Interested Article - Иерархическая кластеризация
- 2020-01-25
- 1

Иерархическая кластеризация (также графовые алгоритмы кластеризации и иерархический кластерный анализ ) — совокупность алгоритмов упорядочивания данных, направленных на создание иерархии ( дерева ) вложенных кластеров. Выделяют два класса методов иерархической кластеризации:
- Агломеративные методы ( англ. agglomerative ): новые кластеры создаются путем объединения более мелких кластеров и, таким образом, дерево создается от листьев к стволу;
- Дивизивные или дивизионные методы ( англ. divisive ): новые кластеры создаются путем деления более крупных кластеров на более мелкие и, таким образом, дерево создается от ствола к листьям.
Алгоритмы иерархической кластеризации предполагают, что анализируемое множество объектов характеризуется определённой степенью связности. По количеству признаков иногда выделяют монотетические и политетические методы классификации. Как и большинство визуальных способов представления зависимостей графы быстро теряют наглядность при увеличении числа кластеров. Существует ряд специализированных программ для построения графов .
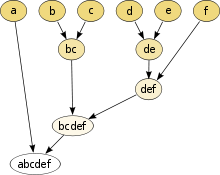
Дендрограмма

Под дендрограммой обычно понимается дерево , построенное по матрице мер близости. Дендрограмма позволяет изобразить взаимные связи между объектами из заданного множества . Для создания дендрограммы требуется матрица сходства (или различия ), которая определяет уровень сходства между парами кластеров. Чаще используются агломеративные методы.
Для построения матрицы сходства (различия) необходимо задать меру расстояния между двумя кластерами. Наиболее часто используются следующие методы определения расстояния ( англ. sorting strategies ) :
- Метод одиночной связи ( англ. single linkage ), также известен, как «метод ближайшего соседа». Расстояние между двумя кластерами полагается равным минимальному расстоянию между двумя элементами из разных кластеров: , где — расстояние между элементами и , принадлежащими кластерам и
- Метод полной связи ( англ. complete linkage ), также известен, как «метод дальнего соседа». Расстояние между двумя кластерами полагается равным максимальному расстоянию между двумя элементами из разных кластеров: ;
- Метод средней связи ( англ. pair-group method using arithmetic mean ):
-
Центроидный метод
(
англ.
pair-group method using the centroid average
):
- Невзвешенный ( англ. UPGMC ). Расстояние между кластерами полагается равным расстоянию между их центроидами (центрами массы) : , где и — центройды и .
- Взвешенный ( англ. WPGMC ).
- Метод Уорда ( англ. Ward’s method ). В отличие от других методов кластерного анализа, для оценки расстояний между кластерами здесь используются методы дисперсионного анализа. В качестве расстояния между кластерами берётся прирост суммы квадратов расстояний объектов до центра кластера, получаемого в результате их объединения : . На каждом шаге алгоритма объединяются такие два кластера, которые приводят к минимальному увеличению дисперсии. Этот метод применяется для задач с близко расположенными кластерами.





















Для первых трёх методов существует общая формула, предложенная А. Н. Колмогоровым для мер сходства :
![K_{\eta }([i,j],k)=\left[{\frac {(n_{i}K(i,k)^{\eta }+(n_{j}K(j,k)^{\eta })}{n_{i}+n_{j}}}\right]^{{\frac {1}{\eta }}},-{\mathcal {1}}\leqslant \eta \leqslant +{\mathcal {1}}](/images/005/327/5327133/24.jpg?rand=326313)
где — группа из двух объектов (кластеров) и ; — объект (кластер), с которым ищется сходство указанной группы; — число элементов в кластере ; — число элементов в кластере . Для расстояний имеется аналогичная формула Ланса — Вильямса .
![[i,j]](/images/005/327/5327133/25.jpg?rand=423961)







