Структура СУБД
- 1 year ago
- 0
- 0

Оптимизация запросов — это 1) функция СУБД , осуществляющая поиск оптимального плана выполнения запросов из всех возможных для заданного запроса, 2) процесс изменения запроса и/или структуры БД с целью уменьшения использования вычислительных ресурсов при выполнении запроса. Один и тот же результат может быть получен СУБД различными способами ( планами выполнения запросов ), которые могут существенно отличаться как по затратам ресурсов, так и по времени выполнения. Задача оптимизации заключается в нахождении оптимального способа.
В реляционной СУБД оптимальный план выполнения запроса — это такая последовательность применения операторов реляционной алгебры к исходным и промежуточным отношениям, которая для конкретного текущего состояния БД (её структуры и наполнения) может быть выполнена с минимальным использованием вычислительных ресурсов.
В настоящее время известны две стратегии поиска оптимального плана:
Также некоторые СУБД позволяют программисту вмешиваться в поиск оптимального плана в различной степени, от минимального влияния до полного и чёткого указания какой именно план запроса использовать.
Планы выполнения запроса сравниваются исходя из множества факторов (реализации в различных СУБД отличаются), в том числе:
В общем случае соединение выполняется вложенными циклами . Однако этот алгоритм может оказаться менее эффективен, чем специализированные алгоритмы. Например, если у сливаемых таблиц есть индексы по соединяемым полям, или одна или обе таблицы достаточно малы, чтобы быть отсортированными в памяти, то исследуется возможность выполнения слияний .
Как уже отмечалось, суть оптимизации заключается в поиске минимума функции стоимости от перестановки таблиц. Независимо от стратегии, оптимизатор обязан уметь анализировать стоимость для произвольной перестановки, в то время как сами перестановки для анализа предоставляются другим алгоритмом. Исследуемое множество перестановок может отличаться от всего пространства перестановок. Исходя из этого, обобщённый алгоритм работы оптимизатора можно записать так:
ТекущийПорядокТаблиц := НайтиИсходныйПорядокТаблиц; ЛучшийПорядокТаблиц := ТекущийПорядокТаблиц; НаименьшаяСтоимость := МаксимальноВозможнаяСтоимость; Выполнять Стоимость := ОценитьСтоимость(ТекущийПорядокТаблиц); Если Стоимость < НаименьшаяСтоимость То ЛучшийПорядокТаблиц := ТекущийПорядокТаблиц; НаименьшаяСтоимость := Стоимость; КонецЕсли; ТекущийПорядокТаблиц := НайтиСледующийПорядокТаблиц; Пока (ДоступенСледующийПорядокТаблиц);
В теории, при использовании стратегии грубой силы оптимизатор запросов исследует все пространство перестановок всех исходных выбираемых таблиц и сравнивает суммарные оценки стоимости выполнения соединения для каждой перестановки. На практике, при разработке System R было предложено ограничить пространство исследования только левосторонними соединениями, чтобы при выполнении запроса одна из таблиц всегда была представлена образом на диске. Исследование нелевосторонних соединений имеет смысл если таблицы, входящие в соединения, расположены на более чем одном узле.
Для каждой таблицы в каждой из перестановок по статистике оценивается возможность использования индексов. Перестановка с минимальной оценкой и есть итоговый план выполнения запроса.
Алгоритмы генерации всех перестановок обсуждаются в четвёртом томе секции 2 «Искусства программирования для ЭВМ» Дональда Кнута (см. список литературы).
