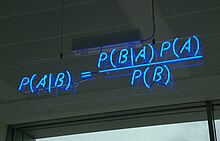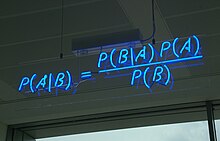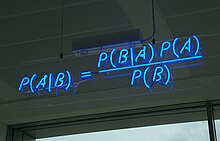
Теорема Байеса
- 1 year ago
- 0
- 0

Коэффицие́нт Ба́йеса — байесовская альтернатива проверке статистических гипотез . Байесовское сравнение моделей — метод выбора моделей на основе коэффициентов Байеса. Обсуждаемые модели являются статистическими моделями . Целью коэффициента Байеса является количественное выражение поддержки модели по сравнению с другой моделью, независимо от того, верны модели или нет . Техническое определение понятия «поддержка» в контексте байесовского вывода дано ниже.
Коэффициент Байеса является для предельного правдоподобия двух гипотез, обычно нулевой гипотезы и альтернативной .
Апостериорная вероятность модели M , задаваемой данными D , определяется теоремой Байеса :
Ключевой зависящий от данных член является правдоподобием модели M с учётом данных D и он представляет вероятность того, что некоторые данные получены в предположении принятия модели M . Правильное вычисление этого члена является ключом байесовского сравнения моделей.
Если дана задача выбора модели , в которой мы должны выбрать между двумя моделями на основе наблюдаемых данных D , относительная правдоподобность двух различных моделей M 1 и M 2 , параметризованных векторами параметров и , определяется коэффициентом Байеса K , определяемым как
Если две модели априори одинаково вероятны, так что коэффициент Байеса равен отношению апостериорных вероятностей моделей M 1 и M 2 . Если вместо интеграла коэффициента Байеса используется правдоподобие, соответствующее максимальной оценке правдоподобия параметра для каждой статистической модели, то тест становится классическим тестом отношения правдоподобия . В отличие от теста отношения правдоподобия, байесовское сравнение моделей не зависит от какого-либо конкретного набора параметров, так как оно вычисляется в результате интегрирования по всем параметрам в каждой модели (с учётом априорных вероятностей ). Однако преимущество использования коэффициентов Байеса заключается в том, что они автоматически и вполне естественным образом включают штраф за избыточное включение структуры модели . Это ограждает от переобучения . В случае моделей, у которых явный вид функции правдоподобия неизвестен или её вычисление слишком затратно, для байесовского выбора модели могут быть использованы , хотя следует принять во внимание, что приближённая байесовская оценка коэффициентов Байеса часто смещена .
Другие подходы:
Значение K > 1 означает, что гипотеза M 1 сильнее поддерживается данными, чем гипотеза M 2 . Заметим, что классическая проверка статистических гипотез принимает по умолчанию одну гипотезу (или модель) (« нулевая гипотеза »), и рассматривает только свидетельства против неё. Гарольд Джеффрис приводит таблицу для интерпретации полученного значения K :
| K | dHart | битов | Весомость доказательств |
|---|---|---|---|
| < 10 0 | 0 | — | Отрицательная (поддерживает M 2 ) |
| 10 0 ...10 1/2 | 0...5 | 0...1,6 | Едва заслуживает внимания |
| 10 1/2 ...10 1 | 5...10 | 1,6...3,3 | Значительная |
| 10 1 ...10 3/2 | 10...15 | 3,3...5,0 | Сильная |
| 10 3/2 ...10 2 | 15...20 | 5,0...6,6 | Очень сильная |
| > 10 2 | > 20 | > 6,6 | Убедительная |
Второй столбец даёт соответствующие веса поддержки в единицах (известных также как ), биты добавлены в третьем столбце для ясности. Согласно И. Дж. Гуду , люди в повседневной жизни едва могут разумно оценить разницу в степени доверия гипотезе, соответствующую изменению веса на 1 децибан или 1/3 бита (например, отношение исходов 4:5 в 9 испытаниях с двумя возможными исходами) .
