:
Насколько быстр может быть алгоритм умножения матриц?
Поскольку
умножение матриц
является центральной операцией во многих
численных алгоритмах
, много усилий было вложено в повышение эффективности
алгоритма умножения матриц
. Приложения алгоритма умножения матриц в вычислительных задачах найдены во многих областях, включая
и
, а также во вроде бы не имеющих отношение к матрицам задачах, таких как подсчёт путей через
граф
. Было разработано много различных алгоритмов для умножения матриц на оборудовании различного типа, включая
параллельные
и
распределённые
системы, где вычисления распределены на несколько процессоров (и, может быть, по сети).
Прямое использование математического определения умножения матриц даёт алгоритм, который
работает за время
порядка
операций
поля
для умножения двух
матриц над этим полем (или
в
нотации «O» большое
). Улучшенные асимптотические границы по времени были известны с момента появления
алгоритма Штрассена
в 1960-х годах, но оптимальное время остаётся неизвестным (то есть, неизвестна
сложность задачи
). К концу 2020 года алгоритм умножения матриц с лучшей асимптотической сложностью, работающий за время
, был дан Джозефом Алманом и
, однако этот алгоритм
галактического масштаба
, то есть только для данных галактического размера, поскольку содержит огромные константы и не может быть реализован на практике.
Отсюда можно построить простой алгоритм путём организации циклов по индексу
i
от 1 до
n
и
j
от 1 до
p
, и осуществляя вычисления по вышеприведённой формуле с помощью вложенных циклов:
Вход: матрицы
A
и
B
Пусть
C
будет новой матрицей нужного размера
Для
i
от 1 до
n
:
Для
j
от 1 до
p
:
Положим
Для
k
от 1 до
m
:
Положим
Положим
Возвращаем
C
Этот алгоритм работает
за время
(в
асимптотических обозначениях
)
. Обычно для упрощения
анализа алгоритма
предполагается, что входными матрицами являются квадратные матрицы размера
, и в этом случае время работы составляет
, то есть время зависит кубически от размера матриц
.
Поведение кэша
Иллюстрация построчного и постолбцового порядка
Три цикла при итеративном умножении матриц можно произвольным образом переставлять друг с другом без влияния на правильность алгоритма или асимптотическое время работы. Однако, порядок циклов может влиять на практические характеристики
и на алгоритм использования
кэша
.
Какой порядок вычисления лучше, зависит от того, как хранятся входные матрицы — в
, постолбцовом порядке, или в смешении этих порядков.
В частности, в идеальном случае
полностью ассоциативного кэша
, состоящего из
M
байт и
b
байт на строку кэша (то есть,
M
/
b
строк кэша), вышеприведённый алгоритм является подоптимальным для
A
и
B
, хранящихся построчно. Если
, любая итерация внутреннего цикла (одновременный проход по строкам
A
и столбцам
B
) приводит к промахам кэша при выборке элемента матрицы
B
. Это означает, что при работе алгоритма будет
промахов кэша в
. К 2010 году для больших матриц скорость доступа к памяти являлась доминирующим фактором, определяющим время работы алгоритма, а не скорость процессора
.
Оптимальным вариантом итерационного алгоритма для матриц
A
и
B
при построчном хранении является версия с
, где матрицы в неявном виде разбиты на квадратные части размера
:
Вход: матрицы
A
и
B
Пусть
C
будет новой матрицей нужного размера
Выбираем часть размера
Для
I
от 1 до
n
для части
T
:
Для
J
от 1 до
p
для части
T
:
Для
K
от 1 до
m
для части
T
:
Умножаем
и
, помещая результат в
, то есть:
Для
i
от
I
до
:
Для
j
от
J
до
:
Положим
sum = 0
Для
k
от
K
до
:
Положим
Положим
Возвращаем
C
В случае идеального кэша алгоритм приводит только к
промахам. Делитель
составляет несколько порядков величины для современных машин, так что вычисления доминируют во времени работы, а не промахи кэша
.
