Interested Article - NetBurst
- 2021-07-20
- 1
NetBurst (рабочее название — P68 ) — суперскалярная гиперконвейерная микроархитектура , разработанная компанией Intel и лежавшая в основе микропроцессоров Pentium 4 , Pentium D , Celeron и Xeon в 2000-2007 годах.
История
Архитектура NetBurst пришла на смену архитектуре P6 на рынке процессоров для настольных и серверных систем. Она не являлась развитием архитектуры P6, а представляла собой принципиально новую по сравнению со всеми предшественниками архитектуру.
Первые процессоры архитектуры NetBurst были анонсированы 20 ноября 2000 года . 8 августа 2007 года компания Intel объявила о начале действия программы по снятию с производства всех процессоров этой архитектуры . На смену процессорам архитектуры NetBurst в 2006 году пришли процессоры семейства Core 2 (Duo/Quad), архитектура которых представляет собой развитие более ранней архитектуры P6.
Особенности микроархитектуры
| Revision | Processor Brand(s) | Pipeline stages |
|---|---|---|
| Willamette (180 nm) | Celeron, Pentium 4 | 20 |
| Northwood (130 nm) | Celeron, Pentium 4, Pentium 4 HT | 20 |
| Gallatin (130 nm) | Pentium 4 HT Extreme Edition, Xeon | 20 |
| Prescott (90 nm) |
Celeron D, Pentium 4, Pentium 4 HT,
Pentium 4 Extreme Edition |
31 |
| Cedar Mill (65 nm) | Celeron D, Pentium 4 | 31 |
| Smithfield (90 nm) | Pentium D | 31 |
| Presler (65 nm) | Pentium D | 31 |
Архитектура NetBurst разрабатывалась, в первую очередь, с целью достижения высоких тактовых частот процессоров. Характерными особенностями архитектуры NetBurst являются гиперконвейеризация и применение кэша последовательностей микроопераций вместо традиционного кэша инструкций. АЛУ процессоров архитектуры NetBurst также имеет существенные отличия от АЛУ процессоров других архитектур. Также возможно применение технологии Hyper-threading .
Гиперконвейеризация
( англ. Hyper Pipelining )
Процессоры Pentium 4 на ядрах Willamette и Northwood имеют конвейер глубиной 20 стадий, а процессоры на ядрах Prescott и Cedar Mill — 31 стадию. При этом стадии декодирования инструкций не учитываются: в связи с применением кэша последовательностей микроопераций декодер ( англ. Instruction decoder ) вынесен за пределы конвейера. Это позволяет процессорам Pentium 4 достигать более высоких тактовых частот по сравнению с процессорами, имеющими более короткий конвейер при одинаковой технологии производства. Так, например, максимальная тактовая частота процессоров Pentium III на ядре Coppermine (180 нм . технология) составляет 1133 МГц , а процессоры Pentium 4 на ядре Willamette способны работать на частоте, превышающей 2000 МГц .
Для минимизации влияния неверно предсказанных переходов в процессорах архитектуры NetBurst используется увеличенный по сравнению с предшественниками буфер предсказания ветвлений (BTB, англ. branch target buffer ) и новый алгоритм предсказания ветвлений, что позволило достичь высокой точности предсказания (около 94 %) в процессорах на ядре Willamette. В последующих ядрах механизм предсказания ветвлений подвергался модернизациям, повышавшим точность предсказания .
Кэш последовательностей микроопераций
( англ. Execution Trace Cache )
Процессоры архитектуры NetBurst, как и большинство современных x86 -совместимых процессоров, являются CISC -процессорами с RISC -ядром: перед исполнением сложные инструкции x86 преобразуются в более простой набор внутренних инструкций (микроопераций), что позволяет повысить скорость обработки команд. Однако, вследствие того, что инструкции x86 имеют переменную длину и не имеют фиксированного формата, их декодирование связано с существенными временными затратами .
