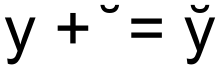Interested Article - Расширенные комбинируемые диакритические знаки

- 2021-05-05
- 1
Расширенные комбинируемые диакритические знаки ( англ. Combining Diacritical Marks Extended ) — блок стандарта Юникод, содержащий диакритические знаки для транскрипции Teuthonista .
Список символов
| Код | Символ | Название | Характеристики в Юникоде |
Версия,
в которой был добавлен символ |
HTML | ||||
|---|---|---|---|---|---|---|---|---|---|
|
Категория
символа |
Класс комбини-
руемости |
Класс
направ- ления |
Тип
разрыва строки |
16-чный | 10-чный | ||||
| U+ 1AB0 | combining doubled circumflex accent | Mn | 230 | NSM | CM | 7.0 | ᪰ | ᪰ | |
| U+ 1AB1 | combining diaeresis-ring | Mn | 230 | NSM | CM | 7.0 | ᪱ | ᪱ | |
| U+ 1AB2 | combining infinity | Mn | 230 | NSM | CM | 7.0 | ᪲ | ᪲ | |
| U+ 1AB3 | combining downwards arrow | Mn | 230 | NSM | CM | 7.0 | ᪳ | ᪳ | |
| U+ 1AB4 | ◌᪴ | combining triple dot | Mn | 230 | NSM | CM | 7.0 | ᪴ | ᪴ |
| U+ 1AB5 | combining x-x below | Mn | 220 | NSM | CM | 7.0 | ᪵ | ᪵ | |
| U+ 1AB6 | combining wiggly line below | Mn | 220 | NSM | CM | 7.0 | ᪶ | ᪶ | |
| U+ 1AB7 | ◌᪷ | combining open mark below | Mn | 220 | NSM | CM | 7.0 | ᪷ | ᪷ |
| U+ 1AB8 | ◌᪸ | combining double open mark below | Mn | 220 | NSM | CM | 7.0 | ᪸ | ᪸ |
| U+ 1AB9 | combining light centralization stroke below | Mn | 220 | NSM | CM | 7.0 | ᪹ | ᪹ | |
| U+ 1ABA | combining strong centralization stroke below | Mn | 220 | NSM | CM | 7.0 | ᪺ | ᪺ | |
| U+ 1ABB | ◌᪻ | combining parentheses above | Mn | 230 | NSM | CM | 7.0 | ᪻ | ᪻ |
| U+ 1ABC | ◌᪼ | combining double parentheses above | Mn | 230 | NSM | CM | 7.0 | ᪼ | ᪼ |
| U+ 1ABD | ◌᪽ | combining parentheses below | Mn | 220 | NSM | CM | 7.0 | ᪽ | ᪽ |
| U+ 1ABE | ◌᪾ | combining parentheses overlay | Me | 0 | NSM | CM | 7.0 | ᪾ | ᪾ |
| U+ 1ABF | ◌ᪿ | combining latin small letter w below | Mn | 220 | NSM | CM | 13.0 | ᪿ | ᪿ |
| U+ 1AC0 | combining latin small letter turned w below | Mn | 220 | NSM | CM | 13.0 | ᫀ | ᫀ | |
| U+ 1AC1 | ◌᫁ | combining left parenthesis above left | Mn | 230 | NSM | CM | 14.0 | ᫁ | ᫁ |
| U+ 1AC2 | ◌᫂ | combining right parenthesis above right | Mn | 230 | NSM | CM | 14.0 | ᫂ | ᫂ |
| U+ 1AC3 | ◌᫃ | combining left parenthesis below left | Mn | 220 | NSM | CM | 14.0 | ᫃ | ᫃ |
