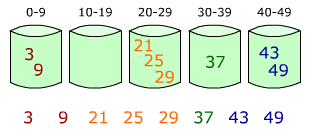
Блочная сортировка
- 1 year ago
- 0
- 0

Устойчивая (стабильная) сортировка — сортировка , которая не меняет относительный порядок сортируемых элементов, имеющих одинаковые ключи, по которым происходит сортировка.
Устойчивость является очень важной характеристикой алгоритма сортировки, но тем не менее она практически всегда может быть достигнута путём удлинения исходных ключей за счёт дополнительной информации об их первоначальном порядке. Несмотря на кажущуюся необходимость, вытекающую из названия, устойчивость совсем не обязательна для правильности сортировки и чаще всего не соблюдается, так как для её обеспечения практически всегда необходимы дополнительная память и время.
При сортировке записей вида [фамилия, имя, отчество] по фамилии значения ключей для Иванов Сергей и Иванов Иван будут одинаковы, поэтому устойчивая сортировка не переставит Сергея и Ивана местами ( Python 3 , сортировка timsort ):
records = [
{'фамилия': 'Иванов', 'имя': 'Сергей', 'отчество': 'Михайлович',},
{'фамилия': 'Иванов', 'имя': 'Иван', 'отчество': 'Борисович',},
{'фамилия': 'Абрамов', 'имя': 'Юрий', 'отчество': 'Петрович',},
]
records.sort(key=lambda x: x['фамилия']) # сортировка по ключу "фамилия"
for r in records:
print('%-12s %-12s %-12s' % (r['фамилия'], r['имя'], r['отчество']))
В результате записи будут отсортированы только по фамилии, с сохранением исходного порядка среди записей с одинаковыми фамилиями:
Абрамов Юрий Петрович Иванов Сергей Михайлович Иванов Иван Борисович
Сортировка, которая является основным затратным элементом преобразования Барроуза — Уиллера , должна быть устойчивой.
Ниже приводятся описания алгоритмов устойчивой сортировки с временем работы не хуже O( n log 2 n ) (кроме наихудших случаев в алгоритме с использованием устойчивого разделения). Во всех псевдокодах пара косых // означает комментарий до конца строки как в языке C++.
При этом алгоритме сортировки сначала осуществляется рекурсивное разделение исходного массива на части до тех пор, пока в каждой части массива не окажется один или ноль элементов (на каждом шаге рекурсии осуществляется разделение пополам). После этого полученные части попарно «сливаются». Общая сложность алгоритма — O( n log n ), при этом алгоритму требуется O( n ) дополнительной памяти для хранения слитых массивов.
Данный алгоритм похож на алгоритм быстрой сортировки . Так же как и в алгоритме быстрой сортировки, в данном алгоритме исходный массив разделяется на две части — в одной все элементы меньше или равны некоторому опорному элементу, а в другой — больше или равны. После этого разделённые части массива рекурсивно сортируются таким же образом. Отличие этого алгоритма от алгоритма быстрой сортировки в том, что здесь используется устойчивое разделение вместо неустойчивого. Ниже приведена реализация данного алгоритма на псевдокоде:
Sort(a[1..n])
if(n > 1) then
N ← a[ 1 ];
m ← StablePartition(a[1..n], N);
Sort(a[1..m]);
Sort(a[m+1..n]);
StablePartition(a[1..n], N)
if( n > 1 ) then
m ← ⌊ n/2 ⌋;
m1 ← StablePartition(a[1..m], N);
m2 ← m+StablePartition(a[m+1..n], N);
Rotate(a[m1..m2], m);
return(m1 + (m2-m));
else
if(a[1] < N) then
return(1);
else
return(0)
Процедура Rotate:
Rotate(a[1..n], m)
if( n > m > 1 ) //в массиве хотя бы два элемента и сдвиг имеет смысл
shift ← m-n; //число позиций на которое будет осуществляться сдвиг
gcd ← GCD(m-1, n); //GCD - это наибольший общий делитель
for i ← 0 to gcd-1 do
head ← i+1;
headVal ← a[head];
current ← head;
next ← head+shift;
while(next ≠ head) do
a[current] ← a[next];
current ← next;
next ← next+shift;
if(next>n)
next ← next-n;
a[current] ← headVal;
Для устойчивого разделения массива требуется O( n log n ) элементарных операций. Так как «глубина» осуществляемого рекурсивного спуска в среднем случае составляет O(log n ) то общая сложность алгоритма составляет O( n log² n ). При этом алгоритму для осуществления рекурсии потребуется O(log n ) стековой памяти, хотя в худшем случае общая сложность равна O( n ² log n ) и требуется O( n ) памяти.