В связи с этим, при разработке архитектуры NetBurst было принято решение отказаться от традиционной кэш-памяти инструкций первого уровня, хранящей команды x86, в пользу кэша последовательностей микроопераций, хранящего последовательности микроопераций в соответствии с предполагаемым порядком их исполнения. Ёмкость trace cache составляла около 12 тыс. микроопераций. Такая организация кэш-памяти позволила также снизить временные затраты на выполнение условных переходов и на выборку инструкций.
АЛУ и механизм ускоренного исполнения целочисленных операций
( англ. Rapid Execution Engine )
Так как основной целью разработки архитектуры NetBurst было повышение производительности за счёт достижения высоких тактовых частот, возникла необходимость увеличения темпа выполнения основных целочисленных операций. Для достижения этой цели АЛУ процессоров архитектуры NetBurst разделено на несколько блоков: «медленное АЛУ» ( англ. slow ALU ), способное выполнять большое количество целочисленных операций, и два «быстрых АЛУ» ( англ. 2X ALU ), выполняющих только простейшие целочисленные операции (например, сложение). Выполнение операций на «быстрых АЛУ» происходит последовательно в три этапа: сначала вычисляются младшие разряды результата, затем старшие, после чего могут быть получены флаги.
«Быстрые АЛУ», обслуживающие их планировщики ( англ. Fast scheduler ), а также регистровый файл ( англ. Integer register file ) синхронизируются по половине такта процессора, таким образом, эффективная частота их работы вдвое превышает частоту ядра. Эти блоки образуют механизм ускоренного выполнения целочисленных операций.
В процессорах на ядрах Willamette и Norhtwood «быстрые АЛУ» способны выполнять лишь те операции, которые обрабатывают операнды в направлении от младших разрядов к старшим. При этом результат вычисления младших разрядов может быть получен через половину такта. Таким образом, эффективная задержка составляет половину такта. В процессорах на ядрах Willamette и Norhtwood отсутствуют блоки целочисленного умножения и сдвига, а данные операции выполняются другими блоками (в частности, блоком инструкций MMX ).
В процессорах на ядре Prescott (а также более новых ядрах) присутствует блок целочисленного умножения, а «быстрые АЛУ» способны выполнять операции сдвига. Эффективная задержка операций, исполняемых «быстрыми АЛУ», возросла по сравнению с процессорами на ядре Norhtwood и составляет один такт .
Система повторного исполнения микроопераций
( англ. Replay System )
Основной задачей планировщиков микроопераций является определение готовности микроопераций к исполнению и передача их на конвейер. Вследствие большого числа стадий конвейера планировщики вынуждены отправлять микрооперации на исполнительные блоки до того, как завершится выполнение предыдущих микроопераций. Это обеспечивает оптимальную загрузку исполнительных блоков процессора и позволяет избежать потери производительности в том случае, если данные, необходимые для выполнения микрооперации, находятся в кэш-памяти первого уровня, регистровом файле или могут быть переданы, минуя регистровый файл.
При определении готовности новых микроопераций к передаче на исполнительные блоки планировщику необходимо определить время выполнения тех предыдущих микроопераций, результатом которых являются данные, необходимые для выполнения новых микроопераций. В том случае, если время выполнения заранее не определено, планировщик для его определения использует наименьшее время её выполнения (так, например, если для выполнения некоторой микрооперации необходимо загрузить данные из памяти, планировщик при передаче этой микрооперации на конвейер будет исходить из предположения, что необходимые данные находятся в кэш-памяти данных первого уровня и будут получены через количество тактов, равное сумме латентности кэш-памяти первого уровня и количества тактов, которое займёт передача микрооперации от планировщика до исполнительного блока).
Если оценка времени, необходимого для получения данных, оказалась верной, микрооперация выполняется успешно. В том случае, если данные не были получены вовремя, проверка корректности результата заканчивается неудачей. При этом микрооперация, результат выполнения которой оказался некорректен, ставится в специальную очередь ( англ. replay queue ), а затем вновь направляется планировщиком на исполнение.
