Interested Article - Асинхронная логика

- 2021-05-31
- 1
Асинхро́нная ло́гика — разновидность взаимодействия логических элементов цифровых устройств . Отличается от синхронной тем, что её элементы действуют асинхронно , не подчиняясь глобальному генератору тактовых импульсов .
Описание
Асинхронные схемы управляются двумя сигналами: запрос , который выдается после установки входов и ответ . Относительно пары этих сигналов переходной процесс в асинхронной схеме моделируется элементом задержки , величина которой конечна и заранее неизвестна. В синхронных схемах аномалии динамического поведения (состязания и риски) маскируются с помощью тактового генератора. Для борьбы с аномалиями в асинхронных схемах используется механизм индикации , который фиксирует моменты окончания переходных процессов. Готовность сигналов индикации определяется величинами реальных задержек, которые могут изменяться и зависят от условий функционирования схемы (например от температуры). Физически, индикатор окончания переходных процессов в схеме может отсутствовать, тогда его роль выполняют специальные самосинхронные коды . Таким образом, по сравнению с синхронными схемами, асинхронные в общем случае, содержат больше логических элементов. Основные преимущества асинхронных схем по сравнению с синхронными это :
- устойчивая работа — отсутствие сбоев при любых возможных условиях эксплуатации;
- безопасная работа — остановка в момент появления неисправности любого элемента;
- отсутствие периодов вынужденного простоя в ожидании очередного синхроимпульса.
Синхронные схемы практически любого уровня сложности могут быть реализованы на относительно дешевых ПЛИС . Напротив, строго-самосинхронные схемы предъявляют очень жесткие требования к внутренней структуре ПЛИС и практически единственным решением является изготовление ПЛИС на заказ . Однако, стоит отметить попытки реализации асинхронных схем на биполярных ПЗУ , стандартных PAL (CPLD) и FPGA . Поскольку стандартные FPGA являются синхронными устройствами, на них относительно легко построить схемы с согласованной задержкой и, сложнее, локально-синхронные (GALS) схемы . В большинстве стандартных FPGA отсутствуют средства реализации арбитров. Один из способов обойти это ограничение представлен в . В статье для реализации строго-самосинхронной схемы предлагается модифицировать FPGA Atmel AT40K с очень мелким размером элементарной ячейки (fine grained) , . Реализация С-элемента на двух LUT предложена в .
Общие замечания

- При проектировании цифровых устройств принято функционально разделять операционный и управляющий блоки. Операционный блок отвечает за обработку данных (data path ) и получает команды от управляющего блока (control path). Во многих отношениях такое разделение достаточно условно . Некоторые устройства, например, асинхронная шина, кольцевой интерфейс, арбитр с иерархической структурой и счетчик по модулю n практически не обрабатывают данные, но имеют сложный алгоритм управления. Другие устройства, такие как асинхронный банк регистров или параллельное n-разрядное АЛУ предназначены для интенсивной обработки данных, но управление ими достаточно простое.
- Асинхронные схемы, как и любые схемы с памятью, требуют задания начальных условий. На практике это осуществляется подачей короткого импульса сброса соответствующей полярности на запоминающие элементы. Подробнее см. .
- Для правильной работы асинхронных схем необходимо задать поведение внешней среды. Схема, недистрибутивная для одной внешней среды, может оказаться дистрибутивной для другой, последовательной для третьей и неполумодулярной для четвёртой.
Модели и классификация асинхронных схем


Асинхронная схема может рассматриваться как аппаратная реализация параллельной распределенной программы . Для выполнения такой программы во времени обычно необходим какой-либо механизм, в то время как асинхронной схеме этот механизм не нужен. Аналогами операторов и команд в асинхронной схеме являются логические элементы, триггеры или сложные иерархические модули. Роль данных, которыми обмениваются элементы схемы, играют переключения сигналов. Таким образом, все события в схеме уровне упорядочены во времени через причинно-следственные связи. Порядок, установленный разработчиком должен быть сохранен в схеме, то есть фактически сгенерирован, что в конечном счете обеспечивает правильное функционирование. В общем случае, классификация самосинхронных схем довольно сложна и неоднозначна . Однако, существуют по крайней мере две достаточно общие модели таких схем с разными предположениями о задержке в элементах, проводах и их соединениях :
- Mодель с ограниченной задержкой (модель Хаффмана, Huffman model ), в которой предполагается максимальная задержка распространения сигналов в схеме (наихудший случай). Для построения таких схем нужно вводить задержку в цепь обратной связи либо использовать локальную синхронизацию. Таким образом, схемы построенные в соответствии с моделью Хаффмана не являются строго самосинхронными. Пример использования модели Хаффмана — это различные варианты микроконвейеров ( micropipelines ) с согласованной задержкой . В общем случае нехаффменовские модели — это модели, использующие динамические языки спецификации, для формального анализа или синтеза. Операционные устройства таким образом представить затруднительно.
-
Mодель с неограниченной задержкой до точки разветвления (модель Маллера,
model
), в которой предполагается, что разница в задержке проводов после разветвления меньше, чем минимальная задержка элемента. Схемы построенные в соответствии с моделью Маллера делятся на несколько классов:
- схемы, не зависящие от скорости ( speed-independent, SI circuits );
- полумодулярные или/и дистрибутивные ( semi-modular or/and distributive ) схемы;
- схемы квазинечувствительные к задержкам ( ).
Дистрибутивные схемы являются подмножеством полумодулярных, которые в свою очередь, являются подмножеством SI-схем. На практике, класс SI-схем эквивалентен классу QDI. Теория и методы проектирования QDI-схем хорошо развиты и, поэтому, такие схемы наиболее популярны для реализации.
Сложные асинхронные системы нельзя однозначно представить ни моделью Хаффмана ни моделью Маллера. Такие системы могут быть построены как асинхронные конечные автоматы или, в очень крупном масштабе, как асинхронные микропроцессорные комплекты , использующие микропрограммное управление . Подобные комплекты представлены сериями К587 , К588 и К1883 (U83x в ГДР ) . Обучение проектированию сложных последовательных самосинхронных схем целесообразно начинать с реализации простого одноразрядного процессора MC14500B и объединения таких процессоров в вычислительную структуру .
Сильная (И) и слабая (ИЛИ) обусловленность
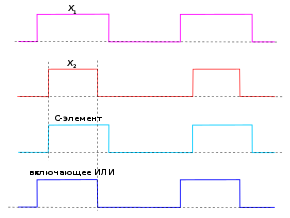