Корреляционные плеяды

Широко применяются в геоботанике и флористике . Их часто называют корреляционными плеядами .
Частным случаем является метод, известный как метод построения оптимальных деревьев (дендритов) , который был предложен математиком львовской школы Гуго Штейнгаузом , впоследствии метод был развит математиками вроцлавской таксономической школы . Дендриты также не должны образовывать циклов. Можно частично использовать направленные дуги графов при использовании дополнительно мер включения (несимметричных мер сходства).
Метод «диагонализации» матрицы различия и графическое изображение кластеров вдоль главной диагонали матрицы различия (диаграмма Чекановского) впервые предложен Яном Чекановским в 1909 году . Приведём описание методики:
Сущность этого метода заключается в том, что всю амплитуду полученных величин сходства разбивают на ряд классов, а затем в матрице величин сходства заменяют эти величины штриховкой, различной для каждого класса, причём обычно для более высоких классов сходства применяют более тёмную штриховку. Затем, меняя порядок описаний в таблице, добиваются того, чтобы более сходные описания оказались рядом
Приведём гипотетический пример получения вышеуказанной диаграммы. Основой метода является построение матрицы транзитивного замыкания .

Для построения матрицы транзитивного замыкания возьмём простую матрицу сходства и умножим её саму на себя:

где — элемент, стоящий на пересечении -ой строки и -го столбца в новой (второй) матрице, полученной после первой итерации; — общее количество строк (столбцов) матрицы сходства. Данную процедуру необходимо продолжать, пока матрица не станет идемпотентной (то есть самоподобной): , где n — число итераций.





Далее преобразовываем матрицу таким образом, чтобы близкие числовые значения находились рядом. Если каждому числовому значению присвоить какой-либо цвет или оттенок цвета (как в нашем случае), то получим классическую диаграмму Чекановского. Традиционно более тёмный цвет соответствует большему сходству, а более светлый — меньшему. В этом она схожа с теплокартой для матрицы расстояний .
См. также
Источники и примечания
- Жамбю М. Иерархический кластер-анализ и соответствия. — М.: Финансы и статистика, 1988. — 345 с.
- Классификация и кластер. Под ред. Дж. Вэн Райзина. М.: Мир, 1980. 390 с.
- Sneath P.H.A., Sokal R.R. Numerical taxonomy: The principles and practices of numerical classification. — San-Francisco: Freeman, 1973. — 573 p.
- Ward J.H. Hierarchical grouping to optimize an objective function // J. of the American Statistical Association, 1963. — 236 р.
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: Классификация и снижение размерности. — М.: Финансы и статистика, 1989. — 607 с.
- Lance G.N., Willams W.T. A general theory of classification sorting strategies. 1. Hierarchical systems // Comp. J. 1967. № 9. P. 373—380.
- von Terentjev P.V. от 5 марта 2016 на Wayback Machine // Biometrika. 1931. № 23(1-2). P. 23-51.
- Терентьев П. В. Метод корреляционных плеяд // Вестн. ЛГУ. № 9. 1959. С. 35-43.
- Терентьев П. В. Дальнейшее развитие метода корреляционных плеяд // Применение математических методов в биологии. Т. 1. Л.: 1960. С. 42-58.
- Выханду Л. К. Об исследовании многопризнаковых биологических систем // Применение математических методов в биологии. Л.: вып. 3. 1964. С. 19-22.
- Штейнгауз Г. Математический калейдоскоп. — М.: Наука, 1981. — 160 с.
- Florek K., Lukaszewicz S., Percal S., Steinhaus H., Zubrzycki S. Taksonomia Wroclawska // Przegl. antropol. 1951. T. 17. S. 193—211.
- Czekanowski J. Zur differential Diagnose der Neandertalgruppe // Korrespbl. Dtsch. Ges. Anthropol. 1909. Bd 40. S. 44-47.
- Василевич В. И. Статистические методы в геоботанике. — Л.: Наука, 1969. — 232 с.
- Tamura S., Hiquchi S., Tanaka K. от 17 мая 2017 на Wayback Machine // IEEE transaction on systems, man, and cybernetics, 1971, SMC 1, № 1, P. 61-67.
| Задачи | |
|---|---|
| Обучение с учителем | |
| Кластерный анализ | |
| Снижение размерности | |
| Структурное прогнозирование | |
| Выявление аномалий | |
| Графовые вероятностные модели | |
| Нейронные сети | |
| Обучение с подкреплением | |
| Теория | |
| Журналы и конференции | |
- 2020-01-25
- 1