Существуют такие неблагоприятные ситуации, в которых повторное исполнение микроопераций может привести к взаимоблокировкам . Выход из таких ситуаций осуществляется прекращением передачи новых микроопераций на исполнительные блоки и направлением переисполняемых микроопераций в специальный буфер для того, чтобы они могли освободить конвейер.
Несмотря на то, что повторное исполнение микроопераций приводит к значительным потерям производительности, применение данного механизма позволяет в случае ошибочного исполнения микроопераций избежать останова и сброса конвейера, который приводил бы к более серьёзным потерям.
Достоинства
Основным достоинством процессоров архитектуры NetBurst является возможность работы на высоких тактовых частотах. Это позволяет достичь высокой производительности в оптимизированных задачах и компенсировать низкую удельную производительность. Кроме того, высокая тактовая частота даёт маркетинговые преимущества: потребители склонны выбирать процессоры с большей тактовой частотой (« покупают мегагерцы »). К достоинствам процессоров архитектуры NetBurst можно также отнести высокую пропускную способность памяти .
Поддержка технологии HyperThreading некоторыми процессорами архитектуры NetBurst позволяла поднять производительность в задачах, поддерживающих многопроцессорность , однако существуют некоторые задачи, при выполнении которых производительность может снижаться .
Благодаря удачной маркетинговой и рекламной политике компании Intel процессоры архитектуры NetBurst были популярны среди пользователей, что позволяло компании Intel удерживать значительную долю рынка микропроцессоров (больше 70 %) и получать прибыль, в отличие от основного конкурента — компании AMD .
Недостатки
Основными недостатками длинного конвейера являются уменьшение удельной производительности по сравнению с коротким конвейером (за один такт выполняется меньшее количество инструкций), а также серьёзные потери производительности при некорректном выполнении инструкций (например, при неверно предсказанном условном переходе или кэш-промахе) . Так, например, процессор Pentium 4 с частотой 1700 МГц в неоптимизированных под архитектуру NetBurst задачах уступал процессорам с частотой 1333 МГц .
Кроме того, работа процессоров на высоких частотах была связана с высоким тепловыделением . Несмотря на то, что процессоры на ядре Cedar Mill были способны работать на частотах, превышавших 7 ГГц , с использованием экстремального охлаждения (обычно использовался стакан с жидким азотом), максимальная тактовая частота серийных процессоров Pentium 4 составила 3800 МГц. При этом типичное тепловыделение превышало 100 Вт , а максимальное — 150 Вт .
Из-за невозможности дальнейшего наращивания тактовой частоты компания Intel была вынуждена предложить иной способ повышения производительности. Этим способом стал переход от одноядерных процессоров к многоядерным.
Двухъядерные процессоры архитектуры NetBurst для настольных компьютеров ( Pentium D ) представляли собой два ядра Prescott (процессоры на ядре Smithfield), находящиеся на одном кристалле, или Cedar Mill (Presler), находящиеся в одном корпусе (по сути, два отдельных процессора в одном корпусе). Так как процессоры архитектуры NetBurst изначально разрабатывались как одноядерные, обмен данными между ядрами осуществлялся через оперативную память , что приводило к потерям производительности (для сравнения, конкурирующие процессоры Athlon 64 X2 разрабатывались с расчётом на многоядерность, поэтому имеют специальный блок, позволяющий осуществлять обмен данными, минуя оперативную память ) .