На интуитивном уровне, обусловленность (причинная-следственная связь, causality) в асинхронных схемах — это зависимость порядка появления выходных сигналов от порядка появления входных. Эта зависимость может быть сильной (И) и слабой (ИЛИ), что соответствует схемам с полной индикацией (full indication) и досрочным получением результата (early evaluation) .
Предположим, что некоторое событие имеет две причины: и . И-обусловленность предполагает, что оба события и должны иметь место, прежде чем может произойти событие . Таким образом, в случае И, каждая причина сильно предшествует результату. Аналогом такого поведения в социологии является коллективизм и товарищество. В случае ИЛИ-обусловленности событие может произойти после того, как любое из событий или произошло (здоровый индивидуализм).








Таким образом, в случае ИЛИ, результат появляется если по крайней мере одно событие из набора слабых причин произошло. Чтобы определить как ведет себя событие после того, как обе его слабые причины и произошли, вводятся понятия совместной и несовместной обусловленности (соответственно управляемый и неуправляемый индивидуализм). Для двух входных сигналов И-обусловленность моделируется с помощью гистерезисного триггера (Г-триггер, ), заданного уравнением . Модель совместной ИЛИ-обусловленности — это элемент «включающее ИЛИ» (inclusive OR , EDLINCOR ), который использует выход гистерезисного триггера и задается уравнением . Модель полностью несовместной ИЛИ-обусловленности — это схемы, основанные на арбитрах.






Рассмотрим асинхронную схему, в которой есть двухвходовый элемент ИЛИ (двухвходовый элемент И). В фазе гашения на входе элемента ИЛИ установлен код 00 , а на входе элемента И — код 11 . В рабочей фазе входы один за другим переключатся в 1 (0) . Необходимо индицировать оба эти изменения, но в случае ИЛИ-обусловленности процесс будет развиваться по одному входу, а затем второй вход где-то индицируется. Иными словами, процесс начинает ветвиться по первому изменению входа, без ожидания второго, то есть без синхронизации со вторым сигналом. Чем больше таких элементов, тем больше параллельность в схеме. Синхронизация входов возможна, но нежелательна, так как это будет другой процесс с меньшей параллельностью.
Есть два основных метода моделирования ИЛИ-обусловленности на сетях Петри (или STG). Один способ — это уход от явного представления параллельности на уровне переходов сети Петри к уровню так называемой семантики чередования ( англ. interleaving semantics ) (то есть с выбором на трейсах) — при этом сохраняется 1-безопасность сети Петри. Другой способ — это сохранение явного представления параллельности, но при этом сеть Петри становится не 1-безопасной . Таким образом, ИЛИ-обусловленность описывается либо небезопасной, но устойчивой сетью Петри, либо безопасной, но неустойчивой.
Оба типа обусловленности приводят к полумодулярным схемам. Однако, в случае И-обусловленности эти схемы являются дистрибутивными, а в случае ИЛИ — недистрибутивными. Дистрибутивные схемы могут быть построены из элементов только одного типа (например, И-НЕ или ИЛИ-НЕ), а недистрибутивные требуют использования обоих типов элементов. В случае небезопасной, но устойчивой сети Петри необходимо также бороться с накоплением точек в вершинах OR-causality. Методологии DIMS и NCL, как и любые другие методологии с полной индикацией, имеют все преимущества и недостатки И-обусловленности. Графы сигнальных переходов в своем наиболее простом варианте также реализуют полную индикацию. Диаграммы изменений позволяют моделировать как И-, так и совместную ИЛИ-обусловленность, но не могут напрямую представлять процессы с конфликтами или выбором.
Теорема о соединении полумодулярных схем
Пусть схемы и полумодулярны относительно состояний и соответственно, при этом является выходом инвертора схемы . Разомкнём узел схемы так, что образуются вход и выход . Предположим, что среди состояний в которые могут перейти схемы и из и найдутся такие и в которых значение сигнала на входе и на выходе инвертора совпадает с и с соответственно. Удалим из схемы инвертор так, что образуются вход и выход . Соединим с и с . Можно утверждать, что полученная схема полумодулярна относительно состояния . Интуитивное доказательство теоремы приводится в . Строгое математическое доказательство можно найти в . Важно отметить, что соединение двух схем по теореме требует выполнения двух условий: 1) в одной из схем должен быть инвертор и 2) наличия состояний и . Эти условия выполняются не всегда и, следовательно не любые полумодулярные схемы можно соединять в одну. Обобщение теоремы для более мягких условий приводится в . Частным случаем использования теоремы является повышение быстродействия счетчиков с последовательным переносом . В общем случае, применение теоремы дает качественно новую схему из известных составляющих, например пайплайн на Г-триггерах + статический триггер = асинхронный регистр сдвига.

























![{\displaystyle [a',b']}](/images/005/343/5343166/46.jpg?rand=12120)


