы нормально компилироваться и работать одинаково и в Си и в C++ , что, конечно, запутывает тех, кто программирует на обоих языках. Среди разработчиков и пользователей как Си, так и C++ есть сторонники максимального сокращения различий между языками, что объективно принесло бы ощутимую пользу. Существует, однако, и противоположная точка зрения, согласно которой совместимость не особенно важна, хоть и полезна, и усилия по уменьшению несовместимости не должны препятствовать улучшению каждого языка в отдельности.
Objective-C
Ещё одним вариантом расширения Си объектными средствами является язык Objective-C , созданный в 1983 году. Объектная подсистема была заимствована из Smalltalk , причём все элементы, связанные с этой подсистемой, реализованы в собственном синтаксисе, достаточно резко отличающемся от синтаксиса Си (вплоть до того, что в описании классов синтаксис объявления полей противоположен синтаксису описания переменных в Си: сначала пишется имя поля, затем его тип). В отличие от C++, Objective-C является надмножеством классического Си, то есть сохраняет совместимость с исходным языком; правильная программа на Си является правильной программой на Objective-C. Другим существенным отличием от идеологии C++ является то, что Objective-C реализует взаимодействие объектов путём обмена полноценными сообщениями, тогда как в C++ реализована концепция «отправка сообщения как вызов метода». Полноценная обработка сообщений является значительно более гибкой, к тому же она естественным образом сочетается с параллельными вычислениями. Objective-C, а также его прямой потомок Swift являются одними из самых популярных на платформах, поддерживаемых Apple .
Проблемы и критика
Язык Си уникален с той точки зрения, что именно он стал первым языком высокого уровня , всерьёз потеснившим ассемблер в разработке системного программного обеспечения . Он остаётся языком, реализованным на максимальном количестве аппаратных платформ , и одним из самых популярных языков программирования , особенно в мире свободного программного обеспечения . Тем не менее язык имеет множество недостатков, он с момента появления подвергается критике многих специалистов.
Общая критика
Язык весьма сложен и наполнен опасными элементами, которые очень легко использовать неправильно. Своей структурой и правилами он никак не поддерживает программирование, нацеленное на создание надёжного и удобного в сопровождении программного кода, напротив, рождённый в эпоху прямого программирования под различные процессоры, язык способствует написанию небезопасного и запутанного кода . Многие профессиональные программисты склонны считать, что язык Си — мощный инструмент для создания элегантных программ, но в то же время с его помощью можно создавать крайне некачественные решения .
Из-за различных допущений в языке программы могут компилироваться со множественными ошибками, что часто приводит к непредсказуемому поведению программы. Современные компиляторы предоставляют опции для статического анализа кода , но даже они не способны выявить все возможные ошибки. Результатом неграмотного программирования на Си могут стать уязвимости программного обеспечения, что может сказаться на безопасности его использования.
У Си высокий порог вхождения
. Спецификация его занимает более 500 страниц текста, которые необходимо изучить полностью, так как для создания безошибочного и качественного кода приходится учитывать многие неочевидные особенности языка. Например, автоматическое приведение операндов целочисленных выражений к типу
int
может давать трудно предсказуемые результаты при использовании бинарных операторов
:
unsigned char x = 0xFF;
unsigned char y = (~x | 0x1) >> 1; // Интуитивно здесь ожидается 0x00
printf("y = 0x%hhX\n", y); // Будет выведено 0x80, если sizeof(int) > sizeof(char)
Недостаточное понимание подобных нюансов может приводить к появлению многочисленных ошибок и уязвимостей. Ещё одним фактором, увеличивающим сложность освоения Си, является отсутствие обратной связи от компилятора: язык даёт программисту полную свободу действий и позволяет компилировать программы с явными логическими ошибками. Всё это затрудняет использование Си в обучении в качестве первого языка программирования
Наконец, за более чем 40 лет существования язык успел несколько устареть, и в нём достаточно проблематично использовать многие современные приёмы и парадигмы программирования .