| U+ 1AC4 | ◌᫄ | combining right parenthesis below right | Mn | 220 | NSM | CM | 14.0 | ᫄ | ᫄ |
| U+ 1AC5 | ◌᫅ | combining square brackets above | Mn | 230 | NSM | CM | 14.0 | ᫅ | ᫅ |
| U+ 1AC6 | ◌᫆ | combining number sign above | Mn | 230 | NSM | CM | 14.0 | ᫆ | ᫆ |
| U+ 1AC7 | combining inverted double arch above | Mn | 230 | NSM | CM | 14.0 | ᫇ | ᫇ | |
| U+ 1AC8 | combining plus sign above | Mn | 230 | NSM | CM | 14.0 | ᫈ | ᫈ | |
| U+ 1AC9 | combining double plus sign above | Mn | 230 | NSM | CM | 14.0 | ᫉ | ᫉ | |
| U+ 1ACA | combining double plus sign below | Mn | 220 | NSM | CM | 14.0 | ᫊ | ᫊ | |
| U+ 1ACB | combining triple acute accent | Mn | 230 | NSM | CM | 14.0 | ᫋ | ᫋ | |
| U+ 1ACC | ◌ᫌ | combining latin small letter insular g | Mn | 230 | NSM | CM | 14.0 | ᫌ | ᫌ |
| U+ 1ACD | combining latin small letter insular r | Mn | 230 | NSM | CM | 14.0 | ᫍ | ᫍ | |
| U+ 1ACE | ◌ᫎ | combining latin small letter insular t | Mn | 230 | NSM | CM | 14.0 | ᫎ | ᫎ |
| U+ 1ACF | <reserved-1ACF> | Cn | 0 | L | XX | — | ᫏ | ᫏ | |
| U+ 1AD0 | <reserved-1AD0> | Cn | 0 | L | XX | — | ᫐ | ᫐ | |
| U+ 1AD1 | <reserved-1AD1> | Cn | 0 | L | XX | — | ᫑ | ᫑ | |
| U+ 1AD2 | <reserved-1AD2> | Cn | 0 | L | XX | — | ᫒ | ᫒ | |
| U+ 1AD3 | <reserved-1AD3> | Cn | 0 | L | XX | — | ᫓ | ᫓ | |
| U+ 1AD4 | <reserved-1AD4> | Cn | 0 | L | XX | — | ᫔ | ᫔ | |
| U+ 1AD5 | <reserved-1AD5> | Cn | 0 | L | XX | — | ᫕ | ᫕ | |
| U+ 1AD6 | <reserved-1AD6> | Cn | 0 | L | XX | — | ᫖ | ᫖ | |
| U+ 1AD7 | <reserved-1AD7> | Cn | 0 | L | XX | — | ᫗ | ᫗ | |
| U+ 1AD8 | <reserved-1AD8> | Cn | 0 | L | XX | — | ᫘ | ᫘ | |
| U+ 1AD9 | <reserved-1AD9> | Cn | 0 | L | XX | — | ᫙ | ᫙ | |
| U+ 1ADA | <reserved-1ADA> | Cn | 0 | L | XX | — | ᫚ | ᫚ | |
| U+ 1ADB | <reserved-1ADB> | Cn | 0 | L | XX | — | ᫛ | ᫛ | |
| U+ 1ADC | <reserved-1ADC> | Cn | 0 | L | XX | — | ᫜ | ᫜ | |
| U+ 1ADD | <reserved-1ADD> | Cn | 0 | L | XX | — | ᫝ | ᫝ | |
| U+ 1ADE | <reserved-1ADE> | Cn | 0 | L | XX | — | ᫞ | ᫞ | |
| U+ 1ADF | <reserved-1ADF> | Cn | 0 | L | XX | — | ᫟ | ᫟ | |
| U+ 1AE0 | <reserved-1AE0> | Cn | 0 | L | XX | — | ᫠ | ᫠ | |
| U+ 1AE1 | <reserved-1AE1> | Cn | 0 | L | XX | — | ᫡ | ᫡ | |
| U+ 1AE2 | <reserved-1AE2> | Cn | 0 | L | XX | — | ᫢ | ᫢ | |
