обозначает сложение по модулю 2
32
. F зависит от раунда,
K
i
и
s
меняются каждую операцию
.
обозначает сложение по модулю 2
32
. F зависит от раунда,
K
i
и
s
меняются каждую операцию
.
 стала
стала
 ). Выравнивание происходит в любом случае, даже если длина исходного потока уже сравнима с 448.
). Выравнивание происходит в любом случае, даже если длина исходного потока уже сравнима с 448.
 , то дописывают только младшие биты (эквивалентно взятию по модулю
, то дописывают только младшие биты (эквивалентно взятию по модулю
 ). После этого длина потока станет кратной 512. Вычисления будут основываться на представлении этого потока данных в виде массива слов по 512 бит.
). После этого длина потока станет кратной 512. Вычисления будут основываться на представлении этого потока данных в виде массива слов по 512 бит.
 ,
,
 ,
,
 ,
,
 ,
,
 побитовые логические операции
побитовые логические операции
![T[1\ldots 64]](/images/000/064/64646/12.jpg?rand=965096) — 64-элементная таблица данных, построенная следующим образом:
— 64-элементная таблица данных, построенная следующим образом:
![T[n]=\operatorname {int} (2^{32}\cdot |\sin n|)](/images/000/064/64646/13.jpg?rand=323828) .
.
![a=b+((a+\operatorname {Fun} (b,c,d)+X[k]+T[i])\lll s)](/images/000/064/64646/14.jpg?rand=421510) , где
k
— номер 32-битного слова из текущего 512-битного блока сообщения, и
, где
k
— номер 32-битного слова из текущего 512-битного блока сообщения, и
 — циклический сдвиг влево на
s
бит полученного 32-битного аргумента. Число
s
задается отдельно для каждого раунда.
— циклический сдвиг влево на
s
бит полученного 32-битного аргумента. Число
s
задается отдельно для каждого раунда.
 вместо
вместо
 . Результат каждого шага складывается с результатом предыдущего шага, из-за этого происходит более быстрое изменение результата. Для этой же цели оптимизирована величина сдвига на каждом круге. Изменился порядок работы с входными словами в раундах 2 и 3
.
. Результат каждого шага складывается с результатом предыдущего шага, из-за этого происходит более быстрое изменение результата. Для этой же цели оптимизирована величина сдвига на каждом круге. Изменился порядок работы с входными словами в раундах 2 и 3
.
 к определённому 32-разрядному слову в блочном буфере, можно получить второе сообщение с таким же хешем. Ханс Доббертин представил такую формулу:
к определённому 32-разрядному слову в блочном буфере, можно получить второе сообщение с таким же хешем. Ханс Доббертин представил такую формулу:

 ,
,
 ,
,
 ,
,
 . Далее вычисляется последовательность 16-байтных состояний
. Далее вычисляется последовательность 16-байтных состояний
 ,
,
 ,
,
 по правилу
по правилу
 , где
, где
 — некоторая фиксированная функция. Начальное состояние
— некоторая фиксированная функция. Начальное состояние
 называется
инициализирующим вектором
.
называется
инициализирующим вектором
.
 и
и
 , такие что
, такие что
 . Этот метод работает для любого инициализирующего вектора, а не только для вектора используемого по стандарту.
. Этот метод работает для любого инициализирующего вектора, а не только для вектора используемого по стандарту.
 , далее оно модифицируется по некоторым правилам, сформулированным в статье, после чего вычисляется дифференциал хеш-функции, причём
, далее оно модифицируется по некоторым правилам, сформулированным в статье, после чего вычисляется дифференциал хеш-функции, причём
 с вероятностью
с вероятностью
 . К
. К
 и
и
 применяется функция сжатия для проверки условий коллизии; далее выбирается произвольное
применяется функция сжатия для проверки условий коллизии; далее выбирается произвольное
 , модифицируется, вычисляется новый дифференциал, равный нулю с вероятностью
, модифицируется, вычисляется новый дифференциал, равный нулю с вероятностью
 , а равенство нулю дифференциала хеш-функции как раз означает наличие коллизии. Оказалось, что найдя одну пару
, а равенство нулю дифференциала хеш-функции как раз означает наличие коллизии. Оказалось, что найдя одну пару
 и
и
 , можно менять лишь два последних слова в
, можно менять лишь два последних слова в
 , тогда для нахождения новой пары
, тогда для нахождения новой пары
 и
и
 требуется всего около
требуется всего около
 операций хеширования
.
операций хеширования
.