Недостатки отдельных элементов языка
Примитивная поддержка модульности
В синтаксисе Си нет модулей и механизмов их взаимодействия. Файлы исходного кода компилируются раздельно и должны включать прототипы импортируемых из других файлов переменных, функций и типов данных. Для этого используется включение заголовочных файлов через макроподстановку
#include
. В случае нарушения соответствия между файлами кода и заголовочными файлами могут возникать как ошибки этапа компоновки, так и всевозможные ошибки времени исполнения: от порчи
стека
и
кучи
до
ошибок сегментирования
. Поскольку директива
#include
лишь подставляет текст одного файла в другой, включение большого количества заголовочных файлов приводит к тому, что многократно возрастает фактический объём кода, попадающего на компиляцию, что является причиной относительно низкой скорости работы компиляторов языка Си. Необходимость согласования описаний в основном модуле и заголовочных файлах затрудняет сопровождение программы.
Предупреждения вместо ошибок
Стандарт языка даёт программисту большую свободу действий и тем самым — высокие шансы на допущение ошибок. Многое из того, что чаще всего нельзя делать, дозволено языком, и компилятор в лучшем случае выдаёт предупреждения. Хотя современные компиляторы позволяют переводить все предупреждения в класс ошибок, эта возможность используется редко, гораздо чаще предупреждения игнорируются, если программа работает удовлетворительно.
Так, например, до стандарта C99 вызов функции
malloc
без подключения заголовочного файла
stdlib.h
мог привести к порче стека, поскольку в отсутствие прототипа функция вызывалась как возвращающая тип
int
, тогда как фактически она возвращала тип
void*
(ошибка возникала, когда размеры типов на целевой платформе различались). Но даже при этом выдавалось всего лишь предупреждение.
Отсутствие контроля инициализации переменных
Автоматически и динамически создаваемые объекты по умолчанию не инициализируются и после создания содержат значения, оставшиеся в памяти от ранее находившихся там объектов. Такое значение полностью непредсказуемо, оно меняется от одной машины к другой, от запуска к запуску, от вызова функции к вызову. Если программа из-за случайного пропуска инициализации использует такое значение, то результат будет непредсказуемым и может проявиться не сразу. Современные компиляторы пытаются диагностировать эту проблему статическим анализом исходного кода, хотя в общем случае статическим анализом данную проблему решить крайне сложно. Для выявления данных проблем на этапе тестирования в ходе исполнения программы могут использоваться дополнительные инструменты: Valgrind и .
Отсутствие контроля над адресной арифметикой
Источником опасных ситуаций служит совместимость указателей с числовыми типами и возможность использования адресной арифметики без строгого контроля на этапах компиляции и исполнения. Это даёт возможность получить указатель на любой объект, включая исполняемый код, и обратиться по этому указателю, если только механизм защиты памяти системы этому не воспрепятствует.
Неправильное использование указателей может порождать неопределённое поведение программы и приводить к серьёзным последствиям. К примеру, указатель может быть неинициализированным или, в результате неверных арифметических операций, указывать в произвольное место памяти. На одних платформах работа с таким указателем может вызвать принудительную остановку программы, на других это может привести к порче произвольных данных в памяти; последняя ошибка опасна тем, что её последствия непредсказуемы и могут проявиться в произвольный момент времени, в том числе намного позже момента собственно ошибочного действия.
Доступ к массивам в Си также реализован посредством адресной арифметики и не предполагает средств проверки корректности обращения к элементам массива по индексу. Например, выражения
a[i]
и
i[a]
идентичны и просто транслируются к виду
*(a + i)
, а проверка на выход за границы массива не проводится. Обращение по индексу, превышающему верхнюю границу массива, приводит к обращению к данным, размещённым в памяти после массива, что называют
переполнением буфера
. Когда подобное обращение происходит ошибочно, оно может привести к непредсказуемому поведению программы
. Нередко данная особенность используется в
эксплоитах
, используемых для нелегального доступа к памяти другого приложения или памяти ядра операционной системы.