| U+ 1AE3 | <reserved-1AE3> | Cn | 0 | L | XX | — | ᫣ | ᫣ | |
| U+ 1AE4 | <reserved-1AE4> | Cn | 0 | L | XX | — | ᫤ | ᫤ | |
| U+ 1AE5 | <reserved-1AE5> | Cn | 0 | L | XX | — | ᫥ | ᫥ | |
| U+ 1AE6 | <reserved-1AE6> | Cn | 0 | L | XX | — | ᫦ | ᫦ | |
| U+ 1AE7 | <reserved-1AE7> | Cn | 0 | L | XX | — | ᫧ | ᫧ | |
| U+ 1AE8 | <reserved-1AE8> | Cn | 0 | L | XX | — | ᫨ | ᫨ | |
| U+ 1AE9 | <reserved-1AE9> | Cn | 0 | L | XX | — | ᫩ | ᫩ | |
| U+ 1AEA | <reserved-1AEA> | Cn | 0 | L | XX | — | ᫪ | ᫪ | |
| U+ 1AEB | <reserved-1AEB> | Cn | 0 | L | XX | — | ᫫ | ᫫ | |
| U+ 1AEC | <reserved-1AEC> | Cn | 0 | L | XX | — | ᫬ | ᫬ | |
| U+ 1AED | <reserved-1AED> | Cn | 0 | L | XX | — | ᫭ | ᫭ | |
| U+ 1AEE | <reserved-1AEE> | Cn | 0 | L | XX | — | ᫮ | ᫮ | |
| U+ 1AEF | <reserved-1AEF> | Cn | 0 | L | XX | — | ᫯ | ᫯ | |
| U+ 1AF0 | <reserved-1AF0> | Cn | 0 | L | XX | — | ᫰ | ᫰ | |
| U+ 1AF1 | <reserved-1AF1> | Cn | 0 | L | XX | — | ᫱ | ᫱ | |
| U+ 1AF2 | <reserved-1AF2> | Cn | 0 | L | XX | — | ᫲ | ᫲ | |
| U+ 1AF3 | <reserved-1AF3> | Cn | 0 | L | XX | — | ᫳ | ᫳ | |
| U+ 1AF4 | <reserved-1AF4> | Cn | 0 | L | XX | — | ᫴ | ᫴ | |
| U+ 1AF5 | <reserved-1AF5> | Cn | 0 | L | XX | — | ᫵ | ᫵ | |
| U+ 1AF6 | <reserved-1AF6> | Cn | 0 | L | XX | — | ᫶ | ᫶ | |
| U+ 1AF7 | <reserved-1AF7> | Cn | 0 | L | XX | — | ᫷ | ᫷ | |
| U+ 1AF8 | <reserved-1AF8> | Cn | 0 | L | XX | — | ᫸ | ᫸ | |
| U+ 1AF9 | <reserved-1AF9> | Cn | 0 | L | XX | — | ᫹ | ᫹ | |
| U+ 1AFA | <reserved-1AFA> | Cn | 0 | L | XX | — | ᫺ | ᫺ | |
| U+ 1AFB | <reserved-1AFB> | Cn | 0 | L | XX | — | ᫻ | ᫻ | |
| U+ 1AFC | <reserved-1AFC> | Cn | 0 | L | XX | — | ᫼ | ᫼ | |
| U+ 1AFD | <reserved-1AFD> | Cn | 0 | L | XX | — | ᫽ | ᫽ | |
| U+ 1AFE | <reserved-1AFE> | Cn | 0 | L | XX | — | ᫾ | ᫾ | |
| U+ 1AFF | <reserved-1AFF> | Cn | 0 | L | XX | — | ᫿ | ᫿ | |
Компактная таблица
|
Расширенные комбинируемые диакритические знаки
( PDF ) |
||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+1ABx | ◌᪰ | ◌᪱ | ◌᪲ | ◌᪳ | ◌᪴ | ◌᪵ | ◌᪶ | ◌᪷ | ◌᪸ | ◌᪹ | ◌᪺ | ◌᪻ | ◌᪼ | ◌᪽ | ◌᪾ | ◌ᪿ |
| U+1ACx | ◌ᫀ | ◌᫁ | ◌᫂ | ◌᫃ | ◌᫄ | ◌᫅ | ◌᫆ | ◌᫇ | ◌᫈ | ◌᫉ | ◌᫊ | ◌᫋ | ◌ᫌ | ◌ᫍ | ◌ᫎ | |
| U+1ADx | ||||||||||||||||
| U+1AEx | ||||||||||||||||
| U+1AFx | ||||||||||||||||
Примечания
|
||||||||||||||||
История
В таблице указаны документы, отражающие процесс формирования блока.
