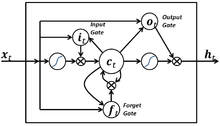
Простой LSTM-блок с тремя вентилями: входным, выходным и забывания. LSTM-блоки могут обладать большим числом вентилей.
Длинная цепь элементов краткосрочной памяти
(
англ.
Long short-term memory
;
LSTM
) — разновидность архитектуры
рекуррентных нейронных сетей
, предложенная в
1997 году
и
Юргеном Шмидхубером
. Как и большинство рекуррентных нейронных сетей, LSTM-сеть является
универсальной
в том смысле, что при достаточном числе элементов сети она может выполнить любое вычисление, на которое способен обычный компьютер, для чего необходима соответствующая
матрица
весов, которая может рассматриваться как программа. В отличие от традиционных рекуррентных нейронных сетей, LSTM-сеть хорошо приспособлена к обучению на задачах
классификации
, обработки и
прогнозирования
временных рядов
в случаях, когда важные события разделены временными лагами с неопределённой продолжительностью и границами. Относительная невосприимчивость к длительности временных разрывов даёт LSTM преимущество по отношению к альтернативным рекуррентным нейронным сетям,
скрытым марковским моделям
и другим методам обучения для последовательностей в различных сферах применения. Из множества достижений LSTM-сетей можно выделить наилучшие результаты в
распознавании несегментированного слитного рукописного текста
, и победу в
2009 году
на соревнованиях по распознаванию рукописного текста (
). LSTM-сети также используются в задачах
распознавания речи
, например LSTM-сеть была основным компонентом сети, которая в
2013 году
достигла рекордного порога ошибки в 17,7 % в задаче распознавания фонем на классическом корпусе естественной речи
. По состоянию на 2016 год ведущие технологические компании, включая
Google
,
Apple
,
Microsoft
и
Baidu
, используют LSTM-сети в качестве фундаментального компонента новых продуктов
.
Содержание
Архитектура
LSTM-сеть — это искусственная нейронная сеть, содержащая LSTM-модули вместо или в дополнение к другим сетевым модулям. LSTM-модуль — это рекуррентный модуль сети, способный запоминать значения как на короткие, так и на длинные промежутки времени. Ключом к данной возможности является то, что LSTM-модуль не использует функцию активации внутри своих рекуррентных компонентов. Таким образом, хранимое значение не размывается во времени, и
градиент
или штраф не исчезает при использовании
(
англ.
) при обучении искусственной нейронной сети.
LSTM-модули часто группируются в «блоки», содержащие различные LSTM-модули. Подобное устройство характерно для «глубоких» многослойных нейронных сетей и способствует выполнению параллельных вычислений с применением соответствующего оборудования. В формулах ниже каждая переменная, записанная строчным курсивом, обозначает вектор размерности равной числу LSTM-модулей в блоке.
LSTM-блоки содержат три или четыре «вентиля», которые используются для контроля потоков информации на входах и на выходах памяти данных блоков. Эти вентили реализованы в виде
логистической функции
для вычисления значения в диапазоне [0; 1]. Умножение на это значение используется для частичного допуска или запрещения потока информации внутрь и наружу памяти. Например, «входной вентиль» контролирует меру вхождения нового значения в память, а «вентиль забывания» контролирует меру сохранения значения в памяти. «Выходной вентиль» контролирует меру того, в какой степени значение, находящееся в памяти, используется при расчёте выходной функции активации для блока. (В некоторых реализациях входной вентиль и вентиль забывания воплощаются в виде единого вентиля. Идея заключается в том, что старое значение следует забывать тогда, когда появится новое значение, достойное запоминания).
Веса в LSTM-блоке (
и
) используются для задания направления оперирования вентилей. Эти веса определены для значений, которые подаются в блок (включая
и выход с предыдущего временного шага
) для каждого из вентилей. Таким образом, LSTM-блок определяет, как распоряжаться своей памятью как функцией этих значений, и тренировка весов позволяет LSTM-блоку выучить функцию, минимизирующую потери. LSTM-блоки обычно тренируют при помощи метода обратного распространения ошибки во времени.
Для минимизации общей ошибки LSTM на всём множестве тренировочных последовательностей, итеративный
градиентный спуск
такой как метод обратного распространения ошибки развёрнутый во времени может быть использован для изменения каждого из весов пропорционально его производной в зависимости от величины ошибки. Главной проблемой градиентного спуска для стандартных рекуррентных нейронных сетей является то, что градиенты ошибок уменьшаются с экспоненциальной скоростью по мере увеличения временной задержки между важными событиями, что было выявлено в
1991
. С LSTM-блоками, тем не менее, когда величины ошибки распространяются в обратном направлении от выходного слоя, ошибка оказывается заперта в памяти блока. Это называют «каруселью ошибок», которая непрерывно «скармливает» ошибку обратно каждому из вентилей, пока они не будут натренированы отбрасывать значение. Таким образом, регулярное обратное распространение ошибки эффективно для тренировки LSTM-блока для запоминания значений на очень длительные временные промежутки
[
источник не указан 239 дней
]
.
Klaus Greff; Rupesh Kumar Srivastava; Jan Koutník; Bas R. Steunebrink; Jürgen Schmidhuber (2015). "LSTM: A Search Space Odyssey".
arXiv
:
.
↑
;
Jürgen Schmidhuber
.
(англ.)
//
(англ.)
(
: journal. — 1997. —
Vol. 9
,
no. 8
. —
P. 1735—1780
. —
doi
:
. —
.