/* * Making estimation of query cost accordingly * current order of tables in query * Function returns value < 0 if it decides not to * make all steps of estimation because the cost of * this order >> the_best_cost (if the_best_cost > 0) * In another case it returns estimated cost (>=0) */ static float est_cost_order (i4_t *res_row_num) { MASK Depend = _AllTblMsk; i4_t tbl_num, prdc_num, i, real_num, ColNum; float cost_all = 0.0, row_num = 1.0; float ind_best_sel, sel; SP_Ind_Info *cur_ind_info; /* estimation of the cost of tables scanning */ for (tbl_num = 0; tbl_num < number_of_tables; tbl_num++) { ind_best_sel = 1.0; real_num = cur_tbl_order [tbl_num]; TblAllBits[tbl_num] = Depend = BitOR (Depend, TblBits [real_num]); /* init of array for information about culumns */ for (i = 0; i < tab_col_num[real_num]; i++) col_stat[i].Sel = 1.0; /* checking information about SPs for current table */ for (prdc_num = 0; prdc_num < number_of_SPs; prdc_num++) if (!(SPs[prdc_num].flag) /* this predicate wasn't used yet */ && CAN_BE_USED (SPs[prdc_num].Depend, Depend) /* predicate can be used now */) { SPs[prdc_num].flag++; cur_ind_info = (SPs_indexes[real_num]) + prdc_num; if (cur_ind_info->Sel) { /* this predicate is SP for current table */ ColNum = cur_ind_info->ColNum; if (col_stat[ColNum].Sel > cur_ind_info->Sel) { col_stat[ColNum].Sel = cur_ind_info->Sel; if (cur_ind_info->IndExists /* there is index for the column of this SP */ && col_stat[ColNum].Sel < ind_best_sel) ind_best_sel = col_stat[ColNum].Sel; } } } /* finding of common selectivity of all simple predicates for current table */ for (i = 0, sel = 1.0; i < tab_col_num[real_num]; i++) sel *=col_stat[i].Sel; /* adding of default selectivity for the rest of predicates */ for (prdc_num = number_of_SPs; prdc_num < number_of_disjuncts; prdc_num++) if (!(SPs[prdc_num].flag) /* this predicate wasn't used yet */ && CAN_BE_USED (SPs[prdc_num].Depend, Depend)/* predicate can be used now */) { SPs[prdc_num].flag++; sel *= DEFAULT_SEL; } number_of_scanned_rows [tbl_num] = number_of_rows[real_num] * ind_best_sel * row_num; /* number_of_scanned_rows [i] - estimated number of rows read from i-th table */ cost_all += number_of_scanned_rows [tbl_num] + OPEN_SCAN_COST * row_num; row_num *= number_of_rows[real_num] * sel; } /* for tbl_num: tables handling */ for (prdc_num = 0; prdc_num < number_of_disjuncts; prdc_num++) SPs[prdc_num].flag = 0; /* adding of the cost of all subqueries */ for (prdc_num = 0; prdc_num < number_of_disjuncts; prdc_num++) { for (tbl_num = 0; tbl_num < number_of_tables; tbl_num++) if (CAN_BE_USED (SPs[prdc_num].SQ_deps, TblAllBits[tbl_num])) break; assert (tbl_num < number_of_tables); /* tbl_num - number of the last (in order) table * * that is referenced in the predicate */ cost_all += SPs[prdc_num].SQ_cost * number_of_scanned_rows [tbl_num]; } *res_row_num = (row_num < 1.0) ? 1 : ((row_num < FLT_MAX_LNG) ? (i4_t)row_num : MAX_LNG); return cost_all; } /* est_cost_order */
Здесь cur_tbl_order — знакомый по предыдущему примеру вектор, содержащий текущий порядок таблиц.
С ростом числа таблиц в запросе количество возможных перестановок растет как n! , следовательно, и время оценки для каждой из них. Это делает проблематичным оптимизацию запросов на основе большого числа таблиц. В поисках решения этой проблемы в 1991 году Kristin Bennett, Michael Ferris, Yannis Ioannidis предложили использовать генетический алгоритм для оптимизации запросов, который дает субоптимальное решение за линейное время.