что работает для всех квадратных матриц с размерностями, равными степеням двойки, то есть
для некоторого
n
. Произведение матриц тогда равно
что составляет восемь умножений пар подматриц с последующим шагом сложения. Алгоритм разделяй-и-властвуй вычисляет элементы
рекурсивно
с помощью
скалярного произведения
как в базовом случае.
Сложность этого алгоритма как функция от
n
задаётся рекурсией
;
,
принимающей во внимание восемь рекурсивных вызовов на матрицах размера
n
/2
и величину
для суммирования четырёх пар полученных матриц. Применяя
основную теорему о рекуррентных соотношениях
, получим, что эта рекурсия имеет решение
, ту же самую сложность, что и для итеративного алгоритма
.
Неквадратные матрицы
Вариант этого алгоритма, который работает для матриц произвольного размера и на практике быстрее
, разбивает матрицы на две, а не на четыре подматрицы, что продемонстрировано ниже
.
Разбиение матрицы теперь означает разделение её на две одинаковые или близкие к одинаковым части, если размер нечётен.
Вход: матрица
A
размера
и матрица
B
размера
.
Базовый случай: если
ниже некоторого порога, используем версию с
размоткой
итеративного алгоритма.
Случай рекурсии:
Если
, разбиваем матрицу
A
горизонтально:
В противном случае, если
, разбиваем матрицу
B
вертикально:
В противном случае
. Разбиваем
A
вертикально, а
B
горизонтально:
Поведение кэша
Количество промахов кэша рекрсивного умножения матриц та же самая, что и у версии aлгоритма
, но, в отличие от этого алгоритма, рекурсивный алгоритм
— не нужно никакого настоечного параметра для получения оптимального поведения кэша и он работает хорошо в
многозадачном
окружении, где размер кэша меняется динамически, поскольку другие процессы тоже используют кэш
.
(Простой итеративный алгоритм нечувствителен к кэшированию также, но на практике много медленнее, если матрицы не подогнаны под алгоритм.)
Число промахов кэша при этом алгоритме на машинах с
M
линиями идеального кэша, каждая из которых имеет размер в
b
байт, ограничена величиной
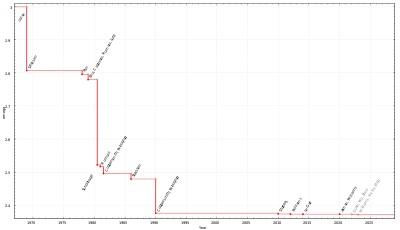
Подкубические алгоритмы
Улучшение оценки показателя
от времени вычислительной сложности умножения матриц
.
Существуют алгоритмы, обеспечивающие лучшее время работы, чем прямолинейные алгоритмы. Первым из таких алгоритмов был открыт
алгоритм Штрассена
, разработанный
Фолькером Штрассеном
в 1969 и часто упоминаемый как «быстрое умножение матриц». Алгоритм основан на способе перемножения двух
матриц, который требует лишь 7 умножений (вместо обычных 8), но требует выполнения дополнительных операций сложения и вычитания. Применение такого подхода рекурсивно даёт алгоритм с ценой по умножению
. Алгоритм Штрассена более сложен, а
вычислительная устойчивость
хуже, чем у наивного алгоритма
, но он быстрее в случае, когда
или где-то около этого
, и алгоритм включён в некоторые библиотеки, такие как
BLAS
. Алгоритм очень полезен для больших матриц над точными областями, такими как
конечные поля
, где вычислительная устойчивость не играет роли.
Открытым вопросом
теоретической информатики
является вопрос, насколько можно улучшить алгоритм Штрассена.