Двухпроводная линия связи
Простые синхронные схемы можно соединять между собой практически без проблем. Если в полученной сложной схеме отсутствуют критические гонки сигналов, она будет работоспособной. Соединение асинхронных схем гораздо сложнее, в полученной сложной схеме свойство асинхронности может быть утеряно. Результатом этого будет остановка работы или наоборот, генерация пачки импульсов. Если не рассматривать общий провод, то тактовый сигнал на синхронную схему подается по одному проводу. Связать асинхронные схемы можно также по одному проводу но для этого нужно использовать специальный последовательный самосинхронный код. По сравнению с параллельным кодом, это означает более низкое быстродействие и дополнительные расходы оборудования. Для повышения быстродействия можно представлять разделитель (spacer) третьим уровнем сигнала . Это позволяет также уменьшить количество проводов (если слоев металлизации не больше двух), но не позволяет переключать линии от разных задатчиков разным исполнителям, то есть не приспособлено для шинных структур. Поскольку в современных технологиях используются 7-14 слоев металлизации, экономить таким образом на проводах не имеет смысла. Два провода позволяют использовать парафазный протокол связи. Впервые такой подход был использован Д. Е. Маллером для построения строго самосинхронного микроконвейера . Близким к этому способу является Delay Insensitive Minterm Synthesis (DIMS) . Методология Null Convention Logic (NCL) также предназначена для синтеза строго самосинхронных микроконвейеров. В отличие от DIMS, где используются C-элементы, NCL использует многовходовые Г-триггеры, которые называются пороговыми элементами и самосинхронный код М-из-N. В некоторых случаях это позволяет строить более простые схемы. Заметим, что в силу использования Г-триггеров, микроконвейеры DIMS и NCL реализуют только И-обусловленность . Некоторые способы построения микроконвейеров с ИЛИ-обусловленностью рассмотрены в . Строго самосинхронные микроконвейерные схемы также могут быть синтезированы при компиляции программ с языков высокого уровня. Следует однако, ожидать, что полученные таким образом схемы будут не оптимальными. Например, сумматор синтезированный в сложнее, чем предложенный в .
Асинхронные примитивы
Идея использования примитивов для построения асинхронной схемы аналогична идее конструктора. Детали такого конструктора должны быть по возможности, универсальными . Как правило, они описываются фрагментами устойчивых и безопасных сетeй Петри . Наиболее известные асинхронные примитивы это:
Буферный регистр

Впервые предложен в под названием double-line delay (см. также ) и наиболее известен как weak condition half buffer, WCHB .
Ячейка Давида

Названа по фамилии французского инженера René David впервые её предложившего . Транзисторная реализация ячейки называется one place buffer , её обобщения рассматриваются в .
Схема повторного вхождения

Была впервые предложена в и усовершенствованна в . В последнем варианте рассматривается в и известна как multiple use circuit , D-element , Q-element и S-element .
Счётный триггер


Также называемый toggle представляет собой делитель частоты на два, в котором обеспечивается завершение переходных процессов. Ранние версии toggle, построенные на элементах с инверсией на входах приведены в . Диаграмма переходов схемы показана на рис. 5.31 в . Задержка входных инверторов во всех этих схемах предполагается нулевой, а индикатором служит либо элемент XOR либо элемент XNOR. Вариант toggle, использующий дуальные логические элементы 1И-2ИЛИ-НЕ и 1ИЛИ-2И-НЕ приводится в . Заметим, что такая реализация известна по крайней мере с 1971 года . Другой вариант toggle, использующий те же элементы и два инвертора предложен в и подробно обсуждается в . Реализация toggle только на элементах И-НЕ (ИЛИ-НЕ) иногда называется гарвардский триггер и известна по крайней мере с 1964 года . Компактные статические схемы гарвардского триггера на КМОП транзисторах приведены в , a схема с нагрузочными резисторами — в . Динамическая схема счётного триггера, где предыдущее состояние хранится на емкостях приведена в . Заметим, что большинство счётных триггеров представляют собой последовательностные схемы и поэтому могут быть реализованы только на элементах 2И-НЕ. Существуют, однако, дистрибутивные схемы счётного триггера. Например, в описывается дистрибутивная и очевидно громоздкая схема на четырёх логических и двух С-элементах. Более удачным примером является дистрибутивная схема JK-триггера на 2И-НЕ. Объединив входы J и K, получим счётный триггер.
Последовательное соединение счётных триггеров даёт многоразрядный счетчик, в котором количество срабатываний разряда вдвое меньше, чем количество срабатываний разряда . Чтобы обеспечить в таких счетчиках независимость от задержек обычно используется индикатор завершения переходных процессов во всех разрядах . Схема конвейерного счетчика впервые предожена в , запатентована в и перепечатана в . Спецификации и схемы счётчиков с постоянным временем ответа приведены в . Также, в приводится последовательный счётчик с задержкой распространения переносов. В предложен программируемый счётчик, в котором взаимодействие с внешней средой осуществляется через последний разряд. За счёт этого достигается постоянное время реакции между запросом к счётчику и ответом. Тот ответ, который получен после N запросов является сигналом с частотой поделённой на N.


Методологии проектирования
При проектировании асинхронной схемы необходимо сделать предположение о задержках. Методология самосинхронизации использует гипотезу Маллера относительно задержек в проводах — вся задержка провода приведена к выходу элемента, а разбросом задержек в проводах после разветвления можно пренебречь. В этом случае провода вообще исключаются из рассмотрения. Нарушение гипотезы Маллера приводит к нарушению причинной обусловленности поведения, являющейся логической основой самосинхронизации. Причинная обусловленность требует, чтобы каждое событие в системе являлось причиной, по крайней мере, одного другого события (свойство индицируемости самосинхронных систем ). В логических структурах, в отличие от систем передачи, изменение состояния отрезка провода после разветвления может не приводить к переключению логического элемента и, следовательно, не индицироваться. При этом отрезок провода начинает выступать как элемент памяти. Для борьбы с этим, то есть для построения схем, не зависящих от задержек в проводах, необходимо использование либо специальных дисциплин переключения (что сужает класс реализуемых схем ), либо использование специальных логических или топологических конструкции, как, например, изохронные разветвления или разветвления полем (field forks ), требующих введения новых гипотез или/и приемов проектирования, зависящих от технологии. Эта проблема усугубляется с ростом влияния задержек в проводах и разброса этих задержек. Подавляющее большинство современных методологий проектирования приводят к схемам квази-нечувствительным к задержкам, то есть к схемам где все разветвления являются достаточно короткими и поэтому изохронными . Основная задача синтеза асинхронных схем формулируется так . Задается спецификация, моделирующая реальный процесс. Затем она анализируется чтобы выявить как полезные, так и аномальные свойства процесса. По результатам анализа исходная спецификация модифицируется с целью предотвращения или/и устранения аномалий. По новой, модифицированной спецификации синтезируется схема, поведение которой совпадает с исходной спецификацией. Краткий список методов анализа и синтеза асинхронных схем на основе моделей событийного типа приведен в . Полный цикл использования этих моделей в современных средствах разработки обсуждается в . Методы синтеза основанные на компиляции программ с языков высокого уровня, а также на теории трейсов рассмотрены в .
Сети Петри
Для моделирования поведения логических схем обычно используют устойчивые и безопасные сети Петри . Однако, такие сети не могут моделировать досрочное получение результата, поскольку срабатывание переходов основано на И-обусловленности. Чтобы описать ИЛИ-обусловленность, сеть должна быть небезопасной (более одного маркера в позиции). Когда поведение схемы задано, необходимо преобразовать сеть Петри в диаграмму изменений (диаграмму Маллера), которая является графом с вершинами, обозначенными вектором из устойчивых и возбужденных выходов элементов. Далее следует убедиться, что полученная диаграмма является полумодулярной. Если нет, то это означает, что исходное описание схемы в виде сети Петри является неполным и следует вводить дополнительные события. Если диаграмма изменений полумодулярна, то можно по диаграмме переходов строить функции возбуждения элементов. Далее если эти функции находятся в списке элементов базиса реализации, то все в порядке. Если же нет, то нужно вводить дополнительные переменные, а следовательно, и изменять исходное задание таким образом, чтобы все функции элементов соответствовали функциям базиса реализации. Эта проблема очень сложна и ее формальное решение далеко от оптимальной реализации.
Сигнальные графы


