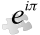Математическая статистика
- 1 year ago
- 0
- 0

Семплирование — в математической статистике обобщенное название методов управления начальной выборкой при известной цели моделирования, которые позволяют выполнить структурно-параметрическую идентификацию наилучшей статистической модели стационарного эргодического случайного процесса.
Научная новизна метода семплинга состоит в том, что он является эффективным приемом для логичного смыслового увязывания статистических свойств выборки и цели моделирования. При этом семплинг повышает размерность критериального пространства, и одновременно выступает средством разрешения проблемы парето-оптимальности за счет разделения частных критериев и их ранжирования (структурный критерий рангом выше параметрического, поэтому эти критерии не вступают в противоречие). Н. Н. Чубуков приводит следующий пример . Пусть случайный процесс представлен выборкой объёма : . Необходимо решить три задачи:
Если взять для моделирования традиционный подход, ориентированный на единственность описания статистических свойств процесса, то результатом будут три совершенно одинаковые функции. Дело в том, что правилом расчета критерия качества модели не учитывались существенные детали: горизонт прогноза, характер статистических трендов случайного процесса , представленного выборочными данными, и совершенно игнорировалась целевая специфика задач .
Выходом из данного затруднения может стать использование в рамках семплинга принципа разнообразия, который известен и применяется для решения инженерных задач путем применения приема перекрестной валидации данных, например, бутстреп-анализ , метод группового учета аргументов и др. Проявление принципа разнообразия в решениях статистических задач состоит в том, что на незнание вероятностных свойств исходных данных алгоритм отвечает разнообразием генерируемых структур моделей, каждая из которых подвергается кросс-проверке на оптимальность по определенной единой для всех моделей схеме.
Семплинг является современным методом, который может оказаться практически полезным для решения задач математической статистики, в том числе, обратных и некорректных задач . Семплинг реализует принцип разнообразия и может обобщать весь спектр средств статистического анализа, основанный на управлении исходными данными. Под семплингом понимается набор приемов для разбиения исходной выборки на рабочие и контрольные участки по правилам, соответствующих целям моделирования. На рабочих участках выполняется расчет параметров «конкурирующих» моделей, на контрольных оценивается их способность восстанавливать значения, которые не использовались для расчета параметров.
Семплирование методически корректно «обходит» основное препятствие, объективно присутствующее в обратных задачах. Его причина кроется в невозможности установления строгой математической связи между варьируемым параметром и численным значением критерия оптимальности модели. При этом семплинг переводит алгоритм структурно-параметрической идентификации модели из разряда строго математических в класс эвристических, и делает его перспективным для создания систем искусственного интеллекта .
В отношении вышеприведенного примера, первому случаю — «длинной» экстраполяции за пределы выборки, соответствует вариант семплинга с исключением из расчетов параметров модели десяти последних выборочных значений подряд. Контрольным будет десятый отсчет. Рабочая подвыборка составит все значения, за исключением этой десятки. Затем альтернативным перебором определяется наилучшая модель, которая точнее других спрогнозировала контрольную точку. Изменением положения исключенных отсчетов, без нарушения их числа и неразрывности, формируется статистика невязок, применимая для расчета критерия и «трубки» статистической устойчивости для оценивания достоверности результата. Алгоритм как бы «экзаменует» модели по экстраполяции на заданную глубину, и выбирает из них ту, которая наиболее точно улавливает «длинные» тренды, содержащие информацию о значениях на лаге длиной в десять отсчетов. При этом «короткострельные» модели будут подвергаться дискриминации.
Второй задаче будет соответствовать семплирование с исключением из расчетов по одной контрольной точке, с комбинированием количества, и порядка учитываемых для прогноза предыдущих значений. В этом случае «длиннотрендовые» модели будут «подавляться», а моделям, дающим точные ближние прогнозы — напротив, будет отдаваться предпочтение.
В третьей задаче будет оправдано дробление выборки на взаимопроникающие блоки, когда контрольные значения «вкраплены» между рабочими. Длина таких блоков и глубина их взаимопроникновения должна учитывать интервалы между соседними точками диапазона, требуемые устойчивость и точность оценок. Так, третьей задаче может соответствовать исключение из расчетов каждого третьего отсчета выборки и применение исключенных данных для контроля с циклическим переназначением контрольных и рабочих подвыборок.