Последние дни Помпеи (роман)
- 1 year ago
- 0
- 0
Восстановление после катастроф (в русскоязычных источниках также используется не вполне корректный термин аварийное восстановление ) включает в себя набор политик, инструментов и процедур, позволяющих восстановить или продолжить работу жизненно важной технологической инфраструктуры и систем после стихийного бедствия или техногенной катастрофы . Аварийное восстановление сосредоточено на информационных технологиях (ИТ) или технологических системах, поддерживающих критические бизнес-функции, в отличие от обеспечения непрерывности бизнеса, которое предполагает сохранение всех основных аспектов функционирования бизнеса, несмотря на значительные нарушения работы; поэтому его можно рассматривать как подмножество задач обеспечения непрерывности бизнеса . Восстановление после катастроф предполагает, что основная часть первоначально работавшей информационной системы не подлежит восстановлению в течение некоторого времени, и представляет собой процесс восстановления данных и сервисов на второстепенных уцелевших площадках, противоположный процессу восстановления информационных систем на исходное место.
Планирование непрерывность ИТ-услуг (IT service continuity, ITSC) — это подмножество планирования непрерывности бизнеса ( business continuity planning, BCP) , в котором основное внимание уделяется целевой точке восстановления (RPO) и целевому времени восстановления (RTO). Этот процесс включает в себя два вида планирования; Планирование аварийного восстановления ИТ и более широкое планирование устойчивости ИТ. Кроме того, он также включает в себя элементы управления ИТ-инфраструктурой и услугами, относящимися к связи, такими как (голосовая) телефония и передача данных.
Планирование включает организацию резервных площадок, независимо от того, являются ли они горячими, теплыми или холодными, а также опорных резервных площадок с оборудованием, необходимым для обеспечения непрерывности работы.
В 2008 году Британский институт стандартов опубликовал специальный стандарт, связанный и поддерживающий стандарт непрерывности бизнеса BS 25999, под названием BS25777, специально для согласования непрерывности работы IT-систем с непрерывностью бизнеса . Этот стандарт был отозван после публикации в марте 2011 г. стандарта ISO/IEC 27031 «Методы обеспечения безопасности. Руководство по обеспечению готовности информационных и коммуникационных технологий к обеспечению непрерывности бизнеса» .
ITIL также определяет некоторые из этих терминов .
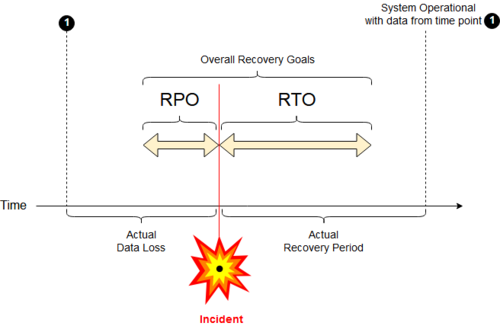
Цели по времени восстановления (Recovery Time Objective, RTO Этот термин также переводится как "Целевое время восстановления") — это целевые продолжительность времени и уровень обслуживания , в рамках которых бизнес-процесс должен быть восстановлен после аварии (или сбоя), чтобы избежать неприемлемых последствий, связанных с перерывом в работе бизнеса .
В соответствии с методологией планирования обеспечения непрерывности бизнеса RTO устанавливается во время анализа воздействия на бизнес (Business Impact Analysis, BIA) владельцем (владельцами) процесса и включает определение временных рамок для альтернативных или ручных обходных путей восстановления.
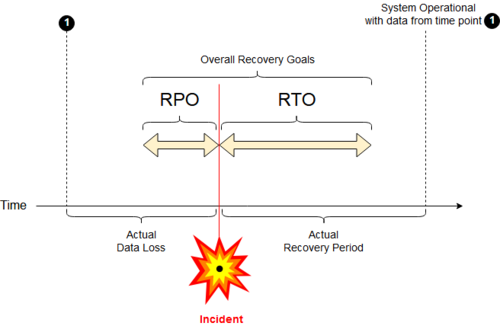
В литературе по этому вопросу RTO упоминается как взаимодополняющий с целевой точкой восстановления (RPO). Вместо они описывают пределы приемлемой или «допустимой» производительности ITSC. RTO и RPO измеряют производительность ITSC с точки зрения времени, потерянного из-за нормального функционирования бизнес-процессов, и данных, потерянных или не зарезервированных в течение этого периода (RPO), соответственно .