Основаны на сетях Петри, переходы в которых помечены именами сигналов. Впервые были предложены в и описаны более подробно в двух различных подходах в и . Наиболее известны сейчас под названием англ. .
Самый простой класс STG — STG/MG соответствует классу маркированных графов сетей Петри. Это сети Петри, где каждая позиция имеет максимум один входной переход и один выходной переход. В таком графе позиция может иметь только маркеры, удалённые из него через одиночный переход, ведущий от него и переход, однажды разрешённый, может быть запрещен только при фактическом запуске, поэтому не может быть обработана ситуация, где могут происходить А или B, но не оба. Отметим, что графически STG заменяет помеченный переход его меткой, и позиции с одним входом и одним выходом опускаются. Маркеры в этих опущенных положениях просто помещаются на соответствующую дугу. В STG метки переходов содержат не только имя сигнала, но также и определенный тип перехода, нарастающий («+») или спадающий («-»).
Таким образом, когда запускается переход, помеченный , сигнал переключается из 0 в 1; когда запускается переход, помеченный , сигнал переключается из 1 в 0. Переходы на входных сигналах также различаются подчеркиванием. Чтобы создавать схемы по STG, часто требуются выполнения одного или нескольких ограничений: живучести, надежности, постоянства, непротиворечивого назначения состояния, уникального назначения состояния, одноцикловых переходов.




STG живой, если от каждой доступной маркировки каждый переход может быть, в конце концов, запущен.
STG надёжен, если никакая позиция или дуга никогда не могут содержать больше одного маркера.
STG постоянен, если для всех дуг а* → b* (где t* означает переход t+ или t-) имеются другие дуги, гарантирующие, что b* запустится перед противоположным переходом a*.
STG имеет непротиворечивое назначение состояния, если переходы сигнала строго чередуются между + и — (т.e. нельзя возвращаться к тому же состоянию).
STG имеет уникальное назначение состояния, если никакие две различных маркировки STG не имеют идентичных значений для всех сигналов.
STG имеет одноцикловые переходы, если каждое имя сигнала в STG появляется в точно одном нарастающем одном спадающем переходе.
Диаграммы изменений

Диаграммы изменений ( англ. Change Diagrams, CD ) подобно STG имеют узлы, маркированные у переходов, и дуги между переходами, которые определяют разрешённые последовательности запуска переходов. CD имеют дуги трех типов: сильного предшествования, слабого предшествования и несвязанного сильного предшествования, а также начальную маркировку, хотя маркеры помещаются в переходы CD вместо позиций. Дуги сильного предшествования подобны дугам в STG и их можно считать дугами AND, так как переход не может запускаться, пока все дуги, указывающие на него, не отмечены маркером. Дуги слабого предшествования являются дугами OR, где переход может запускаться всякий раз, когда какой-либо переход с дугой слабого предшествования к нему отмечен маркером. Заметим, что переход не может иметь сильные и слабые дуги одновременно. Когда дуги сильного или слабого предшествования заставляют переход запускаться, на всех дугах, указывающих на этот переход, маркер удаляется и помещается на все дуги, разрешающие запуск перехода. Поскольку переход с дугами слабого предшествования, ведущими к нему, может запускаться раньше всех дуг, имеющих маркеры, дуги без маркеров имеют открытые циклы, добавленные к ним для индикации «долга» одного маркера. Когда маркер достигает дуги с долгом, маркер и долг взаимно уничтожаются. Таким образом, если маркер приходит на каждую входную дугу слабого предшествования к узлу (если ни одна из этих дуг изначально не отмечена маркерами или открытыми циклами), он будет запускаться только однажды, и может делать это, как только прибудет первый маркер. Наконец, освобождаемые дуги сильного предшествования идентичны дугам сильного предшествования, за исключением того, что после перехода, ведущего к запуску, дуга больше не сдерживает систему (считается удаляемой из CD). Таким образом, эти дуги могут использоваться для связи начального, неповторяющегося набора переходов с бесконечно повторяющимся циклом.
Обусловленные логические сети
Впервые были предложены в под названием англ. Causal Logic Nets, CLN с целью объединить преимущества сетей Петри и диаграмм изменений в представлении различных форм причинно-следственных связей .
NCL подход
Сокращение NCL означает Null Convention Logic и указывает на использование разделителя 00 . Подход NCL был предложен в для операционных блоков, состоящих преимущественно из самосинхронной комбинационной логики.
Элементы NCL являются частным случаем обобщенного C-элемента, который задан с помощью разложения Шеннона как , где и — это функции установки и сброса. Если эти функции ортогональны, то есть , то и изотонна (positive unate) по . Таким образом, можно исключить, так что . NCL использует пороговые функции установки и сброса, которые имеют не более 4 переменных. В NCL также используются 3 непороговые функции, которые могут быть реализованы несколькими NCL элементами. В дополняющем подходе NCL+ используется разделитель 11 . Функция сброса для NCL одна , а функций установки несколько . Для NCL+ наоборот, функция установки одна , а функций сброса несколько . Результатом этого является определённая симметрия между КМОП реализациями элементов NCL и NCL+ , . Однако, такие реализации очень громоздкие, например, элемент TH24 состоит не менее, чем из 26 транзисторов . Построение операционных блоков на NCL называется . Эти блоки представляют собой связанные осцилляторы, которые производят параллельные вычисления. Подобный принцип используется в двумерных распределителях , .