Побуждающая к ошибкам динамическая память
Системные функции для работы с динамически выделяемой памятью не обеспечивают контроля за правильностью и своевременностью её выделения и освобождения, соблюдение правильного порядка работы с динамической памятью полностью возлагается на программиста. Его ошибки, соответственно, могут приводить к обращению по некорректным адресам, к преждевременному освобождению либо к
утечке
памяти (последнее возможно, например, если разработчик забыл вызвать
free()
или вызывающую
free()
функцию, когда это требовалось)
.
Одной из частых ошибок является отсутствие проверок результата работы функций выделения памяти (
malloc()
,
calloc()
и прочие) на
NULL
, в то время как память может не выделиться, если её не хватает, или если был запрошен слишком большой объём, например, из-за приведения числа
-1
, полученного в результате каких-либо ошибочных математических операций, к беззнаковому типу
size_t
, с последующими операциями над ним
. Ещё одной проблемой системных функций работы с памятью является неспецифицированное поведение при запросе выделения блока нулевого размера: функции могут вернуть как
NULL
, так и действительное значение указателя, в зависимости от конкретной реализации
.
Некоторые конкретные реализации и сторонние библиотеки предоставляют такие средства, как подсчёт ссылок и слабые ссылки , умные указатели , а также ограниченные формы сборки мусора , но все эти средства не являются стандартными, что, естественно, ограничивает их применение.
Неэффективные и небезопасные строки
Для языка стандартными являются
нуль-терминированные строки
, соответственно все стандартные функции работают именно с ними. Это решение приводит к значительной потере эффективности за счёт малозначительной экономии памяти (по сравнению с явным хранением размера): вычисление длины строки (функция
strlen()
) требует обхода в цикле всей строки от начала до конца, копирование строк также сложно оптимизировать из-за наличия терминирующего нуля
. Из-за необходимости добавлять к данным строки терминирующий нуль становится невозможным эффективное получение подстрок в виде срезов и работа с ними как с обычными строками; выделение частей строк и манипуляции с ними обычно требуют ручного выделения и освобождения памяти, что дополнительно повышает вероятность ошибки.
Нуль-терминированные строки являются частым источником ошибок . Даже стандартные функции обычно не выполняют проверки на размер целевого буфера и могут не добавлять в конце строки нулевой символ , не говоря уже о том, что он может быть не добавлен или затёрт из-за ошибки программиста. .
Небезопасная реализация функций с переменным числом аргументов
Поддерживая
функции с переменным числом аргументов
, Си не содержит ни средств определения числа и типов фактических параметров, переданных такой функции, ни механизма безопасного доступа к ним
. Информирование функции о составе фактических параметров лежит на программисте, а для доступа к их значениям необходимо отсчитать правильное количество байтов от адреса последнего фиксированного параметра в стеке либо вручную, либо пользуясь набором макросов
va_arg
из заголовочного файла
stdarg.h
. При этом необходимо учитывать работу механизма автоматического неявного повышения типов при вызове функций
, согласно которому целочисленные типы аргументов размером менее
int
приводятся к
int
(или
unsigned int
), а
float
приводится к
double
. Ошибка в вызове или в работе с параметрами внутри функции проявится только во время исполнения программы, приводя к непредсказуемым последствиям, от чтения неверных данных до порчи стека.
При этом стандартным средством форматированного ввода-вывода являются именно функции с переменным числом параметров (
printf
()
,
scanf()
и другие), не способные проверить соответствие списка аргументов строке формата. Многие современные компиляторы проводят такую проверку для каждого их вызова, генерируя предупреждения при обнаружении несоответствия, однако в общем случае подобная проверка невозможна, так как каждая функция с переменным числом аргументов обрабатывает этот список по-своему. Невозможно статически проконтролировать даже все вызовы функции
printf()
, поскольку строка формата может создаваться в программе динамически.
Отсутствие унификации обработки ошибок
Синтаксис Си не включает специального механизма обработки ошибок. Стандартная библиотека поддерживает лишь простейшие средства: переменная (в случае
POSIX
— макрос)
errno
из заголовочного файла
errno.h
для установки кода последней ошибки и функции для получения сообщений об ошибках согласно кодам.
