Нейронная сеть (значения)
- 1 year ago
- 0
- 0

Нейронная сеть с прямой связью — искусственная нейронная сеть, в которой соединения между узлами не образуют цикл . Такая сеть отличается от рекуррентной нейронной сети .
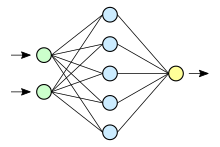
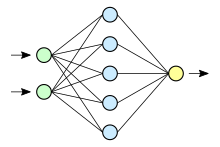
Нейронная сеть с прямой связью была первым и самым простым типом искусственной нейронной сети . В этой сети информация перемещается только в одном направлении вперед от входных узлов, через скрытые узлы (если они есть) и к выходным узлам. В сети нет циклов или петель обратных связей .
Самым простым видом нейронной сети является однослойная сеть персептрона, которая состоит из одного слоя выходных узлов; входы которой идут непосредственно на выходы через серию весов. Сумма произведений весов и входов рассчитывается в каждом узле, и если значение превышает некоторый порог (обычно 0), нейрон срабатывает и принимает активированное значение (обычно 1); в противном случае он принимает деактивированное значение (обычно −1). Нейроны с такой функцией активации также называют искусственными нейронами или линейными пороговыми юнитами. В литературе термин персептрон часто относится к сетям, состоящим только из одного из этих юнитов. Подобный нейрон был описан Уорреном Мак-Каллоком и Уолтером Питтсом в 1940-х годах.
Персептрон может быть создан с использованием любых значений для активированного и деактивированного состояний, пока пороговое значение находится между ними.
Перцептроны могут обучаться с помощью простого алгоритма обучения, который обычно называется дельта-правилом . Он вычисляет ошибки между вычисленными выходными данными и образцами выходных данных и использует их для создания корректировки весов, реализуя таким образом форму градиентного спуска .
Однослойные персептроны способны изучать только линейно разделимые структуры; в 1969 году в известной монографии под названием « Персептроны » Марвина Мински и Сеймура Паперта показали, что однослойная сеть персептронов не может выучить функцию XOR (тем не менее, было известно, что многослойные персептроны способны производить любую возможную булеву функцию ).
Хотя единичная пороговая единица довольно ограничена в своих вычислительных мощностях, было показано, что сети параллельных пороговых единиц могут аппроксимировать любую непрерывную функцию от компактного интервала действительных чисел до интервала [-1,1]. Этот результат можно найти у Питера Ауэра, Харальда Бургштайнера и Вольфганга Маасса «Правило обучения для очень простых универсальных аппроксиматоров, состоящих из одного слоя перцептронов» .
Однослойная нейронная сеть может вычислять непрерывный выход вместо пошаговой функции . Распространенным выбором является так называемая логистическая функция:
При таком выборе однослойная сеть идентична модели логистической регрессии , широко используемой в статистическом моделировании . Логистическая функция также известна как сигмовидная функция . Она имеет непрерывную производную, что позволяет использовать её в обратном распространении . Эта функция также предпочтительна, потому что ее производная легко вычисляется:
(Тот факт, что f удовлетворяет приведенному выше дифференциальному уравнению, легко показать, применив правило цепочки )
Этот класс сетей состоит из нескольких уровней вычислительных блоков, обычно связанных между собой с помощью прямой связи. Каждый нейрон в одном слое имеет направленные связи с нейронами последующего слоя. Во многих приложениях устройства этих сетей применяют сигмовидную функцию в качестве функции активации.
Теорема универсального приближения для нейронных сетей гласит, что каждая непрерывная функция, отображающая интервалы действительных чисел в некоторый выходной интервал действительных чисел, может быть произвольно приближена многослойным персептроном только с одним скрытым слоем. Этот результат справедлив для широкого диапазона функций активации, например, для сигмоидальных функций.
В многослойных сетях используется множество методов обучения, наиболее популярным из которых является обратное распространение. Здесь выходные значения сравниваются с правильным ответом для вычисления значения некоторой предопределенной функции ошибки. Затем различными способами ошибка возвращается по сети. Используя эту информацию, алгоритм корректирует вес каждого соединения, чтобы уменьшить значение функции ошибки на некоторое небольшое значение. После повторения этого процесса для достаточно большого количества тренировочных циклов сеть обычно будет сходиться к некоторому состоянию, в котором погрешность вычислений мала. В этом случае можно сказать, что сеть изучила определенную целевую функцию . Для правильной настройки весов применяется общий метод нелинейной оптимизации, который называется градиентным спуском. Для этого сеть вычисляет производную функции ошибки по весам сети и изменяет веса таким образом, чтобы ошибка уменьшалась (таким образом, спускаясь вниз по поверхности функции ошибки). По этой причине обратное распространение может применяться только в сетях с дифференцируемыми функциями активации.
В общем, проблема обучения сети для эффективной работы даже на образцах, которые не использовались в качестве обучающих, является довольно тонкой проблемой, требующей дополнительных методов. Это особенно важно для случаев, когда доступно только очень ограниченное количество обучающих образцов . Опасность заключается в том, что сеть перекрывает данные обучения и не в состоянии захватить истинный статистический процесс, генерирующий данные. Вычислительная теория обучения связана с обучением классификаторов на ограниченном количестве данных. В контексте нейронных сетей простая эвристика , называемая ранней остановкой, часто гарантирует, что сеть будет хорошо обобщаться для примеров, не входящих в обучающий набор.
Другими типичными проблемами алгоритма обратного распространения являются скорость сходимости и возможность попадания в локальный минимум функции ошибки. Сегодня существуют практические методы, которые делают обратное распространение в многослойных персептронах инструментом выбора для многих задач машинного обучения .
Можно также использовать серию независимых нейронных сетей, модерируемых каким-то посредником, подобное поведение происходит в мозге. Эти нейроны могут работать раздельно и справляться с большой задачей, и результаты могут быть окончательно объединены .