Отметим, что подход подобный NCL, был предложен гораздо раньше в . Этот подход использует либо NCL элементы (Г-триггеры специального типа) либо обычные, многовходовые элементы И-ИЛИ-НЕ . В обоих случаях на элементы подаются парафазные сигналы. На уровне поведения, связь между этим подходом и NCL рассматривается в .
Отметим также, что поскольку пороговые функции являются подмножеством монотонных, оба упомянутых подхода могут рассматриваться как развитие последовательностных схем на пороговых элементах .
Предположения о длительности задержек
Иногда заданное поведение невозможно реализовать в модели Маллера (задержки элементов неограничены). Как правило, эта проблема связана с заданным базисом реализации. Единственным решением в этом случае является использование предположений о длительности задержек элементов (timing assumptions). Перечислим некоторые признаки таких проблемных поведений:
- Входной сигнал переключается два раза подряд, что приводит к переключению выхода . Другими словами, в поведении имеется фрагмент . Такое поведение не реализуемо в любом базисе. Необходимо предположение о том, что длительности импульса достаточно для (как минимум) двух переключений внутренних сигналов.
- Требование реализовать схему в монотонном однородном базисе, например только на элементах И-НЕ. Заданный интерфейс изменять нельзя. Это означает, что добавлять новые внутренние события перед входными запрещено. В базисе И-НЕ каждая синхронизация происходит только по событиям. Следствием этого является то, что в автономном поведении каждая последовательная ветвь должна начинаться и заканчиваться . Запрет на добавление новых событий перед входными (для не автономных поведений) может привести к нарушению баланса и . Если больше, чем , то схема не реализуема в базисе И-НЕ. Примером может служить реализация С-элемента.
- Использование элементов с полным квитированием (CA) , . Пусть входные событие и инициируют альтернативные ветви 1 и 2 соответственно. Если в ветви 2 есть событие , то схема не реализуема на CA-элементах .














Основные факты и результаты
- Асинхронные схемы могут рассматриваться как обобщение кольцевого осциллятора. То есть если выходы схемы соединить через модель внешней среды со входами, схема начнёт осциллировать.
- Разделитель (spacer) присутствует только в двухфазных самосинхронныx (СС) кодах. Однофазный СС код — это код с прямыми переходами. Других однофазных СС кодов не существует.
- Реализация логических функций. До сих пор наилучшим универсальным подходом является перекрестная реализация . Любая логическая функция от двух и более переменных обладает функциональными состязаниями, с которыми в принципе невозможно бороться. Однако, на сравнимых наборах монотонная (unate) функция свободна от функциональных состязаний. Поэтому удваиваем число входных переменных и заменяем инверсию переменной независимой переменной. Для того чтобы входные наборы стали сравнимыми нужна двухфазная дисциплина, в которой каждый рабочий набор перемежается спейсером (разделителем, состоящим либо из всех нулей, либо из всех единиц). Поскольку спейсер сравним с любым рабочим набором, получаем, что в двухфазной последовательности входов все соседние наборы являются сравнимыми, что необходимо для отсутствия функциональных состязаний. Остаются логические состязания (атрибут реализации). В этом случае помогает перекрестная реализация. Добавляется второй канал реализации, который реализует инверсную функцию (первый канал реализует саму функцию). Причем реализация этого канала должна быть двойственной реализации основного канала. При такой реализации все чистые инверторы в каждом канале заменяются перекрестными связями, так как каждому выходу элемента некоторого яруса соответствует выход элемента в том же ярусе инверсного канала. Эти два выхода образуют пару парафазного кода, что существенно облегчает построение индикатора для логики. В случае использования двухфазной дисциплины со спейсером парафазная реализация в КМОП-технологии не приводит к увеличению числа транзисторов по сравнению с тактируемой однофазной логикой. Это связано с тем, что КМОП-схемы в случае однофазной реализации coдержат прямой и инверсный каналы. Анализ избыточности самосинхронизирующихся кодов позволяет предположить, что для синхронной комбинационной схемы с входами и выходами должна существовать асинхронная схема с входами и выходами. Эта оценка соответствует гипотетической реализации с минимальными дополнительным оборудованием, то есть на практике нижний предел недостижим.
- Реализация индикаторов. Каналы индикации моментов окончания переходных процессов строятся на основе Г-триггеров. Поскольку Г-триггер содержит компоненту И, число его входов ограничено. Таким образом, нужно использовать либо пирамиды из Г-триггеров, либо системы параллельного сжатия, что приводит к затратам оборудования и увеличению задержки в схеме индикации, что может резко снизить быстродействие за счет работы по реальным задержкам. Использование свойства двусторонней проводимости МОП-транзистора позволяет построить схему двухкаскадного индикатора с практически неограниченным числом входов и расходом оборудования 4 транзистора на индицируемый вход .
- Некоторые самосинхронные устройства могут быть реализованы с пренебрежимо малым увеличением оборудования по сравнению с синхронной реализацией. Например счетчики (1974) и память (1986) .
- Схемы не зависящие от задержки (DI , foam-rubber wrapper ), которые состоят из элементов с одним выходом могут содержать только инверторы и С-элементы, что не позволяет строить практические схемы достаточно гибко . Невозможно построить полностью независимые от задержек Г-триггер, RS-триггер, Т-триггер .
- Любая дистрибутивная схема может быть корректно реализована на двухвходовых элементах И-НЕ (ИЛИ-НЕ) с нагрузочной способностью не больше двух. Любая полумодулярная схема может быть корректно реализована только при совместном использовании этих элементов или при использовании трехвходовых элементов И-ИЛИ-НЕ. Вопрос о корректной реализации полумодулярных схем только на элементах И-НЕ (ИЛИ-НЕ) остается открытым . На практике однако, минимальный базис не имеет особого смысла ввиду высокой сложности получающихся схем. С ростом значений коэффициентов разветвления и с увеличением функциональных возможностей схемы становятся компактней. В современной КМОП технологии целесообразно использовать элементы сложность которых не превышает 4И-4ИЛИ-НЕ. Не существует полумодулярной схемы из элементов И-НЕ, не чувствительной к задержкам хотя бы в двух ветвях провода, подключенного к выходу элемента, для которого состояния этой схемы живые . Если провод разветвляется, то это функция ИЛИ, поэтому где-то нужно индицировать сигналы в ветвящихся проводах (ИЛИ-обусловленность). Всё вышесказанное справедливо только для парафазной реализации, частным случаем которой является реализация C-элемента только на элементах И-НЕ. Вопрос о реализации однофазных дистрибутивных схем на только элементах И-НЕ остается открытым. Однако, в случае однофазного С-элемента нужны элементы обоих типов. Действительно, чтобы реализовать сильную причинность по нарастающим фронтам, нужен элемент И-НЕ, а по спадающим — ИЛИ-НЕ.
- По одному и тому же проводу запрос можно передавать напряжением, а подтверждение — током. В этом случае для индикации моментов окончания переходных процессов необходимо использовать датчики потребляемого тока КМОП элементов. Однако такие датчики сложны в реализации, а их быстродействие недостаточно. Таким образом, идея комбинированной индикации на практике не ведет к упрощению оборудования. Примером удачного использования этой идеи является метод самосинхронной передачи данных, где каждый бит передается по одному проводу . Для параллельной передачи разрядного двоичного кода этому методу требуется лишь проводов, а его производительность не хуже, чем при передачи данных по двум проводам.
- Индикаторы завершения переходных процессов могут быть построены на основе пороговых схем с несколькими выходами .