При использовании генетического алгоритма исследуется только часть пространства перестановок. Таблицы, участвующие в запросе, кодируются в хромосомы. Над ними выполняются мутации и скрещивания. На каждой итерации выполняется восстановление хромосом для получения осмысленной перестановки таблиц и отбор хромосом, которые дают минимальные оценки стоимости. В результате отбора остаются только те хромосомы, которые дают меньшее, по сравнению с предыдущей итерацией, значение функции стоимости. Таким образом происходит исследование и нахождение локальных минимумов функции стоимости. Предполагается, что глобальный минимум не дает существенных преимуществ, по сравнению с лучшим локальным минимумом. Алгоритм повторяется несколько итераций, после чего выбирается наиболее эффективное решение.
При оценке планов выполнения запросов исследуются альтернативные способы выполнения реляционных соединений. Способы выполнения соединений отличаются по эффективности, но обладают ограничениями по применению.
В случае вложенных циклов внешний цикл извлекает все строки из внешней таблицы и для каждой найденной строки вызывает внутренний цикл. Внутренний цикл по условиям объединения и данным внешнего цикла ищет строки во внутренней таблице. Циклы могут вкладываться произвольное количество раз. В этом случае внутренний цикл становится внешним для следующего цикла и т. д.
При оценке различных порядков выполнения вложенных циклов для минимизации накладных расходов на вызов внутреннего цикла предпочтительнее чтобы внешний цикл сканировал меньшее количество строк, чем внутренний.
Для выбора индекса для каждой таблицы прежде всего находятся все потенциальные индексы, которые могут быть применены в исследуемом запросе. Поскольку ключи в индексе упорядочены, то эффективная выборка из него может выполняться только в лексикографическом порядке . В связи с этим, выбор индекса основывается на наличии ограничений для колонок, входящих в индекс, начиная с первой.
Для каждой колонки, входящей в индекс, начиная с первой, ищутся ограничения из всего набора ограничений для данной таблицы, включая условия соединений. Если для первой колонки индекса не может быть найдено ни одного ограничения, то индекс не используется (в противном случае пришлось бы сканировать индекс целиком). Если для очередной колонки ограничений не может быть найдено, то поиск завершается и индекс принимается.
При оценке планов выполнения исследуются альтернативные наборы индексов, которые могут быть использованы для выборки. В случае вложенных циклов наиболее внешний цикл не может использовать ни одного индекса, который ограничивается хотя бы одним условием соединения, поскольку при выполнении этого цикла ни одно из условий соединения полностью не определено. Внутренний цикл не может использовать ни одного индекса с ограничениями, не совместимыми с условиями соединения.
Оставшиеся индексы ранжируются по числу извлекаемых строк и длине ключа. Очевидно, число извлекаемых строк зависит от ограничений. Чем меньше число извлекаемых строк и короче длина ключа, тем выше ранг.
Индекс с наивысшим рангом используется для выборки.
Для выполнения некоторых запросов с агрегацией индекс может сканироваться целиком. В частности:
Если запрошенный порядок выборки совпадает с порядком одного или более индексов , то выполняется оценка возможности сканирования одного из таких индексов целиком.
Если индекс содержит все колонки, необходимые для получения результата , то сканирование таблицы не происходит. Если оптимизатор использует этот фактор, то можно ускорить выборку из таблицы для специализированных запросов путём включения в индекс избыточных колонок, которые будут извлечены непосредственно при поиске по ключу. Подобный метод ускорения запросов следует использовать осторожно.
Если объединяемые таблицы имеют индексы по сравниваемым полям, или одна или обе таблицы достаточно малы, чтобы быть отсортированными в памяти, то объединение может быть выполнено с помощью слияния. Оба отсортированных набора данных сканируются и в них ищутся одинаковые значения. За счёт сортировки слияние эффективнее вложенных циклов на больших объёмах данных, но план выполнения не может начинаться со слияния.
Оценка числа извлекаемых из таблицы строк используется для принятия решения о полном сканировании таблицы вместо доступа по индексу. Решение принимается на том основании, что каждое чтение листовой страницы индекса с диска влечет за собой 1 или более позиционирований и 1 или более чтений страниц таблицы. Поскольку индекс содержит ещё и нелистовые страницы, то извлечение более 0.1-1 % строк из таблицы, как правило, эффективней выполнять полным сканированием таблицы.
