![[N/2]](/images/005/281/5281787/13.jpg?rand=644490)







Куча (память)
- 1 year ago
- 0
- 0


Двои́чная ку́ча , пирами́да , или сортиру́ющее де́рево — такое двоичное дерево , для которого выполнены три условия:
Существуют также кучи, где значение в любой вершине, наоборот, не больше, чем значения её потомков. Такие кучи называются min-heap, а кучи, описанные выше — max-heap. В дальнейшем рассматриваются только max-heap. Все действия с min-heap осуществляются аналогично.

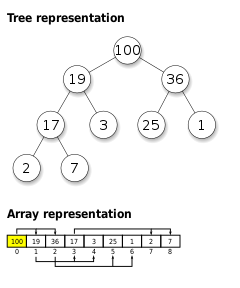
Удобная структура данных для сортирующего дерева — массив A , у которого первый элемент, A [1] — элемент в корне, а потомками элемента A [ i ] являются A [2 i ] и A [2 i +1] (при нумерации элементов с первого). При нумерации элементов с нулевого, корневой элемент — A [0], а потомки элемента A [ i ] — A [2 i +1] и A [2 i +2]. При таком способе хранения условия 2 и 3 выполнены автоматически.
Высота кучи определяется как высота двоичного дерева. То есть она равна количеству рёбер в самом длинном простом пути, соединяющем корень кучи с одним из её листьев. Высота кучи есть , где N — количество узлов дерева.
Над кучей можно выполнять следующие операции:
На основе этих операций можно выполнять следующие действия:
Здесь — количество элементов кучи. Пространственная сложность — для всех вышеперечисленных операций и действий.
Подробное описание и алгоритмы этих действий и процедуры Heapify, необходимой для их выполнения, приведены в следующем разделе.
В этом разделе представлены основные процедуры для работы с кучей.
Если в куче изменяется один из элементов, то она может перестать удовлетворять свойству упорядоченности. Для восстановления этого свойства служит процедура Heapify. Она восстанавливает свойство кучи в дереве, у которого левое и правое поддеревья удовлетворяют ему. Эта процедура принимает на вход массив элементов A и индекс i . Она восстанавливает свойство упорядоченности во всём поддереве, корнем которого является элемент A [ i ].
Если i -й элемент больше, чем его сыновья, всё поддерево уже является кучей, и делать ничего не надо. В противном случае меняем местами i -й элемент с наибольшим из его сыновей, после чего выполняем Heapify для этого сына.
Процедура выполняется за время .
Heapify(A, i)
left ← 2i
right ← 2i+1
heap_size - количество элементов в куче
largest ← i
if left ≤ A.heap_size и A[left] > A[largest]
then largest ← left
if right ≤ A.heap_size и A[right] > A[largest]
then largest ← right
if largest ≠ i
then Обменять A[i] ↔ A[largest]
Heapify(A, largest)
Для языков, не поддерживающих автоматическую оптимизацию хвостовой рекурсии , можно повысить эффективность реализации, если избавиться от рекурсии.
Эта процедура предназначена для создания кучи из неупорядоченного массива входных данных.
Заметим, что если выполнить Heapify для всех элементов массива A, начиная с последнего и кончая первым, он станет кучей. В самом деле, легко доказать по индукции, что к моменту выполнения Heapify(A, i) все поддеревья, чьи корни имеют индекс больше i, - кучи, и, следовательно, после выполнения Heapify(A, i) кучей будут все поддеревья, чьи корни имеют индекс, не меньший i.
Кроме того, Heapify(A,i) не делает ничего, если i>N/2 (при нумерации с первого элемента), где N — количество элементов массива. В самом деле, у таких элементов нет потомков, следовательно, соответствующие поддеревья уже являются кучами, так как содержат всего один элемент.
Таким образом, достаточно вызвать Heapify для всех элементов массива A, начиная (при нумерации с первого элемента) с -го и кончая первым.
Build_Heap(A)
A.heap_size ← A.length
for i ← ⌊A.length/2⌋ downto 1
do Heapify(A, i)
И хотя здесь происходит n/2 вызовов функции Heapify со сложностью , можно показать, что время работы равно .
Процедура Heapsort сортирует массив без привлечения дополнительной памяти за время .
Для понимания её работы можно представить, что мы обменяли первый элемент (то есть корень) с последним. Тогда последний элемент станет самым большим. Если после этого исключить последний элемент из кучи (то есть формально уменьшить её длину на 1), первые N-1 элементов будут удовлетворять условиям кучи все, за исключением, может быть, корня. Если вызвать Heapify, первые N-1 элементов станут кучей, а последний будет больше их всех. Повторяя эти действия N-1 раз, мы отсортируем массив.
Heapsort(A)
Build_Heap(A)
for i ← A.length downto 1
do Обменять A[1] ↔ A[i]
A.heap_size ← A.heap_size-1
Heapify(A,1)
Процедура Heap_Increase_Key заменяет элемент кучи на новый ключ со значением, не меньшим значения исходного элемента . Обычно эта процедура используется для добавления произвольного элемента в кучу. Временная сложность .
Если элемент меньше своего отца, условие 1 соблюдено для всего дерева, и больше ничего делать не нужно. Если он больше, мы меняем местами его с отцом. Если после этого отец больше деда, мы меняем местами отца с дедом и так далее. Иными словами, слишком большой элемент всплывает наверх.
Heap_Increase_Key(A, i, key)
if key < A[i]
then error "Новый ключ меньше предыдущего"
A[i] ← key
while i > 1 и A[⌊i/2⌋] < A[i]
do Обменять A[i] ↔ A[⌊i/2⌋]
i ← ⌊i/2⌋
В случае, когда необходимо уменьшить значение элемента, можно вызвать Heapify.
Выполняет добавление элемента в кучу за время .
Добавление произвольного элемента в конец кучи, и восстановление свойства упорядоченности с помощью Heap_Increase_Key.
Heap_Insert(A, key) A.heap_size ← A.heap_size+1 A[A.heap_size] ← -∞ Heap_Increase_Key(A, A.heap_size, key)
Выполняет извлечение максимального элемента из кучи за время .
Извлечение выполняется в четыре этапа:
Heap_Extract_Max(A)
if A.heap_size[A] < 1
then error "Куча пуста"
max ← A[1]
A[1] ← A[A.heap_size]
A.heap_size ← A.heap_size-1
Heapify(A, 1)
return max
|
|
В статье
не хватает
ссылок на источники
(см.
рекомендации по поиску
).
|
| Типы | |
|---|---|
| Абстрактные | |
| Массив | |
| Деревья | |
| Графы | |
| Двоичные деревья | |
|---|---|
| B-деревья | |
| Префиксные деревья | |
|
Двоичное разбиение
пространства |
|
| Недвоичные деревья | |
| Разбиение пространства | |
| Другие деревья | |
| Алгоритмы | |