| Версия | Итоговые кодовые позиции | Количество | ID | ID | Документ |
|---|---|---|---|---|---|
| 7.0 | U+1AB0..1ABE | 15 | Everson, Michael (2008-11-27), Exploratory proposal to encode Germanicist, Nordicist, and other phonetic characters in the UCS | ||
| Everson, Michael; Wandl-Vogt, Eveline; Dicklberger, Alois (2010-09-23), Preliminary proposal to encode “Teuthonista” phonetic characters in the UCS | |||||
| Everson, Michael; Wandl-Vogt, Eveline; Dicklberger, Alois (2011-05-09), Proposal to encode “Teuthonista” phonetic characters in the UCS | |||||
| Everson, Michael; et al. (2011-05-27), Support for “Teuthonista” encoding proposal | |||||
| Everson, Michael; Dicklberger, Alois; Pentzlin, Karl; Wandl-Vogt, Eveline (2011-06-02), Revised proposal to encode “Teuthonista” phonetic characters in the UCS | |||||
| Everson, Michael; Pentzlin, Karl (2011-06-09), Report on the ad hoc re “Teuthonista” (SC2/WG2 N4081) held during the SC2/WG2 meeting at Helsinki | |||||
Moore, Lisa (2011-08-16), "Consensus 128-C38",
UTC #128 / L2 #225 Minutes
,
Approve 85 characters for German dialectology... |
|||||
| "11.16 Teuthonista phonetic characters", Unconfirmed minutes of WG 2 meeting 58 , 2012-01-03 | |||||
| Request to change the names of three Teuthonista characters under ballot , 2012-07-26 | |||||
| 13.0 | U+1ABF..1AC0 | 2 | Everson, Michael (2019-05-05), Proposal to add six phonetic characters for Scots to the UCS | ||
| Anderson, Deborah; et al. (2019-04-29), "Phonetic characters for Scots", Recommendations to UTC #159 April-May 2019 on Script Proposals | |||||
| Moore, Lisa (2019-05-08), "C.6", UTC #159 Minutes | |||||
| "M68.05", Unconfirmed minutes of WG 2 meeting 68 , 2019-12-31 | |||||
| Pournader, Roozbeh (2020-01-15), Changes to Identifier_Type of some Unicode 13.0 characters | |||||
| Moore, Lisa (2020-01-23), "B.13.4 Changes to Identifier_Type of some Unicode 13.0 characters", Draft Minutes of UTC Meeting 162 | |||||
| 14.0 | U+1AC1..1AC4 | 4 | Miller, Kirk; Ball, Martin (2020-01-08), Unicode request for extIPA support | ||
| Anderson, Deborah; Whistler, Ken; Pournader, Roozbeh; Moore, Lisa; Liang, Hai (2020-01-10), "1a. Extended IPA", Recommendations to UTC #162 January 2020 on Script Proposals | |||||
| Miller, Kirk; Ball, Martin (2020-04-14), Expansion of the extIPA and VoQS | |||||
| Anderson, Deborah; Whistler, Ken; Pournader, Roozbeh; Moore, Lisa; Constable, Peter; Liang, Hai (2020-04-20), "1a. Extended IPA and VoQS", Recommendations to UTC #163 April 2020 on Script Proposals | |||||
| Miller, Kirk; Ball, Martin (2020-07-11), Expansion of the extIPA and VoQS | |||||
| Anderson, Deborah; Whistler, Ken; Pournader, Roozbeh; Moore, Lisa; Constable, Peter; Liang, Hai (2020-07-21), "3b. Expansion of the extIPA and VoQS", Recommendations to UTC #164 July 2020 on Script Proposals | |||||
