Форум/Архив/Правила/2012/11
- 1 year ago
- 0
- 0

Частотный анализ , частотный криптоанализ — один из методов криптоанализа , основывающийся на предположении о существовании нетривиального статистического распределения отдельных символов и их последовательностей, как в открытом тексте, так и в шифротексте, которое, с точностью до замены символов, будет сохраняться в процессе шифрования и дешифрования.
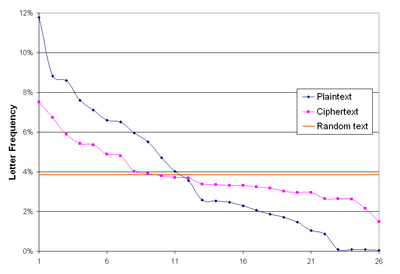
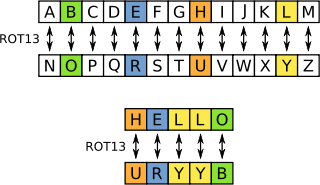
Упрощённо, частотный анализ предполагает, что частотность появления заданной буквы алфавита в достаточно длинных текстах одна и та же для разных текстов одного языка. При этом, в случае моноалфавитного шифрования , если в шифротексте будет символ с аналогичной вероятностью появления, то можно предположить, что он и является указанной зашифрованной буквой. Аналогичные рассуждения применяются к биграммам (двубуквенным последовательностям), триграммам и т. д. в случае полиалфавитных шифров .
Метод частотного криптоанализа известен с IX века (работы Ал-Кинди ), хотя наиболее известным случаем его применения в реальной жизни, возможно, является дешифровка египетских иероглифов Ж.-Ф. Шампольоном в 1822 году. В художественной литературе наиболее известными упоминаниями являются рассказы « Золотой жук » Эдгара По , « Пляшущие человечки » Конан Дойля , а также роман « Дети капитана Гранта » Жюль Верна .
Начиная с середины XX века большинство используемых алгоритмов шифрования разрабатываются устойчивыми к частотному криптоанализу, поэтому он применяется в основном в процессе обучения будущих криптографов.
Используется тот факт, что вероятность появления отдельных букв, а также их порядок в словах и фразах естественного языка подчиняются статистическим закономерностям: например, пара стоящих рядом букв «ся» в русском языке более вероятна, чем «цы», а « оь » в русском языке не встречается вовсе (зато часто встречается, например, в чеченском ). Анализируя достаточно длинный текст, зашифрованный методом замены, можно по частотностям появления символов произвести обратную замену и восстановить исходный текст.
Как упоминалось выше, важными характеристиками текста являются повторяемость букв (количество различных букв в каждом языке ограничено), пар букв, то есть m (m-грамм), сочетаемость букв друг с другом, чередование гласных и согласных и некоторые другие особенности. Примечательно, что эти характеристики являются достаточно устойчивыми.
Идея состоит в подсчёте чисел вхождений каждой n m возможных m-грамм в достаточно длинных открытых текстах T=t 1 t 2 …t l , составленных из букв алфавита {a 1 , a 2 , …, a n } . При этом просматриваются подряд идущие m-граммы текста:
t 1 t 2 …t m , t 2 t 3 … t m+1 , …, t i-m+1 t l-m+2 …t l .
Если L (a i1 a i2 … a im ) — число появлений m-граммы a i1 a i2 …a im в тексте T , а L — общее число подсчитанных m-грамм, то при достаточно больших L частотности L (a i1 a i2 … a im )/ L , для данной m-граммы мало отличаются друг от друга.
В силу этого, относительную частотность считают приближением вероятности P (a i1 a i2 …a im ) появления данной m-граммы в случайно выбранном месте текста (такой подход принят при статистическом определении вероятности).
В общем случае частотность букв в процентном выражении можно определить следующим образом: подсчитывается, сколько раз она встречается в шифротексте, затем полученное число делится на общее число символов шифротекста; для выражения в процентах, полученный результат умножается на 100.
Частотность существенно зависит, однако, не только от длины текста, но и от его характера. Например, в техническом тексте обычно редкая буква Ф может появляться гораздо чаще. Поэтому для надёжного определения средней частотности букв желательно иметь набор различных текстов.