Более точная оценка получится на основе следующих показателей:
СУБД старается организовать хранение блоков данных одной таблицы последовательно с целью исключить накладные расходы на позиционирование при полном сканировании ( СУБД Oracle использует предварительное выделение дискового пространства для файлов данных). Эффективность полного сканирования так же увеличивается за счёт упреждающего чтения . При упреждающем чтении СУБД одновременно выдает внешней памяти команды чтения нескольких блоков. Сканирование начинается по завершении чтения любого из блоков. Одновременно продолжается чтение остальных блоков. Эффективность достигается за счёт параллелизма чтения и сканирования.
Если СУБД запущена на нескольких процессорах, то для уменьшения времени ответа сортировки могут выполняться параллельно. Необходимым условием для этого является возможность поместить все извлекаемые данные в оперативную память. Для выполнения сортировки извлекаемые данные разделяются на фрагменты, число которых равно числу процессоров. Каждый из процессоров выполняет сортировку над одним из фрагментов независимо от других. На финальном шаге выполняется слияние отсортированных фрагментов, либо слияние совмещается с выдачей данных клиенту СУБД.
Если СУБД запущена на нескольких узлах, то сортировка параллельно выполняется каждым из узлов, вовлеченных в выполнение запроса. Затем каждый из узлов отправляет свой фрагмент узлу, отвечающему за выдачу данных клиенту, где выполняется слияние полученных фрагментов.
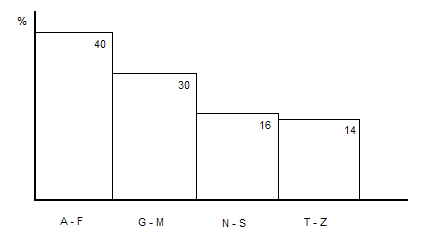
Для оценки потенциального числа строк, извлекаемого из таблицы, РСУБД использует статистику. Статистика имеет вид гистограмм для каждой колонки таблицы, где по горизонтали располагается шкала значений, а высотой столбца отмечается оценка числа строк в процентах от общего числа строк.
Таким образом, если из таблицы извлекаются строки со значением колонки C с ограничением [V1, V2], то можно оценить число строк, попадающих в этот интервал. Алгоритм оценки числа извлекаемых строк следующий:
Как правило, СУБД не знает и не может знать точное число строк в таблице (даже для выполнения запроса SELECT COUNT(*) FROM TABLE выполняется сканирование первичного индекса), поскольку в базе могут храниться одновременно несколько образов одной и той же таблицы с различным числом строк. Для оценки числа строк используются следующие данные:
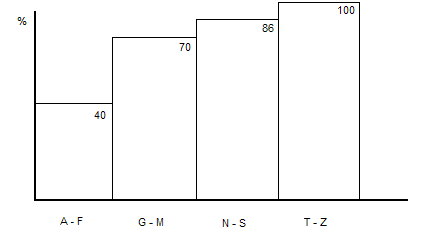
Статистика так же может храниться нарастающим итогом. В этом случае каждый интервал содержит суммарную оценку всех предыдущих интервалов плюс собственную оценку. Для получения оценки числа строк для ограничения [V1, V2] достаточно из оценки интервала, в который попадает V2, вычесть оценку интервала, в который попадает V1.
Сбор статистики для построения гистограмм осуществляется либо специальными командами СУБД , либо фоновыми процессами СУБД . При этом, ввиду того, что база может содержать существенный объём данных, делается выборка меньшего объёма из всей генеральной совокупности строк. Оценка репрезентативности (достоверности) выборки может осуществляться, например, по критерию согласия Колмогорова .
Если данные в таблице существенно изменяются в короткий промежуток времени, то статистика перестает быть актуальной и оптимизатор принимает неверные решения о полном сканировании таблиц. Режим работы базы данных должен быть спланирован таким образом, чтобы поддерживать актуальную статистику, либо не использовать оптимизацию на основе статистики.