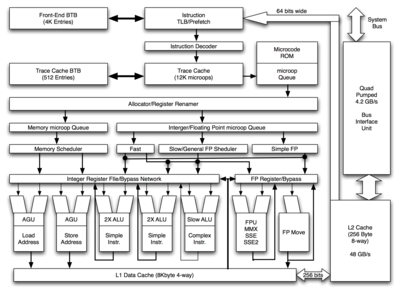
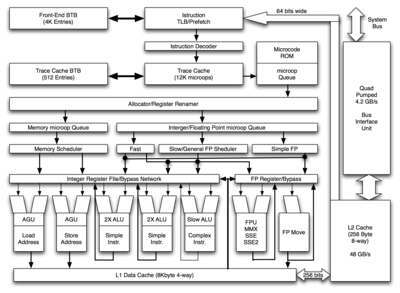
Описание функциональных блоков

Процессоры архитектуры NetBurst состоят из четырёх основных структурных блоков:
- Исполнительные устройства ( англ. execution unit ), осуществляющие выполнение инструкций, а также устройства, обеспечивающие взаимодействие исполнительных устройств.
- Входной блок ( англ. front end ), отвечающий за предвыборку данных, предсказание ветвлений и декодирование инструкций (преобразование сложных инструкций x86 в простые внутренние инструкции — микрооперации).
- Устройства организации внеочередного исполнения ( англ. out-of-order buffering logic ), обеспечивающие оптимальный порядок исполнения микроопераций.
- Интерфейс памяти ( англ. memory subsystem ), представляющий собой группу устройств, обеспечивающих взаимодействие процессора с подсистемой памяти.
Исполнительные устройства
К исполнительным устройствам относятся:
- Целочисленный регистровый файл и логика, обеспечивающая непосредственную передачу данных между блоками АЛУ (Integer Register File / Bypass Network). Регистровый файл обеспечивает хранение результатов операций, однако при этом данные могут передаваться между исполнительными блоками, минуя регистровый файл.
- Блоки генерации адреса чтения и записи (AGU). Предназначены для взаимодействия с кэшем данных. Формируют адреса, по которым производятся операции чтения и записи.
- АЛУ (ALU). Осуществляют выполнение целочисленных операций.
- Целочисленный регистровый файл и логика, обеспечивающая непосредственную передачу данных между блоком обработки чисел с плавающей запятой, обеспечивающим выполнение инструкций x87 , MMX , SSE и SSE2 (FP Register / Bypass).
- Блоки обработки чисел с плавающей запятой (FP / MMX / SSE / SSE2, FP Move). Осуществляют выполнение операций над вещественными числами, в том числе операции чтения и записи (блок FP Move).
В процессорах на ядре Prescott и более новых блок обработки чисел с плавающей запятой получил поддержку инструкций SSE3 .
Устройства организации внеочередного исполнения
Внеочередное исполнение позволяет ускорить работу за счёт изменения порядка выполнения микроопераций в тех случаях, когда это изменение не приведёт к изменению результата. К устройствам организации внеочередного исполнения относятся:
- Диспетчер ресурсов (Allocator / Register Renamer). Осуществляет распределение вычислительных ресурсов, переименование регистров (установление соответствия между логическими регистрами x86 и некоторыми физическими регистрами, выделенными специально для выполняемой инструкции), а также отслеживает состояние всех микроопераций, находящихся в обработке.
- Очереди микроопераций (Memory uop Queue и Integer/Floating Point uop Queue). Содержат микрооперации, которые необходимо выполнить. При этом микрооперации, осуществляющие взаимодействие с памятью (чтение и запись), отделены от всех остальных и размещаются в специальной очереди (Memory uop Queue).
- Планировщики микроопераций (Memory Scheduler, Fast, Slow/General FP Scheduler, Simple FP). Определяют готовность микроопераций, находящихся в очередях, к исполнению и направляют их на выполнение в соответствующие исполнительные блоки.
Устройства входного блока
К устройствам входного блока относятся:
- Модуль и буфера предсказания ветвлений (Front end BTB и Trace cache BTB). Осуществляют предсказание ветвлений и хранят таблицу истории переходов. Для предсказания ветвлений используется как динамический, так и статический методы. Последний используется в том случае, если динамическое предсказание невозможно (в буфере переходов отсутствует необходимая информация).