Такой подход приводит к необходимости писать большой объём повторяющегося кода, смешивая основной алгоритм с обработкой ошибок, к тому же он не является потокобезопасным. Причём даже в этом механизме нет единого порядка:
-
большинство функций стандартной библиотеки при ошибке возвращает маркер
-1, а сам код требуется получать изerrno, если функция его выставляет; - в стандарте POSIX принято возвращать код ошибки напрямую, но не все функции этого стандарта так делают;
-
во многих функциях, например,
fopen(),fread()иfwrite(), выставлениеerrnoне стандартизировано и может отличаться в разных реализациях (в POSIX требования более строгие и указаны некоторые из вариантов возможных ошибок ); -
есть функции, у которых маркер ошибки является одним из допустимых возвращаемых значений, и перед их вызовом приходится обнулять
errno, чтобы быть уверенным, что код ошибки был установлен именно этой функцией .
В стандартной библиотеке коды
errno
обозначаются через макроопределения и могут иметь одинаковые значения, что не даёт возможности анализировать коды ошибок через оператор
switch
. В языке нет специального типа данных для флагов и кодов ошибок, они передаются как значения типа
int
. Отдельный тип
errno_t
для хранения кода ошибки появился лишь в расширении K стандарта C11 и может не поддерживаться компиляторами
.
Способы преодоления недостатков языка
Недостатки Си давно и хорошо известны, и с момента появления языка предпринималось множество попыток повысить качество и безопасность кода на Си, не принося в жертву его возможности.
Средства анализа корректности кода
Практически все современные компиляторы Си позволяют проводить ограниченный статический анализ кода с выдачей предупреждений о потенциальных ошибках. Также поддерживаются опции встраивания в код проверок выхода за пределы массива, разрушения стека, выхода за пределы динамической памяти, чтения неинициализированных переменных, возможностей неопределённого поведения и т. п. Однако дополнительные проверки могут сказаться на производительности итогового приложения, поэтому чаще всего их применяют только на этапе отладки.
Существуют специальные программные средства для статического анализа кода на Си для выявления не-синтаксических ошибок. Их применение не гарантирует безошибочности программ, но позволяет выявить значительную часть типичных ошибок и потенциальных уязвимостей. Максимальный эффект данных средств достигается не при эпизодическом использовании, а при применении в составе отработанной системы постоянного контроля качества кода, например, в системах непрерывной интеграции и развёртывания. Также может требоваться аннотирование кода специальными комментариями, чтобы исключить ложные срабатывания анализатора на корректных участках кода, формально попадающих под критерии ошибочных.
Стандарты безопасного программирования
Выпущено значительное количество исследований о правильном программировании на Си, от небольших статей до объёмных книг. Для поддержания качества кода на Си принимаются корпоративные и отраслевые стандарты. В частности:
- MISRA C — стандарт, разработанный Motor Industry Software Reliability Association для использования Си в разработке встроенных систем транспортных средств. Сейчас MISRA C используется во многих отраслях, в том числе в военной, медицинской и аэрокосмической. Редакция 2013 года содержит 16 директив и 143 правила, включающие требования к коду и ограничения на использование определённых языковых средств (например, запрещено использование функций с переменным числом параметров). На рынке имеется около десятка инструментов проверки кода на соответствие MISRA C и несколько компиляторов со встроенной проверкой ограничений этого стандарта.
- — стандарт, разрабатываемый координационным центром CERT . Он также имеет целью обеспечение надёжного и безопасного программирования на Си. Включает правила и рекомендации для разработчиков, в том числе примеры неправильного и правильного кода по каждому отдельно взятому случаю. Стандарт используется в разработке продуктов такими компаниями как Cisco и Oracle .