Показатель умножения матриц
— это наименьшее вещественно число, для которого произведение любых двух
матриц над полем может быть вычислено за
операций в поле. Текущая лучшая граница
равна 2,3728596 (алгоритм Джошуа Алманаи
. Этот алгоритм, подобно всем другим недавно разработанным алгоритмам в этом направлении исследований, является обобщением
алгоритма Копперсмита — Винограда
, который представили
Дон Копперсмит
и
в 1990 году, и который имеет асимптотическую сложность
. Концептуальная идея этих алгоритмов аналогична алгоритму Штрассена — способ разрабатывается для умножения двух
матриц за менее чем
умножений и эта техника применяется рекурсивно. Однако, константы, спрятанные в
нотации «O большое»
так велики, что эти алгоритмы целесообразно применять только для матриц, которые слишком велики, чтобы их можно было обрабатывать на существующих компьютерах
.
Поскольку любой алгоритм умножения двух
матриц должен обработать все
элемента, имеется асимптотическая нижняя граница числа операций
. Рэн Раз доказал нижнюю границу в
ограниченных коэффициентов арифметических цепей над вещественными или комплексными числами
.
Кон с соавторами переложил методы, такие как алгоритмы Штрассена и Копперсмита — Винограда в полностью другой контекст
теории групп
путём использования троек подмножеств конечных групп, которые удовлетворяют свойством дизъютктности, называемое
(СТП,
англ.
triple product property
, TPP). Они показали, что если семейства
абелевых групп
с симметричными группами образуют семейства троек со свойствами, аналогичными СТП, то существуют алгоритмы умножения матриц с фактически квадратичной сложностью
. Большинство исследователей верят, что это верно вообще
. Однако Алон, Шпилька и Хрис Уманс недавно показали, что некоторые из гипотез о быстром умножении матриц несовместимы с другой правдоподобной гипотезой,
.
можно осуществлять независимо друг от друга, как и сложение (хотя алгоритм тербует «объединения» умножений перед осуществлением сложения). Воплощая полный параллелизм задачи, получаем алгоритм, который можно выразить в
стиле fork–join
псевдокода
:
Процедура
multiply(
C
,
A
,
B
)
:
Базовый случай: если
, положим
(умножаем маленькие блочные матрицы).
В противном случае распределяем место для новой матрицы
T
размером
, затем:
Разбиваем
A
на
.
Разбиваем
B
на
.
Разбиваем
C
на
.
Разбиваем
T
на
.
Распараллеливаем (Fork = вилка, то есть ответвляем процесс):
Fork
.
Fork
.
Fork
.
Fork
.
Fork
.
Fork
.
Fork
.
Fork
.
Join
(Join = объединение, ждём завершения разветвлённых процессов).
add(
C
,
T
)
.
Уничтожаем
T
.
Процедура
добавляет
T
к
C
поэлементно:
Базовый случай: если
, полагаем
(или делаем короткий цикл, возможно, с размоткой).
В противном случае:
Разбиваем
C
на
C
11
,
C
12
,
C
21
,
C
22
.
Разбиваем
T
на
T
11
,
T
12
,
T
21
,
T
22
.
Распараллеливаем:
Fork
.
Fork
.
Fork
.
Fork
.
Join
.
Здесь,
fork
означает, что вычисления могут осуществляться параллельно к остальной части процедуры, а
join
означает ожидание завершения всех запущенных в параллельные ветки вычислений. Распараллеливание достигает своей цели лишь передачей
указателей
.
Этот алгоритм имеет
в
шагов, что определяет требуемое время для идеальной машины с неограниченным числом процессоров. Поэтому алгоритм имеет максимальное возможное
на любом реальном компьютере. Алгоритм не имеет практического значения ввиду неустранимой цены передачи данных во временную матрицу
T
и из неё, но более практичный вариант, не использующий временных матриц, достигает ускорения
.
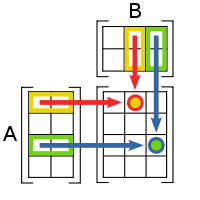
Блочное умножение матриц. В алгоритме 2D, каждый процессор занимается подматрицей матрицы
C
. В алгоритме 3D, каждая пара умножаемых подматриц из
A
и
B
распределяется своему процессору.