Библиография
- ↑ (недоступная ссылка)
- ↑ (недоступная ссылка) ( (недоступная ссылка) )
- ↑
- ↑
- Дата обращения: 16 сентября 2015. 5 ноября 2015 года.
- Дата обращения: 14 июля 2015. 14 июля 2015 года.
- Дата обращения: 5 марта 2016. 1 августа 2017 года.
- Дата обращения: 23 июля 2015. 24 июля 2015 года.
- Дата обращения: 26 июля 2017. 31 июля 2017 года.
- Дата обращения: 15 ноября 2019. 15 ноября 2019 года.
- Дата обращения: 27 февраля 2016. 6 марта 2016 года.
- Дата обращения: 27 февраля 2016. 12 июля 2012 года.
- ↑ Дата обращения: 1 марта 2016. 8 августа 2017 года.
- ↑
- Дата обращения: 31 июля 2017. 31 июля 2017 года.
- Дата обращения: 3 марта 2016. 10 марта 2016 года.
- P. Y. K. Cheung. This Asynchronous World 87—95 (2016). Дата обращения: 19 февраля 2017. 20 февраля 2017 года.
- . Дата обращения: 13 июня 2016. 17 июня 2016 года.
- Дата обращения: 17 апреля 2019. 17 апреля 2019 года.
- Дата обращения: 17 апреля 2019. 17 апреля 2019 года.
- A. Kushnerov, M. Medina and A. Yakovlev, « от 18 июня 2023 на Wayback Machine ,» in IEEE Int. Symposium on Asynchronous Circuits and Systems, 2021.
- Дата обращения: 29 июля 2019. 29 июля 2019 года.
- Дата обращения: 4 августа 2019. 17 июня 2018 года.
- Дата обращения: 6 августа 2019. 6 августа 2019 года.
- . Дата обращения: 8 апреля 2019. 8 апреля 2019 года.
- Tранзисторная схема двух- и трехвходового Г-триггеров известна по крайней мере с 1969 от 30 марта 2019 на Wayback Machine
- ↑
- ↑ от 4 марта 2016 на Wayback Machine (R. E. Miller, "Theory of speed-independent circuits, " Ch. 10 in Switching Theory. Vol. 2: Sequential circuits and machines. Wiley, 1965.)
- Дата обращения: 5 февраля 2016. 21 января 2022 года.
- от 11 июня 2018 на Wayback Machine ( от 22 июля 2015 на Wayback Machine )
- Дата обращения: 23 июля 2015. 7 августа 2015 года.
- Дата обращения: 17 июля 2015. 22 июля 2015 года.
- Дата обращения: 30 января 2016. 12 апреля 2012 года.
- Дата обращения: 27 июля 2015. 10 сентября 2016 года.
- Дата обращения: 13 сентября 2015. 28 сентября 2015 года.
- Дата обращения: 27 июля 2015. 27 сентября 2015 года.
- Дата обращения: 29 июля 2015. 27 сентября 2015 года.
- Дата обращения: 28 января 2016. 4 февраля 2016 года.
- Дата обращения: 28 января 2016. Архивировано из 3 февраля 2016 года.
- ↑
- Дата обращения: 16 ноября 2015. 17 ноября 2015 года.
- Дата обращения: 16 ноября 2015. 17 ноября 2015 года.
- Дата обращения: 3 октября 2017. 31 января 2018 года.
- ↑ Дата обращения: 29 сентября 2015. 30 сентября 2015 года.
- H. Lawson, An Asynchronous Approach to Microprogramming. Chapter 3 in Microprogramming and Firmware Engineering Methods. (ed. S. Habib), Wiley, 1988.
- . Дата обращения: 27 июля 2015. 20 июля 2015 года.
- 17 июля 2015 года.
- С. Т. Хвощ, Н. Н. Варлинский и Е. А. Попов, Микропроцессоры и микроЭВМ в системах автоматического управления. Справочник. Л. Машиностроение, 1987, 638 с.
- 22 июля 2015 года.
- Дата обращения: 23 июля 2017. 31 января 2018 года.
- . Дата обращения: 20 июля 2015. 9 августа 2017 года.
- ↑ Дата обращения: 20 апреля 2019. 17 июня 2018 года.
- ↑ от 5 марта 2016 на Wayback Machine ( от 24 июля 2015 на Wayback Machine
- Дата обращения: 2 октября 2015. 3 октября 2015 года.
- Дата обращения: 3 октября 2015. 4 октября 2015 года.
- ↑ Дата обращения: 16 сентября 2015. 29 сентября 2015 года.
- ↑ от 5 октября 2015 на Wayback Machine также ( )
- Дата обращения: 17 сентября 2015. Архивировано из 29 сентября 2015 года.
- 29 сентября 2015 года.
- Дата обращения: 21 сентября 2015. Архивировано из 29 сентября 2015 года.
- . Дата обращения: 7 августа 2016. 24 августа 2017 года.
- Дата обращения: 15 марта 2018. 14 октября 2017 года.
- (V. A. Druzhinin and S. A. Yuditskii, "Construction of well-formed Petri nets from standard subnets, " Automation and Remote Control, vol. 53, no. 12, 1992, pp.1922-1927)
- Дата обращения: 22 сентября 2015. 3 октября 2015 года.
- В. И. Варшавский, Л. Я. Розенблюм, А. Р. Таубин и Б. С. Цирлин, "Ячейка асинхронного распределителя, " Aвторское свидетельство от 21 июня 2023 на Wayback Machine , 30.04.1982.
- В. И. Варшавский и Б. С. Цирлин, "Асинхронный распределитель, " Aвторское свидетельство от 21 июня 2023 на Wayback Machine , 07.06.1983.
- В. И. Варшавский, В. Б. Мараховский, Л. Я. Розенблюм, А. Р. Таубин и Б. С. Цирлин, "Асинхронный распределитель, " Aвторское свидетельство от 21 июня 2023 на Wayback Machine , 30.06.1983.