Стандарты POSIX
Компенсации некоторых недостатков языка способствует набор стандартов
POSIX
. Стандартизируется установка
errno
многими функциями, позволяя обрабатывать ошибки, возникающие, например, в функциях работы с файлами, а также вводятся
потокобезопасные
аналоги некоторых функций стандартной библиотеки, безопасные варианты которых в стандарте языка присутствуют лишь в расширении K
.
См. также
Примечания
Комментарии
- B — вторая буква английского алфавита , а C — третья буква английского алфавита .
-
↑
Первое появление знаковых и беззнаковых типов
char,short,intиlongбыло в K&R C. -
↑
Соответствие формата типов
floatиdoubleстандарту IEC 60559 определяется расширением F стандарта Си, поэтому формат может отличаться на отдельных платформах или компиляторах. -
Макрос
alignofиз заголовочного файла_Alignof.
Источники
- ↑
- Rui Ueyama. (англ.) . www.sigbus.info (декабрь 2015). Дата обращения: 18 февраля 2019. 23 марта 2019 года.
- от 13 октября 2005 на Wayback Machine (англ.)
- от 6 марта 2016 на Wayback Machine (англ.)
- (англ.) . GObject Reference Manual . developer.gnome.org. Дата обращения: 27 мая 2019. 27 мая 2019 года.
- (англ.) . GObject Reference Manual . developer.gnome.org. Дата обращения: 27 мая 2019. 27 мая 2019 года.
- David R Sutton . : [ англ. ] / David R Sutton, John Fox // Journal of the American Medical Informatics Association . — 2003, 4 June . — Vol. 10, iss. 5. — P. 433—443. — ISSN , . — doi : . — PMID . — WD .
- ↑ , 1.1 The C programming language, p. 4.
- Ritchie Dennis M. : [ англ. ] // ACM SIGPLAN Notices : Proceedings of the 32nd ACM SIGPLAN-SIGACT symposium on Principles of programming languages. — 1993, 1 March . — Vol. 28, iss. 3. — P. 201—208. — Дата обращения: 22 января 2023. — ISSN . — doi : . — WD .
- , 2.1 Selected issues from the syntax and semantics of C, p. 17-18.
- . www.gnu.org. Дата обращения: 21 мая 2017. 27 апреля 2021 года.
- (англ.) . www.gnu.org. Дата обращения: 7 декабря 2018. 9 декабря 2018 года.
- , 6.2.5 Types, с. 31.
- ↑ Joint Technical Committee ISO/IEC JTC 1. . — ISO/IEC, 2011. — С. 14. — 678 с. 30 мая 2017 года. от 30 мая 2017 на Wayback Machine
- (англ.) . Check . check.sourceforge.net. Дата обращения: 11 февраля 2019. 18 мая 2018 года.
- (англ.) . developer.gnome.org. Дата обращения: 14 января 2019. 14 января 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 22 февраля 2019. 7 августа 2021 года.
- ↑ (англ.) . wiki.sei.cmu.edu. Дата обращения: 22 февраля 2019. 22 февраля 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 21 мая 2019. 7 августа 2021 года.
- ↑ , IEC 60559 floating-point arithmetic, с. 370.
- , 7.12 Mathematics <math.h>, с. 169—170.
- ↑ Poul-Henning Kamp. (англ.) . queue.acm.org (25 июля 2011). Дата обращения: 28 мая 2019. 30 апреля 2019 года.
- , с. 19.
- ↑ (англ.) . man7.org. Дата обращения: 24 февраля 2019. 25 февраля 2019 года.
- ↑ (англ.) . www.gnu.org. Дата обращения: 2 января 2019. 17 сентября 2019 года.
- (англ.) . Linux.com | The source for Linux information (11 февраля 2006). Дата обращения: 7 июня 2019. 7 июня 2019 года.
- . (англ.) . www.cl.cam.ac.uk. Дата обращения: 25 февраля 2019. 27 февраля 2019 года.
- . www.open-std.org. Дата обращения: 2 января 2019. 1 января 2019 года.
- , с. 84.
- (англ.) . developer.gnome.org. Дата обращения: 15 января 2019. 14 января 2019 года.
