Visible Speech
- 1 year ago
- 0
- 0

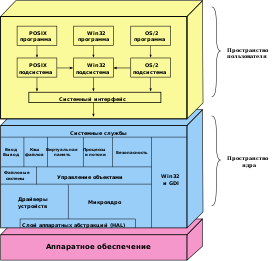
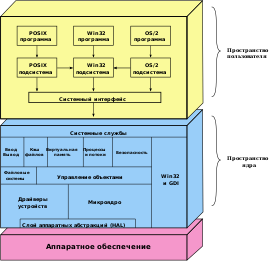
Speech Application Programming Interface (SAPI) — интерфейс программирования приложений , основанный на технологии COM , предназначенный для распознавания и синтеза речи.
Распознавание речи — процесс преобразования произнесённых слов в печатный текст. Распознавание речи включает в себя:
Распознающая программа (движок распознавания текста) итерационно сравнивает распознанный текст с правилами грамматики приложения и при совпадении текста с серией правил формирует выходной поток XML с использованием языка разметки семантики ( англ. Semantic Markup Language , SML). Выходной поток содержит распознанный текст, значения вероятностей правильного распознания и может содержать семантические значения, присвоенные при помощи разметки интерпретации семантики . Распознанный текст обычно используется для ввода данных при помощи диктовки и для управления приложениями при помощи речевых команд.
Размер правил грамматики ограничивает возможности распознавания текста. Большинство программ, поддерживающих диктовку, для обеспечения наиболее точного распознавания настраиваются на речевые обороты конкретного пользователя. Режим управления речевыми командами более прост для реализации, поскольку содержание правил грамматики ограничено имеющимися командами .
Синтез речи — процесс преобразования текста в произносимые слова. Синтез речи включает в себя:
Движки преобразования текста в речь могут использовать один из двух способов синтеза голоса:
(англ.) . MSDN Library . Microsoft (2012). Дата обращения: 24 июля 2012. Архивировано из 29 сентября 2012 года.
| Проприетарное ПО | |
|---|---|
| Свободное ПО | |
| Машина |
|
| Приложения |
|
| Протоколы | |
|
Разработчики/
Исследователи |
|
| Процесс | |