- Кэш последовательностей микроопераций (Trace cache). Хранит последовательности микроопераций в соответствии с предполагаемым порядком их исполнения.
- Декодер инструкций (Instruction decoder). Осуществляет преобразование CISC -инструкций x86 в последовательность RISC -микроопераций, исполняемых процессором.
- Блок предвыборки инструкций (Prefetcher). Осуществляет предварительную выборку инструкций на основании таблиц предсказания ветвлений и преобразование программного адреса инструкции в физический с помощью таблицы трансляции адресов (I-TLB).
- ПЗУ микрокода (Microcode ROM). Используется кэшем последовательностей микроопераций при преобразовании сложных инструкций x86 в последовательность микроопераций.
- Очередь микроопераций (uop Queue). Содержит микрооперации, поступающие на конвейер процессора.
Интерфейс памяти
Интерфейс памяти осуществляет взаимодействие с оперативной памятью. К этому блоку относятся:
- Кэш-память данных первого уровня (L1 Data Cache). Память объёмом 8 (Willamette и Northwood) или 16 КБ с малым временем доступа (латентность составляет 2 такта для Northwood и 5 тактов для Prescott).
- Кэш-память второго уровня (L2 Cache). Память объёмом 128 (Willamette-128, Northwood-128), 256 (Willamette, Prescott-256), 512 (Northwood), 1024 (Prescott) или 2048 КБ с малым временем доступа (латентность составляет 7 тактов для Northwood и 18 тактов для Prescott). Соединяется с кэшем первого уровня шиной шириной 256 бит .
- Блок шинного интерфейса (Bus Interface Unit). Осуществляет управление системной шиной.
Некоторые процессоры содержали также кэш-память третьего уровня объёмом 2, 4 или 8 МБ .
Описание работы
Конвейер состоит из 20 стадий:
- TC, NI (1, 2) — поиск микроопераций, на которые указывает последняя выполненная инструкция.
- TR, F (3, 4) — выборка микроопераций.
- D (5) — перемещение микроопераций.
- AR (6 — 8) — резервирование ресурсов процессора, переименование регистров.
- Q (9) — постановка микроопераций в очереди.
- S (10 — 12) — изменение порядка исполнения.
- D (13 — 14) — подготовка к исполнению, выборка операндов.
- R (15 — 16) — чтение операндов из регистрового файла.
- E (17) — исполнение.
- F (18) — вычисление флагов.
- BC, D (19, 20) — проверка корректности результата.
Выполнение инструкции начинается с её выборки и декодирования. В том случае, если соответствующая ей последовательность микроопераций отсутствует в кэше последовательностей микроопераций, инструкция считывается из кэш-памяти второго уровня и декодируется. Так как инструкции, хранящиеся в кэш-памяти, имеют физические адреса, для осуществления выборки блоком трансляции адресов производится преобразование виртуального адреса в физический.
Микрооперации, полученные в результате декодирования, помещаются в кэш последовательностей микроопераций. В том случае, если встречается инструкция условного перехода, последовательность микроопераций формируется на основании предсказания перехода, осуществляемого соответствующим блоком . Если инструкция не может быть преобразована в последовательность длиной до четырёх микроопераций, она заменяется на подпрограмму, хранящуюся в ПЗУ микрокода и формирующую такие последовательности. При этом в кэше последовательностей хранятся не сами микрооперации, а адрес этой подпрограммы. Микрооперации, хранящиеся в кэше последовательностей, помещаются в очередь микроопераций.