- (англ.) . developer.gnome.org. Дата обращения: 15 января 2019. 16 января 2019 года.
- (англ.) . gcc.gnu.org. Дата обращения: 19 января 2019. 16 января 2019 года.
- ↑ (англ.) . wiki.sei.cmu.edu. Дата обращения: 30 мая 2019. 30 мая 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 18 февраля 2019. 19 февраля 2019 года.
- , 6.7.9 Initialization, с. 101.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 21 февраля 2019. 22 февраля 2019 года.
- (англ.) . www.openssl.org. Дата обращения: 9 декабря 2018. 9 декабря 2018 года.
- (англ.) . developer.gnome.org. Дата обращения: 9 декабря 2018. 16 ноября 2018 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 9 декабря 2018. 9 декабря 2018 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 9 декабря 2018. 9 декабря 2018 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 25 мая 2019. 25 мая 2019 года.
- ↑ , 5.1.2.2 Hosted environment, с. 10—11.
- ↑ , 6.2.4 Storage durations of objects, с. 30.
- ↑ , 7.22.4.4 The exit function, с. 256.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 24 мая 2019. 24 мая 2019 года.
- , 6.7.1 Storage-class specifiers, с. 79.
- , 6.7.6.3 Function declarators (including prototypes), с. 96.
- . www.viva64.com. Дата обращения: 30 декабря 2018. 30 декабря 2018 года.
- Таненбаум Эндрю С, Бос Херберт. . — СПб. : Издательский дом "Питер", 2019. — С. 828. — 1120 с. — (Классика "Computer science"). — ISBN 9785446111558 . 7 августа 2021 года. от 7 августа 2021 на Wayback Machine
- Jonathan Corbet. (англ.) . lwn.net (28 июня 2017). Дата обращения: 25 мая 2019. 25 мая 2019 года.
- (англ.) . www.redhat.com. Дата обращения: 25 мая 2019. 25 мая 2019 года.
- (англ.) . www.openbsd.org. Дата обращения: 4 марта 2019. 8 декабря 2019 года.
- Dr Thabang Mokoteli. . — Academic Conferences and publishing limited, 2017-03. — С. 42. — 567 с. — ISBN 9781911218289 . 7 августа 2021 года. от 7 августа 2021 на Wayback Machine
- (англ.) . www.openbsd.org. Дата обращения: 4 марта 2019. 8 декабря 2019 года.
- ↑ (англ.) . wiki.sei.cmu.edu. Дата обращения: 23 мая 2019. 19 ноября 2018 года.
- ↑ (англ.) . wiki.sei.cmu.edu. Дата обращения: 23 мая 2019. 23 мая 2019 года.
- (англ.) . man7.org. Дата обращения: 23 мая 2019. 23 мая 2019 года.
- ↑ (англ.) . wiki.sei.cmu.edu. Дата обращения: 4 января 2019. 5 января 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 4 января 2019. 4 января 2019 года.
- (англ.) . The systemd System and Service Manager . github.com. Дата обращения: 1 февраля 2019. 31 декабря 2020 года.
- (англ.) . developer.gnome.org. Дата обращения: 1 февраля 2019. 2 февраля 2019 года.
- (англ.) . docs.enlightenment.org. Дата обращения: 1 февраля 2019. 2 февраля 2019 года.
- ↑ . wiki.sei.cmu.edu. Дата обращения: 21 декабря 2018. 21 декабря 2018 года.
- ↑ (англ.) . wiki.sei.cmu.edu. Дата обращения: 5 января 2019. 5 января 2019 года.
- ↑ (англ.) . wiki.sei.cmu.edu. Дата обращения: 4 января 2019. 5 января 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 4 января 2019. 5 января 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 6 января 2019. 6 января 2019 года.
- (англ.) . gcc.gnu.org. Дата обращения: 23 февраля 2019. 17 июня 2012 года.
- (англ.) . clang.llvm.org. Дата обращения: 23 февраля 2019. 19 февраля 2019 года.
