Искусственный интеллект
- 1 year ago
- 0
- 0

Нейронные сети Кохонена — класс нейронных сетей , основным элементом которых является слой Кохонена . Слой Кохонена состоит из («линейных формальных нейронов »). Как правило, выходные сигналы слоя Кохонена обрабатываются по правилу « Победитель получает всё »: наибольший сигнал превращается в единичный, остальные обращаются в ноль.
По способам настройки и по решаемым задачам различают много разновидностей сетей Кохонена . Наиболее известные из них:
Слой Кохонена состоит из некоторого количества параллельно действующих линейных элементов. Все они имеют одинаковое число входов и получают на свои входы один и тот же вектор входных сигналов . На выходе го линейного элемента получаем сигнал
где:
После прохождения слоя линейных элементов сигналы посылаются на обработку по правилу «победитель забирает всё»: среди выходных сигналов выполняется поиск максимального ; его номер . Окончательно, на выходе сигнал с номером равен единице, остальные — нулю. Если максимум одновременно достигается для нескольких , то:
«Нейроны Кохонена можно воспринимать как набор электрических лампочек, так что для любого входного вектора загорается одна из них» .

Большое распространение получили слои Кохонена, построенные следующим образом: каждому ( -му) нейрону сопоставляется точка в -мерном пространстве (пространстве сигналов). Для входного вектора вычисляются его евклидовы расстояния до точек и «ближайший получает всё» — тот нейрон, для которого это расстояние минимально, выдаёт единицу, остальные — нули. Следует заметить, что для сравнения расстояний достаточно вычислять линейную функцию сигнала:
(здесь — евклидова длина вектора: ). Последнее слагаемое одинаково для всех нейронов, поэтому для нахождения ближайшей точки оно не нужно. Задача сводится к поиску номера наибольшего из значений линейных функций:
Таким образом, координаты точки совпадают с весами линейного нейрона слоя Кохонена (при этом значение порогового коэффициента ).
Если заданы точки , то -мерное пространство разбивается на соответствующие многогранники Вороного-Дирихле : многогранник состоит из точек, которые ближе к , чем к другим ( ) .
Задача векторного квантования с кодовыми векторами для заданной совокупности входных векторов ставится как задача минимизации искажения при кодировании, то есть при замещении каждого вектора из соответствующим кодовым вектором. В базовом варианте сетей Кохонена используется метод наименьших квадратов и искажение вычисляется по формуле
где состоит из тех точек , которые ближе к , чем к другим ( ). Другими словами, состоит из тех точек , которые кодируются кодовым вектором .
Если совокупность задана и хранится в памяти, то стандартным выбором в обучении соответствующей сети Кохонена является метод K-средних . Это метод расщепления:
где — число элементов в .
Далее итерируем. Этот метод расщепления сходится за конечное число шагов и даёт локальный минимум искажения.
Если же, например, совокупность заранее не задана, или по каким-либо причинам не хранится в памяти, то широко используется онлайн метод. Векторы входных сигналов обрабатываются по одному, для каждого из них находится ближайший кодовый вектор («победитель», который «забирает всё») . После этого данный кодовый вектор пересчитывается по формуле
где — шаг обучения. Остальные кодовые векторы на этом шаге не изменяются.
Для обеспечения стабильности используется онлайн метод с затухающей скоростью обучения: если — количество шагов обучения, то полагают . Функцию выбирают таким образом, чтобы монотонно при и чтобы ряд расходился, например, .
Векторное квантование является намного более общей операцией, чем кластеризация , поскольку кластеры должны быть разделены между собой, тогда как совокупности для разных кодовых векторов не обязательно представляют собой раздельные кластеры. С другой стороны, при наличии разделяющихся кластеров векторное квантование может находить их и по-разному кодировать.
Задача векторного квантования состоит, по своему существу, в наилучшей аппроксимации всей совокупности векторов данных кодовыми векторами . Самоорганизующиеся карты Кохонена также аппроксимируют данные, однако при наличии дополнительной структуры в совокупности кодовых векторов ( англ. codebook ). Предполагается, что априори задана некоторая симметричная таблица «мер соседства» (или «мер близости») узлов: для каждой пары ( ) определено число ( ) при этом диагональные элементы таблицы близости равны единице ( ).
Векторы входных сигналов обрабатываются по одному, для каждого из них находится ближайший кодовый вектор («победитель», который «забирает всё») . После этого все кодовые векторы , для которых , пересчитываются по формуле
где — шаг обучения. Соседи кодового вектора — победителя (по априорно заданной таблице близости) сдвигаются в ту же сторону, что и этот вектор, пропорционально мере близости.
Чаще всего, таблица кодовых векторов представляется в виде фрагмента квадратной решётки на плоскости, а мера близости определяется, исходя из евклидового расстояния на плоскости.
Самоорганизующиеся карты Кохонена служат, в первую очередь, для визуализации и первоначального («разведывательного») анализа данных . Каждая точка данных отображается соответствующим кодовым вектором из решётки. Так получают представление данных на плоскости (« карту данных »). На этой карте возможно отображение многих слоёв: количество данных, попадающих в узлы (то есть «плотность данных»), различные функции данных и так далее. При отображении этих слоёв полезен аппарат географических информационных систем (ГИС). В ГИС подложкой для изображения информационных слоев служит географическая карта . Карта данных является подложкой для произвольного по своей природе набора данных. Карта данных служит заменой географической карте там, где географической карты просто не существует. Принципиальное отличие в следующем: на географической карте соседние объекты обладают близкими географическими координатами , на карте данных близкие объекты обладают близкими свойствами. С помощью карты данных можно визуализировать данные, одновременно нанося на подложку сопровождающую информацию (подписи, аннотации, атрибуты, информационные раскраски) . Карта служит также информационной моделью данных. С её помощью можно заполнять пробелы в данных. Эта способность используется, например, для решения задач прогнозирования .
Идея самоорганизующихся карт очень привлекательна и породила массу обобщений, однако, строго говоря, мы не знаем, что мы строим: карта — это результат работы алгоритма и не имеет отдельного («объектного») определения. Есть, однако, близкая теоретическая идея — главные многообразия ( англ. principal manifolds ) . Эти многообразия обобщают линейные главные компоненты . Они были введены как линии или поверхности, проходящие через «середину» распределения данных, с помощью условия самосогласованности : каждая точка на главном многообразии является условным математическим ожиданием тех векторов , которые проектируются на (при условии , где — оператор проектирования окрестности на ),
Самоорганизующиеся карты могут рассматриваться как аппроксимации главных многообразий и популярны в этом качестве .