- В. И. Варшавский, М. А. Кишиневский, В. Б. Мараховский, Л. Я. Розенблюм, А. Р. Таубин и Б. С. Цирлин, "Асинхронный распределитель, " Aвторское свидетельство от 21 июня 2023 на Wayback Machine , 30.12.1983.
- А. И. Бухштаб, В. И. Варшавский, В. Б. Мараховский, В. А. Песчанский, Л. Я. Розенблюм, Н. А. Стародубцев и Б. С. Цирлин, "Ячейка асинхронного распределителя, " Авторское свидетельство от 21 июня 2023 на Wayback Machine , 29.02.1980.
- Дата обращения: 21 сентября 2015. 29 сентября 2015 года.
- 2 марта 2016 года.
- Дата обращения: 6 октября 2015. 7 октября 2015 года.
- Дата обращения: 15 сентября 2015. 27 сентября 2015 года.
- Дата обращения: 3 октября 2017. 5 июня 2018 года.
- Дата обращения: 1 августа 2019. 1 августа 2019 года.
- Дата обращения: 10 августа 2019. 10 августа 2019 года.
- Дата обращения: 1 июля 2019. 1 июля 2019 года.
- Дата обращения: 1 августа 2019. 1 августа 2019 года.
- Дата обращения: 20 марта 2019. 20 марта 2019 года.
- ↑ Дата обращения: 26 июня 2019. 26 июня 2019 года.
- Дата обращения: 26 июня 2019. 26 июня 2019 года.
- Дата обращения: 30 июня 2019. 30 июня 2019 года.
- ↑
- Дата обращения: 12 апреля 2019. 12 апреля 2019 года.
- Дата обращения: 20 июля 2017. 31 января 2018 года.
- . Дата обращения: 28 июля 2019. 28 июля 2019 года.
- Дата обращения: 25 марта 2019. 3 апреля 2019 года.
- Дата обращения: 2 ноября 2019. 2 ноября 2019 года.
- Дата обращения: 10 июля 2019. 10 июля 2019 года.
- . Дата обращения: 5 июня 2019. Архивировано из 5 июня 2019 года.
- Дата обращения: 7 апреля 2019. 7 апреля 2019 года.
- ↑ A. J. Martin, "The limitations to delay-insensitivity in asynchronous circuits, " Advanced Research in VLSI, 1990, pp. 263—278.
- K. van Berkel, F. Huberts, A. Peeters, "Stretching quasi delay insensitivity by means of extended isochronic forks, " Asynchronous Design Methodologies, 1995, pp. 99-106.
- Дата обращения: 3 октября 2015. 4 октября 2015 года.
- Дата обращения: 1 октября 2015. 2 октября 2015 года.
- ↑ Дата обращения: 15 ноября 2015. 17 ноября 2015 года.
- ( от 22 июля 2015 на Wayback Machine )
- Дата обращения: 7 октября 2009. 9 июня 2007 года.
- Дата обращения: 16 сентября 2015. Архивировано из 6 октября 2016 года.
- Дата обращения: 15 июля 2015. 4 марта 2016 года.
- Дата обращения: 3 октября 2017. 31 января 2018 года.
- Дата обращения: 4 августа 2015. 3 декабря 2015 года.
- 9 октября 2006 года.
- А. И. Бухштаб, В. И. Варшавский, В. Б. Мараховский и др., "Ячейка памяти для буферного регистра, " Авторское свидетельство от 19 июня 2023 на Wayback Machine , 05.05.1979.
- В. И. Варшавский, А. Ю. Кондратьев, Н. М. Кравченко и Б. С. Цирлин, "Асинхронный распределитель, " Авторское свидетельство от 20 июня 2023 на Wayback Machine , 07.10.1990.
- Дата обращения: 19 апреля 2019. 29 июля 2021 года.
- Дата обращения: 2 сентября 2015. 23 октября 2003 года.
- T.-A. Chu, C. K. C. Leung, and T. S. Wanuga, "A design methodology for concurrent VLSI systems, " IEEE Int. Conference on Computer Design (ICCD) 1985, pp. 407—410.
- Дата обращения: 10 марта 2016. 11 марта 2016 года.
- ↑ от 31 января 2018 на Wayback Machine (V. I. Varshavsky, M. A. Kishinevsky, A. Yu. Kondratyev, L. Ya. Rosenblum and A. R. Taubin, "Models for specification and analysis of processes in asynchronous circuits, " Soviet Journal of Computer and Systems Sciences, vol. 26, 1989, pp. 61-76.)
- Дата обращения: 18 сентября 2015. 3 февраля 2016 года.
- Дата обращения: 27 января 2016. 19 апреля 2016 года.
- Дата обращения: 11 мая 2019. 29 августа 2017 года.
- Дата обращения: 22 сентября 2015. 6 февраля 2016 года.
- G. E. Sobelman and D. Parker, « от 18 июня 2023 на Wayback Machine ». Patent US5986466, 16 Nov. 1999.
- A. Kondratyev, « от 18 июня 2023 на Wayback Machine ,» Patent US6526542, Feb. 25, 2003.
- A. Kushnerov and S. Bystrov, « от 18 июня 2023 на Wayback Machine ,» Preprint, 2022, DOI:10.13140/RG.2.2.31525.47847
- А. Н. Фойда, « от 18 июня 2023 на Wayback Machine ,» Авторское свидетельство SU643974, 25.01.1979.
- G. Gopalakrishnan, « от 18 июня 2023 на Wayback Machine ,» Report UUCS-93-015, University of Utah, pp. 1-16, 1993.
- А. И. Бухштаб, В. И. Варшавский, В. Б. Мараховский и др., « от 18 июня 2023 на Wayback Machine ,» Авторское свидетельство SU561182, 05.06.1977.]