- . releases.llvm.org. Дата обращения: 23 февраля 2019. 23 февраля 2019 года.
- (англ.) . sourceware.org. Дата обращения: 2 февраля 2019. 2 февраля 2019 года.
- (англ.) . alpinelinux.org. Дата обращения: 2 февраля 2019. 3 февраля 2019 года.
- . docs.voidlinux.org . Дата обращения: 29 января 2022. 9 декабря 2021 года.
- . docs.microsoft.com. Дата обращения: 2 февраля 2019. 7 августа 2021 года.
- (англ.) . JetBrains. Дата обращения: 23 февраля 2019. 25 марта 2019 года.
- ↑ (англ.) . check.sourceforge.net. Дата обращения: 23 февраля 2019. 5 июня 2018 года.
- (англ.) . Valgrind Documentation . valgrind.org. Дата обращения: 21 мая 2019. 23 мая 2019 года.
- . kcachegrind.sourceforge.net. Дата обращения: 21 мая 2019. 6 апреля 2019 года.
- . Дата обращения: 25 сентября 2012. 17 декабря 2012 года.
- . Дата обращения: 25 января 2013. 25 мая 2013 года.
- на сайте SourceForge.net
- . Дата обращения: 7 марта 2009. 23 февраля 2009 года.
- (англ.) . clang.llvm.org. Дата обращения: 5 марта 2019. 6 марта 2019 года.
- (англ.) . linux.die.net. Дата обращения: 5 марта 2019. 13 мая 2019 года.
- Wolfram Research, Inc. (англ.) . Wolfram Mathematica® Tutorial Collection 36—37. library.wolfram.com (2008). Дата обращения: 29 мая 2019. 6 сентября 2015 года.
- Cleve Moler. . TheMathWorks News&Notes . www.mathworks.com (январь 2006). Дата обращения: 29 мая 2019. 4 марта 2016 года.
- (англ.) . pubs.opengroup.org. Дата обращения: 4 февраля 2019. 24 февраля 2019 года.
- (англ.) . pubs.opengroup.org. Дата обращения: 4 февраля 2019. 24 февраля 2019 года.
- (англ.) . pubs.opengroup.org. Дата обращения: 4 февраля 2019. 24 февраля 2019 года.
- М. Джонс. . www.ibm.com (30 октября 2008). Дата обращения: 4 февраля 2019. 7 февраля 2019 года.
- (англ.) . www.tiobe.com . Дата обращения: 2 февраля 2019. 25 февраля 2018 года.
- Stroustrup, Bjarne . Дата обращения: 9 июля 2018. 20 ноября 2007 года.
- . www.stroustrup.com. Дата обращения: 3 июня 2019. 6 февраля 2016 года.
- . Working Paper for Draft Proposed International Standard for Information Systems — Programming Language C++ (2 декабря 1996). — см. 1.2.1p3 (параграф 3 в разделе 1.2.1). Дата обращения: 6 июня 2009. 22 августа 2011 года.
- ↑ , 1. Предисловие, p. 79.
- . Издательство «Открытые системы». Дата обращения: 8 декабря 2018. 9 декабря 2018 года.
- Allen I. Holub. . — McGraw-Hill, 1995. — 214 с. — ISBN 9780070296893 . 9 декабря 2018 года. от 9 декабря 2018 на Wayback Machine
- . gcc.gnu.org. Дата обращения: 8 декабря 2018. 5 декабря 2018 года.
- . clang.llvm.org. Дата обращения: 8 декабря 2018. 9 декабря 2018 года.
- (англ.) . clang.llvm.org. Дата обращения: 8 декабря 2018. 1 декабря 2018 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 4 июня 2019. 4 июня 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 11 января 2019. 12 января 2019 года.
- . developer.gnome.org. Дата обращения: 9 декабря 2018. 7 сентября 2018 года.
- Например, от 14 августа 2018 на Wayback Machine
- . Дата обращения: 16 мая 2019. 27 марта 2019 года.