В обзоре Forbes отмечается , что фактическое время восстановления (Recovery Time Actual, RTA) на самом деле является критически важным показателем для обеспечения непрерывности бизнеса и аварийного восстановления.
Группа обеспечения непрерывности бизнеса проводит репетиции с таймингом фактически выполняемых действий, во время которых RTA определяется и корректируется при необходимости .
Целевая точка восстановления ( Recovery Point Objective , RPO ) — это максимальный целевой период, в течение которого транзакционные данные теряются из IT-службой из-за крупного инцидента .
Например, в случае, если RPO измеряется в минутах (или даже в нескольких часах), то на практике необходимо постоянно поддерживать удаленные зеркальные резервные копии, поскольку ежедневного резервного копирования на ленте за пределами площадки недостаточно .
Восстановление, которое не является мгновенным, позволит восстановить транзакционные данные в течение некоторого времени и сделать это без значительных рисков или потерь.
RPO измеряет максимальное время, в течение которого последние данные могли быть безвозвратно потеряны в случае серьезного инцидента, и не является прямым показателем количества таких потерь. Например, если BC планирует восстановить данные до последней доступной резервной копии, то RPO — это максимальный интервал между такими резервными копиями, которые были безопасно удалены из хранилища.
Часто неверно истолковывается, что RPO определяется существующим режимом резервного копирования, тогда как в действительности анализ влияния на бизнес определяет RPO для каждой службы. Когда требуются удаленные данные, период, в течение которого данные могут быть потеряны, часто начинается с момента подготовки резервных копий, а не с момента их переноса за пределы площадки .
Точка синхронизации данных (она же - момент резервного копирования ) — это момент времени, когда выполняется резервное копирование физических данных. В наиболее простой реализации это момент, когда обработка очереди обновления данных в системе останавливается на время выполнения копирования с диска на диск. В современных системах обработка данных, как правило, продолжается параллельно с резервным копированием, которое осуществляется с использованием мгновенных снимков . Резервная копия будет отражать более раннюю версию данных, а не то их состояние, которое возникло, когда данные копируются на резервный носитель или передаются в резервную локацию.
RTO и RPO должны быть сбалансированы с учетом бизнес-рисков, а также всех других основных критериев проектирования системы.
RPO привязана ко времени выгрузки резервных копий за пределы площадки. Синхронное копирование данных на внешнее зеркало позволяет преодолеть большинство непредвиденных проблем с доступностью основной площадки. Физическое перемещение лент (или других переносных носителей) за её пределы обеспечивает часть потребностей в резервном копировании при относительно низких затратах. Восстановление из таких копий может быть осуществлено на заранее выбранной площадке .
Для больших объемов ценных транзакционных данных аппаратное обеспечение может быть разделено на две или более площадок путем разделения по географическим областям, что повышает отказоустойчивость.
При более детальном планировании восстановления могут быть, также, использованы такие показатели как DOO – Degraded Operations Objective – допустимое замедление выполнения операций системой, происходящее в процессе перевода обработки данных на резервную площадку и NRO – Network Recovery Objective – минимальная полоса пропускания сети, которая подлежит восстановлению, чтобы обеспечить минимально приемлемые рабочие показатели восстанавливаемой системы .
Планирование аварийного восстановления и информационных технологий (ИТ) начало разрабатываться в середине-конце 1970-х годов, когда руководители компьютерных центров начали осознавать зависимость своих организаций от компьютерных систем.
В то время большинство систем представляли собой мейнфреймы , ориентированные на пакетную обработку . Другой удаленный мейнфрейм может быть загружен с резервных лент в ожидании восстановления основной площадки; время простоя было относительно менее критичным.
Индустрия аварийного восстановления появилась в качестве поставщика резервных компьютерных центров. Один из первых таких центров был расположен в Шри-Ланке (Sungard Availability Services, 1978) developed to provide backup computer centers. One of the earliest such centers was located in Sri Lanka (Sungard Availability Services, 1978). .
В 1980-х и 90-х годах по мере роста внутрикорпоративного разделения времени, онлайн-ввода данных и обработки в режиме реального времени потребовалась большая доступность ИТ-систем.