Алгоритмы без обмена данных и распределённые алгоритмы
В современных архитектурах с иерархической памятью цена загрузки и выгрузки входной матрицы стремится к определяющей роли при обработке. На одной машине это количество данных, переносимых между
RAM
и кэшем, в то время как для распределённой памяти машин с несколькими узлами это величина, переносимая между узлами. В любом случае это называется
полосой пропускания
. Наивный алгоритм, где используются три вложенных цикла, использует полосу
.
, известный также как
алгоритм 2D
, — это
, который превращает каждую входную матрицу в блочную матрицу, элементами которой являются подматрицы размера
, где
M
является размером быстрой памяти
. Затем используется наивный алгоритм над блоками матриц, вычисляющий произведение подматриц полностью в быстрой памяти. Это сокращает полосу частот канала связи до
, что асимптотически оптимально (для алгоритмов, выполняющих
операций)
.
В распределённых вычислениях с
p
процессорами, организованными в двухмерную решётку
, каждая из результирующих подматриц может быть назначена процессору и произведение может быть вычислено каждым процессором с передачей
слов, что асимптотически оптимально в предположении, что каждый узел сохраняет минимум
элементов
. Это может быть улучшено
алгоритмом 3D
, который распределяет процессоры в трёхмерную кубическую решётку, путём назначения каждого произведения двух входных подматриц одному процессору. Полученные подматрицы затем генерируются путём работы над каждой строкой
. Этот алгоритм передаёт
слов на процессор, что асимптотически оптимально
. Однако, это требует репликации каждого элемента входной матрицы
раз, а потому требует в
больше памяти, чем нужно для хранения входных данных. Этот алгоритм можно комбинировать с алгоримом Штрассена для дальнейшего уменьшения времени работы
. «2,5D» алгоритмы обеспечивают постоянный обмен между использованием памяти и полосой частот обмена
. В современных системах распределённых вычислений, таких как
MapReduce
, были разработаны специализированные алгоритмы умножения
.
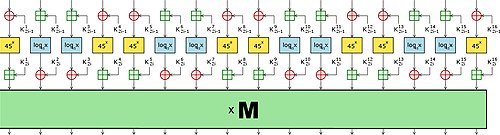
Алгоритмы для ячеистых топологий
Умножение матриц, выполненное в 2n-1 шагов для двух
матриц в ячеистой топологии с перекрёстными связями.
Имеется ряд алгоритмов вычисления умножения в
ячеистой топологии
. Для умножения двух
матриц на стандартной двумерной ячеистой топологии с помощью
2D можно выполнить умножение за 3
n
-2 шагов, хотя это число сокращается вдвое для повторных вычислений
. Стандартный массив неэффективен, поскольку данные из двух матриц не приходят одновременно и должны быть дополнены нулевыми значениями.
Результат даже быстрее на двухуровневой решётке с перекрёстными связями, где нужно только 2
n
-1 шагов
. Производительность улучшается далее для повторных вычислений, что приводит к 100% эффективности
. Решётка с перекрёстными связями может рассматриваться как специальный случай неплоской (то есть многослойной) вычислительной структуры
.
Kak, Subhash (2014) Efficiency of matrix multiplication on the cross-wired mesh array.
от 23 марта 2019 на
Wayback Machine
, с. 347–365.
Литература
Saman Amarasinghe, Charles Leiserson.
. — Massachusetts Institute of Technology, 2010.
Monica S. Lam, Edward E. Rothberg, Michael E. Wolf.
The Cache Performance and Optimizations of Blocked Algorithms
// Int'l Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS). — 1991.
Webb Miller.
Computational complexity and numerical stability // SIAM News. — 1975. —
Т. 4
,
вып. 2
. —
doi
:
.
William H. Press, Brian P. Flannery, Saul A. Teukolsky, William T. Vetterling.
Numerical Recipes: The Art of Scientific Computing. — 3rd. —
Cambridge University Press
, 2007. — С. 108. — (Numerical Recipes). —
ISBN 978-0-521-88068-8
.