- ↑ . security.web.cern.ch. Дата обращения: 12 января 2019. 5 января 2019 года.
- (англ.) . cwe.mitre.org. Дата обращения: 12 января 2019. 13 января 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 12 января 2019. 13 января 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 25 мая 2019. 25 мая 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 8 декабря 2018. 9 декабря 2018 года.
- . wiki.sei.cmu.edu. Дата обращения: 9 декабря 2018. 8 декабря 2018 года.
- . wiki.sei.cmu.edu. Дата обращения: 24 мая 2019. 24 мая 2019 года.
- (англ.) . wiki.sei.cmu.edu. Дата обращения: 23 января 2019. 23 января 2019 года.
Литература
- ISO/IEC. . Programming languages — C . www.open-std.org (2017). Дата обращения: 3 декабря 2018. Архивировано из 24 октября 2018 года.
- Керниган Б. , Ритчи Д. Язык программирования Си = The C programming language. — 2-е изд. — М. : , 2007. — С. 304. — ISBN 0-13-110362-8 .
- Гукин Д. Язык программирования Си для «чайников» = C For Dummies. — М. : , 2006. — С. 352. — ISBN 0-7645-7068-4 .
- Подбельский В. В., Фомин С. С. . — М. : ДМК Пресс, 2012. — 318 с. — ISBN 978-5-94074-449-8 .
- Прата С. Язык программирования С: Лекции и упражнения = C Primer Plus. — М. : Вильямс, 2006. — С. 960. — ISBN 5-8459-0986-4 .
- Прата С. Язык программирования C (C11). Лекции и упражнения, 6-е издание = C Primer Plus, 6th Edition. — М. : Вильямс, 2015. — 928 с. — ISBN 978-5-8459-1950-2 .
- Столяров А. В. // Сборник статей молодых учёных факультета ВМК МГУ. — Издательский отдел факультета ВМК МГУ, 2010. — № 7 . — С. 78—90 .
- Шилдт Г. C: полное руководство, классическое издание = C: The Complete Reference, 4th Edition. — М. : , 2010. — С. 704. — ISBN 978-5-8459-1709-6 .
- Языки программирования Ада, Си, Паскаль = Comparing and Assessong Programming Languages Ada, C, and Pascal / А. Фьюэр, Н. Джехани. — М. : Радио и Саязь, 1989. — 368 с. — 50 000 экз. — ISBN 5-256-00309-7 .
- Papaspyrou N. S. : [ англ. ] : [ 22 января 2023] : doctoral dissertation. — National Technical University of Athens, 1998, February .
Ссылки
-
(англ.)
. — Официальная страница международной рабочей группы по стандартизации языка программирования Си. Дата обращения: 20 февраля 2009.
22 августа 2011 года.
- (англ.) . ISO/IEC 9899 — Programming languages — C — Approved standards . ISO/IEC JTC1/SC22/WG14 (6 мая 2005). — Стандарт ISO/IEC 9899:1999 (C99) + ISO/IEC 9899:1999 Cor. 1:2001(E) (TC1 — Technical Corrigendum 1 от 2001 года) + ISO/IEC 9899:1999 Cor. 2:2004(E) (TC2 — Technical Corrigendum 2 от 2004 года). Дата обращения: 20 февраля 2009. 22 августа 2011 года.
- (англ.) (апрель 2004). — Обоснование и пояснения для стандарта C99. Дата обращения: 20 февраля 2009. 22 августа 2011 года.
- — поддерживаемый энтузиастами вики -справочник с большой подборкой данных по языкам и , их стандартам, а также материалам, связанным с этими языками и их разработкой.
- (или ) — стандарт безопасного программирования на языке Си.
- Романов Е. . ermak.cs.nstu.ru. Дата обращения: 25 мая 2015.
|
|
|
|
|
|---|---|
| Компиляторы | |
| Библиотеки | |
| Особенности | |
| Некоторые потомки | |
| C и другие языки |
|
- 2020-12-08
- 1




