Метод аппроксимации многомерных данных, основанный на минимизации «энергии упругой деформации» карты, погружённой в пространство данных, был предложен А. Н. Горбанём в 1996 году, и впоследствии развит им совместно с А. Ю. Зиновьевым, А. А. Россиевым и А. А. Питенко . Метод основан на аналогии между главным многообразием и эластичной мембраной и упругой пластиной. В этом смысле он является развитием классической идеи сплайна (хотя упругие карты и не являются многомерными сплайнами).
Пусть задана совокупность входных векторов . Так же, как и сети векторного квантования и самоорганизующиеся карты, упругая карта представлена как совокупность кодовых векторов (узлов) в пространстве сигналов. Множество данных разделено на классы , состоящие из тех точек , которые ближе к , чем к другим ( ). Искажение кодирования
может трактоваться как суммарная энергия пружин единичной жёсткости, связывающих векторы данных с соответствующими кодовыми векторами.
На множестве узлов задана дополнительная структура: некоторые пары связаны «упругими связями», а некоторые тройки объединены в «рёбра жёсткости». Обозначим множество пар, связанных упругими связями, через , а множество троек, составляющих рёбра жёсткости, через . Например, в квадратной решётке ближайшие узлы (как по вертикали, так и погоризонтали) связываются упругими связями, а ребра жёсткости образуются вертикальными и горизонтальными тройками ближайших узлов. Энергия деформации карты состоит из двух слагаемых:
где — соответствующие модули упругости.
Задача построения упругой карты состоит в минимизации функционала
Если разбиение совокупности входных векторов на классы фиксировано, то минимизация — линейная задача с разреженной матрицей коэффициентов. Поэтому, как и для сетей векторного квантования, применяется метод расщепления: фиксируем — ищем — для данных ищем — для данных ищем — … Алгоритм сходится к (локальному) минимуму .
Метод упругих карт позволяет решать все задачи, которые решают самоорганизующиеся карты Кохонена, однако обладает большей регулярностью и предсказуемостью. При увеличении модуля изгиба упругие карты приближаются к линейным главным компонентам. При уменьшении обоих модулей упругости они превращаются в Кохоненовские сети векторного квантования. В настоящее время упругие карты интенсивно используются для анализа многомерных данных в биоинформатике . Соответствующее программное обеспечение опубликовано и свободно доступно на сайте института Кюри ( Париж ) .
На рисунке представлены результаты визуализации данных по раку молочной железы . Эти данные содержат 286 примеров с указанием уровня экспрессии 17816 генов . Они доступны онлайн как ставший классическим тестовый пример для визуализации и картографии данных .

Решается задача классификации . Число классов может быть любым. Изложим алгоритм для двух классов, и . Исходно для обучения системы поступают данные, класс которых известен. Задача: найти для класса некоторое количество кодовых векторов , а для класса некоторое (возможно другое) количество кодовых векторов таким образом, чтобы итоговая сеть Кохонена с кодовыми векторами , (объединяем оба семейства) осуществляла классификацию по следующему решающему правилу:
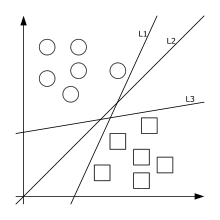
С каждым кодовым вектором объединённого семейства связан многогранник Вороного-Дирихле. Обозначим эти многогранники , соответственно. Класс в пространстве сигналов, согласно решающему правилу, соответствует объединению , а класс соответствует объединению . Геометрия таких объединений многогранников может быть весьма сложной (см. рисунок с примером возможного разбиения на классы).
Правила обучения сети онлайн строится на основе базового правила обучения сети векторного квантования. Пусть на вход системы подаётся вектор сигналов , класс которого известен. Если он классифицируется системой правильно, то соответствующий кодовый вектор слегка сдвигается в сторону вектора сигнала («поощрение»)
Если же классифицируется неправильно, то соответствующий кодовый вектор слегка сдвигается в противоположную сторону от сигнала («наказание»)
где — шаг обучения. Для обеспечения стабильности используется онлайн метод с затухающей скоростью обучения. Возможно также использование разных шагов для «поощрения» правильного решения и для «наказания» неправильного.
Это — простейшая (базовая) версия метода . Существует множество других модификаций.
| Задачи | |
|---|---|
| Обучение с учителем | |
| Кластерный анализ | |
| Снижение размерности | |
| Структурное прогнозирование | |
| Выявление аномалий | |
| Графовые вероятностные модели | |
| Нейронные сети | |
| Обучение с подкреплением | |
| Теория | |
| Журналы и конференции | |