Interested Article - Синтаксический анализ
- 2020-10-15
- 1
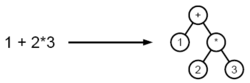
Синтакси́ческий ана́лиз (или разбор , жарг. па́рсинг ← англ. parsing ) в лингвистике и информатике — процесс сопоставления линейной последовательности лексем (слов, токенов) естественного или формального языка с его формальной грамматикой . Результатом обычно является дерево разбора (синтаксическое дерево). Обычно применяется совместно с лексическим анализом .
Синтаксический анализатор ( жарг. па́рсер ← англ. parser ) — это программа или часть программы, выполняющая синтаксический анализ.

В ходе синтаксического анализа исходный текст преобразуется в структуру данных , обычно — в дерево, которое отражает синтаксическую структуру входной последовательности и хорошо подходит для дальнейшей обработки.
Как правило, результатом синтаксического анализа является синтаксическое строение предложения, представленное либо в виде дерева зависимостей , либо в виде дерева составляющих , либо в виде некоторого сочетания первого и второго способов представления.
Область применения
Всё что угодно, имеющее « синтаксис », поддается автоматическому анализу.
- Языки программирования — разбор исходного кода языков программирования, в процессе трансляции ( компиляции или интерпретации );
- Структурированные данные — данные, языки их описания, оформления и т. д. Например, XML , HTML , CSS , JSON , ini-файлы, специализированные конфигурационные файлы и т. п.;
- Построение индекса в поисковой системе ;
- SQL -запросы ( DSL -язык);
- Математические выражения;
- Регулярные выражения (которые, в свою очередь, могут использоваться для автоматизации лексического анализа );
- Формальные грамматики ;
- Лингвистика — естественные языки. Например, машинный перевод и другие генераторы текстов .
- Извлечение данных веб-страниц — веб-скрейпинг , является частным случаем парсинга .
Типы алгоритмов
- Нисходящий парсер ( англ. top-down parser ) — продукции грамматики раскрываются, начиная со стартового символа, до получения требуемой последовательности токенов .
- ( англ. bottom-up parser ) — продукции восстанавливаются из правых частей, начиная с токенов и заканчивая стартовым символом.
Восстановление после ошибок
Простейший способ реагирования на некорректную входную цепочку лексем — завершить синтаксический анализ и вывести сообщение об ошибке. Однако часто оказывается полезным найти за одну попытку синтаксического анализа как можно больше ошибок. Именно так ведут себя трансляторы большинства распространённых языков программирования.
Таким образом, перед обработчиком ошибок синтаксического анализатора стоят следующие задачи:
- он должен ясно и точно сообщать о наличии ошибок;
- он должен обеспечивать быстрое восстановление после ошибки, чтобы продолжать поиск других ошибок;
- он не должен существенно замедлять обработку корректной входной цепочки.
Ниже описаны наиболее известные стратегии восстановления после ошибок.
Восстановление в режиме паники
При обнаружении ошибки синтаксический анализатор пропускает входные лексемы по одной, пока не будет найдена одна из специально определённого множества синхронизирующих лексем . Обычно такими лексемами являются разделители, например: ; , ) или } . Набор синхронизирующих лексем должен определять разработчик анализируемого языка. При такой стратегии восстановления может оказаться, что значительное количество символов будут пропущены без проверки на наличие дополнительных ошибок. Данная стратегия восстановления наиболее проста в реализации.
Восстановление на уровне фразы
Иногда при обнаружении ошибки синтаксический анализатор может выполнить локальную коррекцию входного потока так, чтобы это позволило ему продолжать работу. Например, перед точкой с запятой, отделяющей различные операторы в языке программирования, синтаксический анализатор может закрыть все ещё не закрытые круглые скобки. Это более сложный в проектировании и реализации способ, однако в некоторых ситуациях, он может работать значительно лучше восстановления в режиме паники. Естественно, данная стратегия бессильна, если настоящая ошибка произошла до точки обнаружения ошибки синтаксическим анализатором.
Продукции ошибок
Знание наиболее распространённых ошибок позволяет расширить грамматику языка продукциями, порождающими ошибочные конструкции. При срабатывании таких продукций регистрируется ошибка, но синтаксический анализатор продолжает работать в обычном режиме.
Средства разработки анализаторов
Отдельные этапы разработки и построения трансляторов могут быть автоматизированы и выполнены компьютером.
Вот некоторые из наиболее известных средств разработки анализаторов :
- ANTLR — генератор парсеров
- Bison — генератор парсеров
- Coco/R — генератор сканера и парсера
- — парсер
- JavaCC — генератор парсеров для языка Java
- — генератор парсеров
- Lex — генератор сканеров
- Ragel — генератор встраиваемых парсеров
- — генератор парсеров
- SYNTAX
- UltraGram
- VivaCore
- Yacc — генератор парсеров
См. также .
См. также
Примечания
- Тим Джонс М. (22 мая 2014). Дата обращения: 13 декабря 2019. 13 декабря 2019 года.
- Ela Kumar. Natural Language Processing. — I. K. International Pvt Ltd, 2011. — P. 100. — ISBN 978-93-80578-77-4 .
Литература
- А. Ахо , Дж. Ульман. Теория синтаксического анализа, перевода и компиляции. Т. 1. Пер. с англ. В. Н. Агафонова под ред. В. М. Курочкина . М.: Мир, 1978. 614 с.
- А. Ахо, Дж. Ульман. Теория синтаксического анализа, перевода и компиляции. Т. 2. Пер. с англ. А. Н. Бирюкова и В. А. Серебрякова под ред. В. М. Курочкина. М.: Мир, 1978. 487 с.
- Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман. Компиляторы: принципы, технологии и инструментарий = Compilers: Principles, Techniques, and Tools. — 2-е изд. — М. : , 2008. — ISBN 978-5-8459-1349-4 .
- Робин Хантер. Основные концепции компиляторов = The Essence of Compilers. — М. : , 2002. — С. 256. — ISBN 5-8459-0360-2 .
Ссылки
- (рус.)
|
|
|
|---|
|
|
|
|---|---|
|
Нисходящий
синтаксический анализ |
|
| Прочие | |
| Сопутствующие темы | |
- 2020-10-15
- 1