После подготовки процессора к выполнению микроопераций (резервирование ресурсов, переименование регистров) они помещаются в соответствующие их типам очереди: микрооперации, осуществляющие взаимодействие с памятью, помещаются в отдельную очередь длиной 16 микроопераций, а все остальные — в общую очередь (32 микрооперации). После определения порядка выполнения микроопераций (порядок может быть изменён в зависимости от готовности данных для выполнения микроопераций, от наличия переисполняемых инструкций, наличия свободных вычислительных ресурсов и т. п.), планировщики отправляют микрооперации на выполнение в соответствующие исполнительные блоки: микрооперации, взаимодействующие с памятью, отправляются в блоки генерации адреса, целочисленные операции — в блоки АЛУ, а вещественночисленные — в блоки обработки чисел с плавающей запятой. При этом операнды, необходимые для выполнения микроопераций, либо считываются из регистрового файла, либо передаются как результат выполнения предыдущей микрооперации. После выполнения микроопераций происходит формирование флагов и проверка корректности результатов. В том случае, если результаты корректны, происходит отставка ( англ. retirement ) микроопераций, а результаты помещаются в регистровый файл. Если же результаты выполнения микрооперации некорректны (например, был неверно предсказан переход или необходимые данные не были вовремя получены), эта микрооперация отправляется на повторное исполнение .
Процессоры архитектуры NetBurst
| Процессор | Ядро | Технология производства | Годы выпуска |
|---|---|---|---|
| Pentium 4 | Willamette, Northwood, Gallatin, Prescott, Cedar Mill | КМОП , 180—65 нм | 2000 — 2007 |
| Pentium D | Smithfield, Presler | КМОП, 90—65 нм | 2005 —2007 |
| Celeron | Willamette-128, Northwood-128 | КМОП, 180—130 нм | 2001 —2005 |
| Celeron D | Prescott-256, Cedar Mill-512 | КМОП, 90—65 нм | 2004 —2007 |
| Xeon | Foster, Prestonia, Gallatin, Potomac, Cranford, Irwindale, Nocona, Paxville, Dempsey, Tulsa | КМОП, 180—65 нм | 2001—2007 |

|

|

|

|

|
|---|---|---|---|---|
| Pentium 4 (Northwood) | Pentium D (Smithfield) | Celeron (Northwood-128) | Celeron D (Prescott-256) | Xeon DP (Foster) |
Примечания
- ↑ Дата обращения: 19 марта 2008. 24 августа 2011 года.
- . Дата обращения: 19 марта 2008. 7 ноября 2012 года.
- . Дата обращения: 19 марта 2008. 24 августа 2011 года.
- ↑ . Дата обращения: 23 января 2022. Архивировано из 24 августа 2011 года.
- . Дата обращения: 15 мая 2022. 9 октября 2006 года.
- ↑ . Дата обращения: 23 января 2022. Архивировано из 24 августа 2011 года.
- . Дата обращения: 21 марта 2008. 4 марта 2008 года.
- . Дата обращения: 21 марта 2008. 24 августа 2011 года.
- . Дата обращения: 23 марта 2008. Архивировано из 13 октября 2012 года.
- . Дата обращения: 23 марта 2008. 30 декабря 2021 года.
- . Дата обращения: 19 марта 2008. 27 января 2012 года.
- . Дата обращения: 19 марта 2008. 28 мая 2008 года.
- от 11 апреля 2008 на Wayback Machine (англ.)
- от 5 апреля 2008 на Wayback Machine (англ.)
- . Дата обращения: 2 апреля 2008. 4 апреля 2008 года.
- . Дата обращения: 21 марта 2008. 23 июня 2008 года.
- . Дата обращения: 25 августа 2016. 28 декабря 2016 года.
Ссылки
Официальная информация
- (англ.)
- (англ.)
- (англ.)
- (англ.)
- (англ.)
- (англ.)
Характеристики процессоров архитектуры NetBurst
- (англ.)
- (англ.)
- (англ.)
- (англ.)
- (англ.)
- (англ.)
Обзоры процессоров и описания архитектуры
- 24 августа 2011 года.
- 24 августа 2011 года.
- 24 августа 2011 года.
|
|||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||
- 2021-07-20
- 1