Альтернативную широко цитируемую таблицу предложили Касс и Рафтери (1995) :
| log 10 K | K | Весомость доказательств |
|---|---|---|
| от 0 до 1 ⁄ 2 | от 1 до 3,2 | Достойна лишь простого упоминания |
| от 1 ⁄ 2 до 1 | от 3,2 до 10 | Положительная |
| от 1 до 2 | от 10 до 100 | Сильная |
| > 2 | > 100 | Очень сильная |
Использование коэффициентов Байеса или классической проверки статистических гипотез происходит в контексте вывода , а не принятия решений в условиях неопределённости . То есть мы только хотим найти, какая гипотеза верна, а не принимаем действительное решение на основе этой информации. делает строгое различие между этими двумя подходами, поскольку классические методы проверки гипотез не когерентны в байесовском смысле. Байесовские процедуры, включая коэффициенты Байеса, когерентны, так что нет необходимости делать это различие. Вывод тогда просто рассматривается как частный случай принятия решения в условиях неопределённости, в котором конечным действием является возврат значения. Для принятия решений статистики, использующие байесовский подход, могут использовать коэффициент Байеса вместе с априорным распределением и функцией потерь . В контексте вывода функция потерь примет вид . Использование , например, приводит к ожидаемой полезности , принимающей форму расхождение Кульбака — Лейблера .
Предположим, что у нас есть случайная величина , которая принимает значение либо успех, либо неудача. Мы хотим сравнить модель M 1 , где вероятность успеха равна q = ½ , и другую модель M 2 , в которой значение q неизвестно, и мы принимаем в качестве априорного распределения для q однородное распределение на [0,1]. Мы делаем 200 испытаний и получаем 115 успехов и 85 неудач. Правдоподобие может быть вычислено согласно биномиальному распределению :
Тогда мы имеем для гипотезы M 1
тогда как для M 2
Отношение этих величин составляет 1,197…, следовательно, различие «едва заслуживает внимания», хотя выбор склоняется слегка в сторону M 1 .
Проверка этих статистических гипотез на основе M 1 (рассматривается здесь как нулевая гипотеза ) даст совершенно другой результат. Такая проверка утверждает, что гипотеза M 1 должна быть отброшена на уровне значимости 5 %, поскольку вероятность получения 115 или более успехов из выборки в 200 элементов при q = ½ равна 0,0200, а получения экстремума в 115 или более даёт 0,0400. Заметим, что 115 отличается от 100 более чем на два стандартных отклонения . Таким образом, в то время как проверка статистической гипотезы на основе даёт статистическую значимость на уровне 5 %, коэффициент Байеса вряд ли примет это как экстремальный результат. Заметим, однако, что неоднородное априорное распределение (например, такое, которое отражает ожидание, что числа успешных и неуспешных исходов будут одного порядка величины) может привести к коэффициенту Байеса, который больше согласуется с проверкой на основе частотного вывода.
В классическом тесте отношения правдоподобия была бы найдена оценка максимального правдоподобия для q , равная 115 ⁄ 200 = 0,575 , откуда
(вместо усреднения по всем возможным q ). Это даёт отношение правдоподобия 0,1045 и указывает на гипотезу M 2 .
M 2 является более сложной моделью, чем M 1 , поскольку имеет свободный параметр, который позволяет описывать данные более согласованно. Способность коэффициентов Байеса учитывать это является причиной, почему байесовский вывод выдвигается как теоретическое обоснование и обобщение бритвы Оккама , в котором уменьшаются ошибки первого рода .
С другой стороны, современный метод относительного правдоподобия принимает во внимание число свободных параметров моделей, в отличие от классического отношения правдоподобия. Метод относительного правдоподобия можно применить следующим образом. Модель M 1 имеет 0 параметров, а потому её значение информационного критерия Акаике (AIC) равно 2 · 0 − 2 ln 0,005956 ≈ 10,2467 . Модель M 2 имеет 1 параметр, а потому её значение AIC равно 2 · 1 − 2 ln 0,056991 ≈ 7,7297 . Следовательно, M 1 с меньшей вероятностью минимизирует потерю информации, чем M 2 , примерно в exp((7,7297 − 10,2467)/2) ≈ 0,284 раза. Таким образом, M 2 слегка предпочтительнее, но M 1 отбрасывать нельзя.