Все описанные ниже алгоритмы основаны на слиянии уже отсортированных массивов без использования дополнительной памяти сверх O(log² n ) стековой памяти (это — т. н. условие минимальной памяти ) и отличаются лишь алгоритмом слияния. Далее приведён псевдокод алгоритмов (алгоритмы слияния — процедура Merge — приводятся отдельно для каждого метода):
Sort(a[1..n])
if( n > 1 ) then
m ← n/2 ;
Sort(a[1..m]);
Sort(a[m+1..n]);
Merge(a[1..n], m);
В алгоритме Пратта в отсортированных массивах находят два элемента α и β , которые являются медианами массива, состоящего из элементов обоих массивов. Тогда весь массив можно представить в виде aαbxβy . После этого осуществляется циклический сдвиг элементов, в результате чего получаем такую последовательность: axβαby . Далее алгоритм слияния рекурсивно повторятся для массивов ax и by.
Merge(a[1..n], m)
if(m ≠ 1 and m ≠ n) //это условие означает, что в массиве должно быть хотя бы 2 элемента
if( n-1 > 2 ) //случай, когда элементов ровно два, приходится рассматривать отдельно
if( m-1 > n-m )
leftBound←1;
rightBound←m;
while( leftBound < rightBound ) do //в этом цикле ищем медианы
m1 ← (leftBound+rightBound)/2;
m2 ← FindFirstPosition(a[m..n], a[ m1 ]); //реализация процедуры FindFirstPosition см. след. пункт
if( m1 + (m2-m) > n/2 ) then
rightBound ← m1-1;
else
leftBound ← m1+1;
Rotate(a[m1..m2], m);
Merge(a[1..m1+(m2-m)], m1);
Merge(a[m1+(m2-m)+1..n], m2);
else
if(a[m] < a[1])
a[m]⟷a[1];
Циклический сдвиг элементов требует O( n ) элементарных операций и O(1) дополнительной памяти, а поиск медиан в двух уже отсортированных массивах — O(log² n ) элементарных операций и O(1) дополнительной памяти. Так как осуществляется O(log n ) шагов рекурсии, то сложность такого алгоритма слияния составляет O( n log n ), а общая сложность алгоритма сортировки — O( n log² n ). При этом алгоритму потребуется O(log² n ) стековой памяти.
От поиска медиан в предыдущем алгоритме можно избавиться следующим образом. В большем из двух массивов выбираем средний элемент α (опорный элемент). Далее в меньшем массиве находим позицию первого вхождения элемента большего или равного α. Назовём его β. После этого осуществляется циклический сдвиг элементов так же как и в алгоритме Пратта ( aαbxβy → axβαby ) и осуществляется рекурсивное слияние полученных частей. Псевдокод алгоритма слияния приведён ниже.
Merge(a[1..n], m)
if(m ≠ 1 and m ≠ n) //это условие означает что в массиве должно быть хотя бы 2 элемента
if( n-1 > 2 ) //случай когда элементов ровно два приходится рассматривать отдельно
if( m-1 > n-m )
m1 ← (m+1)/2 ;
m2 ← FindFirstPosition(a[m..n], a[ m1 ]);
else
m2 ← (n+m)/2 ;
m1 ← FindLastPosition(a[1..m], a[ m2 ]);
Rotate(a[m1..m2], m);
Merge(a[1..m1+(m2-m)], m1);
Merge(a[m1+(m2-m)+1..n], m2);
else
if(a[ m ] < a[ 1 ])
a[ m ]⟷a[ 1 ];
Процедуры FindFirstPosition и FindLastPosition практически совпадают с процедурой двоичного поиска:
FindFirstPosition(a[1..n], x)
leftBound ← 1;
rightBound ← n;
current ← 1;
while(leftBound < rightBound) do
current ← ⌊(leftBound+rightBound)/2⌋;
if(a[ current ] < x) then
leftBound ← current+1
else
rightBound ← current;
return(current);
FindLastPosition(a[1..n], x)
leftBound ← 1;
rightBound ← n;
current ← 1;
while(leftBound < rightBound) do
current ← ⌊(leftBound+rightBound)/2⌋;
if( x < a[ current ] ) then
rightBound ← current;
else
leftBound ← current+1
return(current);
В отличие от алгоритма Пратта, в данном алгоритме разбиение может быть существенно неравным. Но даже в худшем случае алгоритм разобьёт весь диапазон [ a .. y ] в соотношении 3:1 (если все элементы второго диапазона будут больше или меньше опорного и при этом оба диапазона имеют равное число элементов). Это гарантирует логарифмическое число шагов рекурсии при слиянии любых массивов. Таким образом получаем, что так же, как и в алгоритме Пратта, сложность алгоритма слияния равна O( n log n ), сложность алгоритма сортировки — O( n log² n ), а требуемая память — O(log² n ).
| Теория |
|
|---|---|
| Обменные | |
| Выбором | |
| Вставками | |
| Слиянием | |
| Без сравнений | |
| Гибридные | |
| Прочее | |
| Непрактичные | |




