Непрерывность ИТ-услуг важна для многих организаций при внедрении управления непрерывностью бизнеса (BCM) и управления информационной безопасностью (ICM), а также как часть внедрения и управления информационной безопасностью, а также управления непрерывностью бизнеса, как указано в ISO/IEC 27001 и соответственно.
Рост облачных вычислений с 2010 года продолжает эту тенденцию: в настоящее время еще менее важно, где физически обслуживаются вычислительные службы, просто до тех пор, пока сама сеть достаточно надежна (отдельная проблема и не вызывает особого беспокойства, поскольку современные сети очень устойчивы). по дизайну). «Восстановление как услуга» (RaaS) — это одна из функций безопасности или преимуществ облачных вычислений, продвигаемых Cloud Security Alliance .
Катастрофы могут быть классифицированы на три широких категории угроз и опасностей. К первой категории относятся стихийные бедствия, такие как наводнения, ураганы, торнадо, землетрясения и эпидемии.
Вторая категория – это технологические опасности, которые включают аварии или отказы систем и сооружений, такие как взрывы трубопроводов, транспортные аварии, сбои в работе коммунальных служб, прорывы плотин и случайные выбросы опасных материалов.
Третья категория — это антропогенные угрозы, которые включают преднамеренные действия, такие как активные атаки злоумышленников, химические или биологические атаки, кибератаки на данные или инфраструктуру и саботаж. Меры по обеспечению готовности ко всем категориям и типам стихийных бедствий относятся к пяти областям миссии: предотвращение, защита, смягчение последствий, реагирование и восстановление .
Недавние исследования подтверждают идею о том, что внедрение более целостного подхода к планированию до стихийных бедствий является более рентабельным в долгосрочной перспективе. Каждый доллар, потраченный на смягчение опасностей (например, план аварийного восстановления), экономит обществу 4 доллара на реагировании и затратах на восстановление .
Статистика аварийного восстановления за 2015 год показывает, что простой в течение одного часа может стоить
Поскольку ИТ-системы становятся все более важными для бесперебойной работы компании и, возможно, экономики в целом, возрастает важность обеспечения непрерывной работы этих систем и их быстрого восстановления. Например, 43% компаний, в которых произошла крупная потеря бизнес-данных, никогда не открываются повторно, а 29% закрываются в течение двух лет. В результате к подготовке к продолжению или восстановлению систем необходимо относиться очень серьезно. Это требует значительных затрат времени и денег с целью обеспечения минимальных потерь в случае разрушительного события .
Меры борьбы — это действия или механизмы, которые могут уменьшить или устранить различные угрозы для организаций. В план аварийного восстановления (disaster recovery plan, DRP) могут быть включены различные типы мер.
Планирование аварийного восстановления является частью более крупного процесса, известного как планирование непрерывности бизнеса, и включает планирование возобновления работы приложений, данных, оборудования, электронных коммуникаций (например, сетей) и другой ИТ-инфраструктуры. План обеспечения непрерывности бизнеса (BCP) включает в себя планирование аспектов, не связанных с ИТ, таких как ключевой персонал, объекты, кризисная коммуникация и защита репутации, и должен ссылаться на план аварийного восстановления (DRP) для восстановления/непрерывности инфраструктуры, связанной с ИТ.
Меры по управлению аварийным восстановлением ИТ можно разделить на следующие три типа:
Хорошие меры плана аварийного восстановления требуют, чтобы эти три типа контроля были задокументированы и регулярно применялись с использованием так называемых «тестов аварийного восстановления».
Прежде чем выбрать стратегию аварийного восстановления, планировщик аварийного восстановления сначала обращается к плану обеспечения непрерывности бизнеса своей организации, в котором должны быть указаны ключевые показатели целевой точки восстановления и цели по времени восстановления Затем показатели бизнес-процессов сопоставляются с их системами и инфраструктурой .
Отсутствие надлежащего планирования может увеличить последствия стихийного катастрофы . После сопоставления метрик организация пересматривает ИТ-бюджет; показатели RTO и RPO должны соответствовать доступному бюджету. Анализ затрат и результатов часто определяет, какие меры аварийного восстановления следует применять.
New York Times пишет, что добавление облачного резервного копирования к преимуществам локального и удаленного архивирования на магнитных лентах «добавляет уровень защиты данных» .
Часто используемые стратегии защиты данных включают:
Во многих случаях организация может предпочесть использовать аутсорсингового поставщика аварийного восстановления для предоставления резервного сайта и систем, а не использовать свои собственные удаленные объекты, все чаще с помощью облачных вычислений.