26 мая 2015 года.
(неопр.)
.
Дата обращения: 4 февраля 2017.
Архивировано 26 мая 2015 года.
A. Graves, M. Liwicki, S. Fernandez, R. Bertolami, H. Bunke, J. Schmidhuber. A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 5, 2009.
↑
Graves, Alex; Mohamed, Abdel-rahman; Hinton, Geoffrey.
Speech Recognition with Deep Recurrent Neural Networks
(англ.)
// Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on : journal. — 2013. —
P. 6645—6649
.
(англ.)
.
WIRED
.
Дата обращения: 16 июня 2016.
24 марта 2017 года.
(неопр.)
.
people.idsia.ch
.
Дата обращения: 16 июня 2016.
5 мая 2021 года.
Felix A. Gers; Jürgen Schmidhuber; Fred Cummins.
(англ.)
//
(англ.)
(
: journal. — 2000. —
Vol. 12
,
no. 10
. —
P. 2451—2471
. —
doi
:
.
7 апреля 2019 года.
↑
Gers, F. A.; Schmidhuber, J.
LSTM Recurrent Networks Learn Simple Context Free and Context Sensitive Languages
(англ.)
//
(англ.)
(
: journal. — 2001. —
Vol. 12
,
no. 6
. —
P. 1333—1340
. —
doi
:
.
↑
Gers, F.; Schraudolph, N.; Schmidhuber, J.
Learning precise timing with LSTM recurrent networks
(англ.)
//
Journal of Machine Learning Research
: journal. — 2002. —
Vol. 3
. —
P. 115—143
.
Xingjian Shi; Zhourong Chen; Hao Wang; Dit-Yan Yeung; Wai-kin Wong; Wang-chun Woo.
(англ.)
// Proceedings of the 28th International Conference on Neural Information Processing Systems : journal. — 2015. —
P. 802—810
.
9 ноября 2016 года.
S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institut f. Informatik, Technische Univ. Munich, 1991.
S. Hochreiter, Y. Bengio, P. Frasconi, and J. Schmidhuber. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies. In S. C. Kremer and J. F. Kolen, editors, A Field Guide to Dynamical Recurrent Neural Networks. IEEE Press, 2001.
Schmidhuber, J.; Wierstra, D.; Gagliolo, M.; Gomez, F.
Training Recurrent Networks by Evolino
(англ.)
//
(англ.)
(
. — 2007. —
Vol. 19
,
no. 3
. —
P. 757—779
. —
doi
:
.
H. Mayer, F. Gomez, D. Wierstra, I. Nagy, A. Knoll, and J. Schmidhuber. A System for Robotic Heart Surgery that Learns to Tie Knots Using Recurrent Neural Networks. Advanced Robotics, 22/13-14, pp. 1521—1537, 2008.
J. Schmidhuber and D. Wierstra and F. J. Gomez. Evolino: Hybrid Neuroevolution / Optimal Linear Search for Sequence Learning. Proceedings of the 19th International Joint Conference on Artificial Intelligence (IJCAI), Edinburgh, pp. 853—858, 2005.
Graves, A.; Schmidhuber, J.
Framewise phoneme classification with bidirectional LSTM and other neural network architectures
(англ.)
// Neural Networks : journal. — 2005. —
Vol. 18
,
no. 5—6
. —
P. 602—610
. —
doi
:
.
S. Fernandez, A. Graves, J. Schmidhuber. An application of recurrent neural networks to discriminative keyword spotting. Intl. Conf. on Artificial Neural Networks ICANN’07, 2007.
D. Eck and J. Schmidhuber. Learning The Long-Term Structure of the Blues. In J. Dorronsoro, ed., Proceedings of Int. Conf. on Artificial Neural Networks ICANN’02, Madrid, pages 284—289, Springer, Berlin, 2002.
Schmidhuber, J.; Gers, F.; Eck, D.; Schmidhuber, J.; Gers, F.
Learning nonregular languages: A comparison of simple recurrent networks and LSTM
(англ.)
//
(англ.)
(
: journal. — 2002. —
Vol. 14
,
no. 9
. —
P. 2039—2041
. —
doi
:
.
Perez-Ortiz, J. A.; Gers, F. A.; Eck, D.; Schmidhuber, J.
(англ.)
// Neural Networks : journal. — 2003. —
Vol. 16
,
no. 2
. —
P. 241—250
. —
doi
:
.
A. Graves, J. Schmidhuber. Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks. Advances in Neural Information Processing Systems 22, NIPS’22, pp 545—552, Vancouver, MIT Press, 2009.
A. Graves, S. Fernandez,M. Liwicki, H. Bunke, J. Schmidhuber. Unconstrained online handwriting recognition with recurrent neural networks. Advances in Neural Information Processing Systems 21, NIPS’21, pp 577—584, 2008, MIT Press, Cambridge, MA, 2008.
M. Baccouche, F. Mamalet, C Wolf, C. Garcia, A. Baskurt. Sequential Deep Learning for Human Action Recognition. 2nd International Workshop on Human Behavior Understanding (HBU), A.A. Salah, B. Lepri ed. Amsterdam, Netherlands. pp. 29-39. Lecture Notes in Computer Science 7065. Springer. 2011
Hochreiter, S.; Heusel, M.; Obermayer, K.
Fast model-based protein homology detection without alignment
(англ.)
// Bioinformatics : journal. — 2007. —
Vol. 23
,
no. 14
. —
P. 1728—1736
. —
doi
:
. —
.