| Moore, Lisa (2020-08-03), "Consensus 164-C9", UTC #164 Minutes | |||||
| Anderson, Deborah (2020-12-07), Reference doc numbers for L2/20-266R "Consolidated code chart of proposed phonetic characters" and IPA etc. code point and name changes | |||||
| Moore, Lisa (2021-01-27), "B.1 — 3a. Phonetic characters", UTC #166 Minutes | |||||
| U+1AC5, 1AC7..1ACA | 5 | Miller, Kirk (2021-01-11), Unicode request for phonetic punctuation & diacritics | |||
| Anderson, Deborah; Whistler, Ken; Pournader, Roozbeh; Moore, Lisa; Liang, Hai (2021-01-14), "3g. Phonetic Punctuation and Diacritics", Recommendations to UTC #166 January 2021 on Script Proposals | |||||
| Moore, Lisa (2021-01-27), "B.1 — 3g. Phonetic Punctuation and Diacritics", UTC #166 Minutes | |||||
Scherer, Markus;
; Freytag, Asmus; Chapman, Christopher; Whistler, Ken; Constable, Peter (2021-04-26), "Consensus 167-C12",
UTC #167 properties feedback & recommendations
,
For Unicode version 14.0, reassign six code points U+1AC9..1ACE as noted in L2/21-069 item PRI428a. |
|||||
Moore, Lisa (2021-05-05), "Consensus 167-C12",
UTC #167 Minutes
,
For Unicode version 14.0, reassign six code points U+1AC9..1ACE as noted in L2/21-069 item PRI428a. |
|||||
| U+1AC6 | 1 | Miller, Kirk; Henry-Rodriguez, Timothy (2020-07-11), Unicode request for Harrington diacritic | |||
| Anderson, Deborah; Whistler, Ken; Pournader, Roozbeh; Moore, Lisa; Constable, Peter; Liang, Hai (2020-07-21), "3e. Harrington diacritic", Recommendations to UTC #164 July 2020 on Script Proposals | |||||
| Moore, Lisa (2020-08-03), "Consensus 164-C12", UTC #164 Minutes | |||||
| U+1ACB..1ACE | 4 | Everson, Michael; (2019-06-10), Proposal to add ten characters for Middle English | |||
| Everson, Michael; West, Andrew (2020-10-05), Revised proposal to add ten characters for Middle English to the UCS | |||||
| Anderson, Deborah; Whistler, Ken; Pournader, Roozbeh; Moore, Lisa; Liang, Hai (2021-01-14), "3l. Ten Characters for Middle English (Ormulum)", Recommendations to UTC #166 January 2021 on Script Proposals | |||||
| Moore, Lisa (2021-01-27), "B.1 — 3l. Ten Characters for Middle English (Ormulum)", UTC #166 Minutes | |||||
| Scherer, Markus; Davis, Mark; Freytag, Asmus; Chapman, Christopher; Whistler, Ken; Constable, Peter (2021-04-26), "PRI428a: Diacritical Marks Extended: Rotate code points U+1AC9..1ACE", UTC #167 properties feedback & recommendations | |||||
Moore, Lisa (2021-05-05), "Consensus 167-C12",
UTC #167 Minutes
,
For Unicode version 14.0, reassign six code points U+1AC9..1ACE as noted in L2/21-069 item PRI428a. |
|||||
|
|||||
См. также
Примечания
- . The Unicode Standard . Дата обращения: 9 июля 2016. 25 сентября 2017 года.
- . The Unicode Standard . Дата обращения: 9 июля 2016. 29 июня 2016 года.
- 2021-05-05
- 1