- A. Kushnerov and S. Bystrov, « от 18 июня 2023 на Wayback Machine ,» Modeling and Analysis of Information Systems, vol. 30, no. 2, pp. 170—186, 2023. DOI: 10.18255/1818-1015-2023-2-170-186
- R. O. Winder, « от 18 июня 2023 на Wayback Machine ,» Patent US3403267, Sep. 24, 1968.
- Дата обращения: 26 июля 2019. 26 июля 2019 года.
- В. Н. Тазиян, « от 18 июня 2023 на Wayback Machine ,» Авторское свидетельство SU372697, 01.03.1973.
- С. О. Мкртчян, « от 26 июля 2019 на Wayback Machine ,» Авторское свидетельство SU421111 25.03.1974.
- Дата обращения: 15 мая 2022. 15 мая 2022 года.
- Дата обращения: 20 июля 2017. 31 января 2018 года.
- ↑ Дата обращения: 22 августа 2015. 4 марта 2016 года.
- Дата обращения: 23 октября 2022. 23 октября 2022 года.
- Дата обращения: 28 июля 2017. 28 июля 2017 года.
- J. T. Udding, Classification and Composition of Delay-Insensitive Circuits, PhD thesis, Eindhoven University of Technology, 1984.
- C.E. Molnar, T.P. Fang, and F.U. Rosenberger, "Synthesis of delay-insensitive modules, " Chapel Hill Conference on VLSI, 1985.
- Дата обращения: 27 января 2016. 1 февраля 2016 года.
- от 31 января 2018 на Wayback Machine (B. S. Tsirlin, "Minimal Basis for Realization of Sequential Circuits, " Soviet Journal of Computer and Systems Sciences, vol. 23, 1985, pp. 26-31.)
- В. И. Варшавский, М. А. Кишиневский, В. Б. Мараховский, Л. Я. Розенблюм, "Функциональная полнота в классе полумодулярных схем, " Известия АН СССР, Техническая кибернетика, № 3, 1985, стр. 103—114. ( от 31 января 2018 на Wayback Machine )
- от 29 июля 2017 на Wayback Machine (B. S. Tsirlin, "A survey of equivalent problems of realizing circuits in the AND-NOT basis that are speed-independent, " Soviet Journal of Computer and Systems Sciences, vol. 24, 1986, pp. 58-69.)
- Дата обращения: 3 февраля 2017. 31 января 2018 года.
Дополнительная литература
Отчёты и книги
- (недоступная ссылка)
- (недоступная ссылка)
- В. И. Варшавский, М. А. Кишиневский, В. Б. Мараховский и др. Автоматное управление асинхронными процессами в ЭВМ и дискретных системах. М.: Наука, 1986. Translated to English as Self-Timed Control of Concurrent Processes: The Design of Aperiodic Logical Circuits in Computers and Discrete Systems.
- K. van Berkel, Handshake Circuits: An Asynchronous Architecture for VLSI Programming. Cambridge, 225 p.
- M. Kishinevsky, L. Lavagno and P. Vanbekbergen, The Systematic Design of Asynchronous Circuits. Tutorial, Int. Conference on Computer-Aided Design (ICCAD) 1995, 219p.
- Translated to Russian as
- J. Cortadella, M. Kishinevsky, A. Kondratyev, L. Lavagno and A. Yakovlev, Logic Synthesis for Asynchronous Controllers and Interfaces. Springer, 2002, 272 p.
- K. M. Fant, Logically Determined Design: Clockless System Design with NULL Convention Logic. Wiley, 2005, 292 p.
- P. A. Beerel, R. O. Ozdag, M. Ferretti, A Designer’s Guide to Asynchronous VLSI. Cambridge, 2010, 339 p.
Статьи
- Н. А. Стародубцев, "Асинхронные процессы и антитонные управляющие схемы. II. Основные свойства, " Изв. АН СССР. Техническая кибернетика, 1985, № 4, стр.115-122.
- Translated to Russian as
- D. Lloyd and R. Illman, "Scan insertion and ATPG for C-gate based asynchronous designs, " Synopsys User Group (SNUG), 2014.
Патенты
- Б. С. Цирлин, "Асинхронный распределитель, " Авторское свидетельство , 15.02.1983.
- Б. С. Цирлин, "Асинхронный распределитель, " Авторское свидетельство , 15.05.1983.
- Б. С. Цирлин, "Асинхронный распределитель, " Авторское свидетельство , 07.08.1986.
- В. И. Варшавский, А. Ю. Кондратьев, Н. М. Кравченко и Б. С. Цирлин, " , " Авторское свидетельство SU1458968, 15.02.1989.
- В. И. Варшавский, А. Ю. Кондратьев, Н. М. Кравченко и Б. С. Цирлин, " , " Авторское свидетельство SU1465997, 15.03.1989.
- С. Г. Арутюнян, "Асинхронный распределитель, " Авторское свидетельство , 07.10.1990.
- В. И. Варшавский, А. Ю. Кондратьев и В. А. Романовский и Б. С. Цирлин, "Асинхронный распределитель, " Авторское свидетельство , 23.01.1991.
- В. И. Варшавский, А. Ю. Кондратьев, В. А. Романовский и Б. С. Цирлин, "Асинхронный распределитель, " Авторское свидетельство , 15.09.1991.
- В. И. Варшавский, В. И. Красюк, Н. М. Кравченко и В. Б. Мараховский, "Реверсивный регистр сдвига, " Авторское свидетельство , 23.05.1993.
САПР асинхронных схем
- 2021-05-31
- 1