В дополнение к подготовке к необходимости восстановления систем, организации также принимают меры предосторожности с целью превентивного предотвращения катастрофы. К ним могут относиться:
Один из широко используемых видов классификации планов восстановления - семиуровневая классификация, разработанная в конце 1980-х годов комитетом SHARE Technical Steering Committee, проводившим эту разработку совместно с компанией IBM. Они разработали технический документ, описывающий уровни обслуживания восстановления после катастроф с использованием уровней с 0 по 6. С тех пор появился целый ряд классификаций, конкурирующих с этой и отражающих дальнейшее развитие технологий и индустрии в целом. Разные классификации концентрируются на разных аспектах или технических особенностях процесса восстановления. Так, классификация Wiboobratr и Kosavisutee ориентирована, в основном, на решения DRaaS . Ниже приводится сравнительная таблица таких классификаций .
| Уровень | SHARE/ IBM | Hitachi | Wiboonratr и Kosavisutte | Novell | Xiotech |
|---|---|---|---|---|---|
| 0 | План аварийного восстановления отсутствует. | ||||
| 1 | Осуществляется резервное копирование , резервные копии вывозятся в отдельное зданиеЮ но горячая резервная площадка отсутствует. Этот метод резервирования обозначают как «Pickup Truck Access Method (PTAM) . | Осуществляется резервное копирование на ленту за пределы рабочей площадки. | Возможно восстановление на момент времени. | Резервное копирование на ленту/ручное восстановление. |
Уровень 4.
Резервные копии, осуществляемые по расписанию на "холодную" резервную площадку |
| 2 | Осуществляется резервное копирование, имеется горячая резервная площадка на которую могут быть восстановлены данные из резервной копии . Метод известен как PTAM+hotsite. | Осуществляется резервное копирование на ленту на основную или резервную площадку. | Копии, сделанные на ленту доставляются на заранее подготовленную резервную площадку. | Традиционное сохранение/восстановление образа диска. | |
| 3 | "Электронное хранилище" (electronic vaulting). По сравнению с уровнем 2 добавляется возможность регулярного копирования (и, соответственно, восстановления) данных с основной площадки. Типичное время восстановления - 24 часа . | "Электронное хранилище" - аналогично классификации SHARE/IBM. | Дисковые копии, обеспечивающие восстановление на момент времени осуществляются в несколько локаций | Гибкое (в том числе пофайловое и с выбором версии файла для восстановления) сохранение/восстановление образа диска. |
Уровень 3.
Относительно быстрое восстановление из резервных копий, осуществляемых асинхронно или по расписанию на "тёплую" резервную площадку. |
| 4 | Создаются копии, позволяющие осуществлять восстановление на момент времени . | Единичная резервная копия, записываемая на диск. | Осуществляется удалённое журналирование работы системы. | Резервное копирование/восстановление на основе виртуализации. | |
| 5 | Обеспечивается транзакционная целостность данных . | Возможность восстановления с использованием консолидации файлов с разных образов дисков | Параллельное создание теневой копии рабочей базы данных | Резервирование на основе серверов, работающих в кластере. |
Уровень 2.
Быстрое восстановление из асинхронной копии, осуществляемой на горячую резервную площадку. |
| 6 | Нулевые или малые потери данных после восстановленияю. | Наличие данных на разделяемом между основной и резервной системами диске. | Осуществляется удалённое копирование данных. | ||
| 7 | Высокоавтоматизированное восстановление. | Зеркалирование дисков между основной и резервной системой. | Осуществляется удалённое отказоустойчивое копирование данных. |
Уровень 1.
Мгновенное восстановление из синхронной копии, осуществляемой на горячую резервную площадку. |
|
| 8 | Полное дублирование данных. | ||||
Подразумевается, что каждый следующий уровень в рамках одной из классификаций дополняет или заменяет своими свойствами предыдущий.
Аварийное восстановление как услуга (DRaaS) — это соглашение с третьей стороной, поставщиком услуг и/или оборудования. . Обычно предлагается поставщиками услуг как часть их портфеля услуг. Ряд крупных поставщиков оборудования предлагают в качестве части такой услуги модульные датацентры , позволяющие максимально быстро развернуть необходимые для аварийного восстановления мощности оборудования.
.. patient records
Sungard .. founded 1978