Ran Raz.
// Proceedings of the Thirty-fourth Annual ACM Symposium on Theory of Computing. — 2002. —
ISBN 1581134959
. —
doi
:
.
Henry Cohn,
,
, Chris Umans.
Group-theoretic Algorithms for Matrix Multiplication
// Proceedings of the 46th Annual Symposium on Foundations of Computer Science. — Pittsburgh, PA,: IEEE Computer Society, 2005. — С. pp. 379–388.
Henry Cohn, Chris Umans.
A Group-theoretic Approach to Fast Matrix Multiplication
// Proceedings of the 44th Annual IEEE Symposium on Foundations of Computer Science. — Cambridge, MA,: IEEE Computer Society, 2003. — С. pp. 438–449.
Josh Alman, Virginia Vassilevska Williams.
A Refined Laser Method and Faster Matrix Multiplication
//
. — 2020.
Costas S. Iliopoulos.
// SIAM Journal on Computing. — 1989. —
Т. 18
,
вып. 4
. —
С. 658–669
. —
doi
:
.
Выдержка: «Алгоритм Копперсмита — Виноград непрактичен, поскольку содержит очень большие спрятанные константы в верхней границе числа требуемых умножений.
Sara Robinson.
// SIAM News. — 2005. —
Т. 38
,
вып. 9
.
Keith H. Randall.
. — Massachusetts Institute of Technology, 1998. — (Ph.D.).
Hong J. W., Kung H. T.
// STOC '81: Proceedings of the Thirteenth Annual ACM Symposium on Theory of Computing. — 1981.
Dror Irony, Sivan Toledo, Alexander Tiskin.
Communication lower bounds for distributed-memory matrix multiplication // J. Parallel Distrib. Comput.. — 2004. — Сентябрь (
т. 64
,
вып. 9
). —
С. 1017–1026
. —
doi
:
.
Agarwal R.C., Balle S. M., Gustavson F. G., Joshi M., Palkar P.
A three-dimensional approach to parallel matrix multiplication // IBM J. Res. Dev.. — 1995. — Сентябрь (
т. 39
,
вып. 5
). —
doi
:
.
Edgar Solomonik, James Demmel.
Communication-optimal parallel 2.5D matrix multiplication and LU factorization algorithms // Proceedings of the 17th International Conference on Parallel Processing. — 2011. —
Т. Part II
.
Bae S.E., Shinn T.-W., Takaoka T.
// Procedia Computer Science. — 2014. —
Т. 29
. —
doi
:
.
Томас Кормен, Чарльз Лейзерсон, Рональд Ривест, Клиффорд Штайн.
Алгоритм умножения матриц Штрассена
// Алгоритмы: построение и анализ. — Москва, Санко-Петербург, Киев: Вильямс, 2005. —
ISBN 5-8459-0857-4
.
Kak S.
A two-layered mesh array for matrix multiplication // Parallel Computing. — 1988. —
Т. 6
,
вып. 3
. —
doi
:
.
Kak S.
Multilayered array computing // Information Sciences. — 1988. —
Т. 45
,
вып. 3
. —
doi
:
.
Литература для дальнейшего чтения
Alfredo Buttari, Julien Langou, Jakub Kurzak, Jack Dongarra.
A class of parallel tiled linear algebra algorithms for multicore architectures // Parallel Computing. — 2009. —
Т. 35
. —
С. 38–53
. —
doi
:
. —
arXiv
:
.
Kazushige Goto, Robert A. van de Geijn.
Anatomy of high-performance matrix multiplication // ACM Transactions on Mathematical Software. — 2008. —
Т. 34
,
вып. 3
. —
С. 1–25
. —
doi
:
.
Field G. Van Zee, Robert A. van de Geijn.
BLIS: A Framework for Rapidly Instantiating BLAS Functionality // ACM Transactions on Mathematical Software. — 2015. —
Т. 41
,
вып. 3
. —
С. 1–33
. —
doi
:
.