MD2
- 1 year ago
- 0
- 0

MD5 ( англ. Message Digest 5) — 128-битный алгоритм хеширования , разработанный профессором Рональдом Л. Ривестом из Массачусетского технологического института (Massachusetts Institute of Technology, MIT) в 1991 году . Предназначен для создания «отпечатков» или дайджестов сообщения произвольной длины и последующей проверки их подлинности. Широко применялся для проверки целостности информации и хранения хешей паролей.
MD5 — один из серии алгоритмов по построению дайджеста сообщения , разработанный профессором Рональдом Л. Ривестом из Массачусетского технологического института. Был разработан в 1991 году как более надёжный вариант предыдущего алгоритма MD4 . Описан в . Позже были найдены недостатки алгоритма MD4.
В 1993 году Берт ден Бур (Bert den Boer) и Антон Босселарс (Antoon Bosselaers) показали, что в алгоритме возможны псевдоколлизии, когда разным инициализирующим векторам соответствуют одинаковые дайджесты для входного сообщения .
В 1996 году Ганс Доббертин (Hans Dobbertin) объявил о коллизии в алгоритме , и уже в то время было предложено использовать другие алгоритмы хеширования, такие как Whirlpool , SHA-1 или RIPEMD-160 .
Из-за небольшого размера хеша в 128 бит можно рассматривать birthday-атаки . В марте 2004 года был запущен проект MD5CRK с целью обнаружения уязвимостей алгоритма, при помощи birthday-атаки . Проект MD5CRK закончился 17 августа 2004 года, когда (Wang Xiaoyun), Фэн Дэнго (Feng Dengguo), Лай Сюэцзя (Lai Xuejia) и Юй Хунбо (Yu Hongbo) обнаружили уязвимости в алгоритме .
1 марта 2005 года Арьен Ленстра , Ван Сяоюнь и Бенне де Вегер продемонстрировали построение двух документов X.509 с различными открытыми ключами и одинаковым хешем MD5 .
18 марта 2006 года исследователь (Vlastimil Klima) опубликовал алгоритм, который может найти коллизии за одну минуту на обычном компьютере, метод получил название «туннелирование» .
В конце 2008 года US-CERT призвал разработчиков программного обеспечения, владельцев веб-сайтов и пользователей прекратить использовать MD5 в любых целях, так как исследования продемонстрировали ненадёжность этого алгоритма .
24 декабря 2010 года Тао Се (Tao Xie) и Фэн Дэнго (Feng Dengguo) впервые представили коллизию сообщений длиной в один блок (512 бит) . Ранее коллизии были найдены для сообщений длиной в два блока и более. Позднее Марк Стивенс (Marc Stevens) повторил успех, опубликовав блоки с одинаковым хешем MD5, а также алгоритм для получения таких коллизий .
В 2011 году был опубликован информационный документ . Он признаёт алгоритм хеширования MD5 небезопасным для некоторых целей и рекомендует отказаться от его использования в пользу SHA-2.

На вход алгоритма поступает входной поток данных, хеш которого необходимо найти. Длина сообщения измеряется в битах и может быть любой (в том числе нулевой). Запишем длину сообщения в L . Это число целое и неотрицательное. Кратность каким-либо числам необязательна. После поступления данных идёт процесс подготовки потока к вычислениям.
Ниже приведены 5 шагов алгоритма :
Сначала к концу потока дописывают единичный бит.
Затем добавляют некоторое число нулевых бит такое, чтобы новая длина потока стала сравнима с 448 по модулю 512, ( ). Выравнивание происходит в любом случае, даже если длина исходного потока уже сравнима с 448.
В конец сообщения дописывают 64-битное представление длины данных (количество бит в сообщении) до выравнивания. Сначала записывают младшие 4 байта, затем старшие. Если длина превосходит , то дописывают только младшие биты (эквивалентно взятию по модулю ). После этого длина потока станет кратной 512. Вычисления будут основываться на представлении этого потока данных в виде массива слов по 512 бит.
Для вычислений инициализируются четыре переменные размером по 32 бита, начальные значения которых задаются шестнадцатеричными числами (порядок байтов little-endian ):
А = 01 23 45 67; // 67452301h В = 89 AB CD EF; // EFCDAB89h С = FE DC BA 98; // 98BADCFEh D = 76 54 32 10. // 10325476h
В этих переменных будут храниться результаты промежуточных вычислений. Начальное состояние ABCD называется инициализирующим вектором.
Определим функции и константы, которые понадобятся нам для вычислений.
Заносим в блок данных элемент n из массива 512-битных блоков. Сохраняются значения A, B, C и D, оставшиеся после операций над предыдущими блоками (или их начальные значения, если блок первый).
Этап 1
/* [abcd k s i] a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */ [ABCD 0 7 1][DABC 1 12 2][CDAB 2 17 3][BCDA 3 22 4] [ABCD 4 7 5][DABC 5 12 6][CDAB 6 17 7][BCDA 7 22 8] [ABCD 8 7 9][DABC 9 12 10][CDAB 10 17 11][BCDA 11 22 12] [ABCD 12 7 13][DABC 13 12 14][CDAB 14 17 15][BCDA 15 22 16]
Этап 2
/* [abcd k s i] a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */ [ABCD 1 5 17][DABC 6 9 18][CDAB 11 14 19][BCDA 0 20 20] [ABCD 5 5 21][DABC 10 9 22][CDAB 15 14 23][BCDA 4 20 24] [ABCD 9 5 25][DABC 14 9 26][CDAB 3 14 27][BCDA 8 20 28] [ABCD 13 5 29][DABC 2 9 30][CDAB 7 14 31][BCDA 12 20 32]
Этап 3
/* [abcd k s i] a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */ [ABCD 5 4 33][DABC 8 11 34][CDAB 11 16 35][BCDA 14 23 36] [ABCD 1 4 37][DABC 4 11 38][CDAB 7 16 39][BCDA 10 23 40] [ABCD 13 4 41][DABC 0 11 42][CDAB 3 16 43][BCDA 6 23 44] [ABCD 9 4 45][DABC 12 11 46][CDAB 15 16 47][BCDA 2 23 48]
Этап 4
/* [abcd k s i] a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */ [ABCD 0 6 49][DABC 7 10 50][CDAB 14 15 51][BCDA 5 21 52] [ABCD 12 6 53][DABC 3 10 54][CDAB 10 15 55][BCDA 1 21 56] [ABCD 8 6 57][DABC 15 10 58][CDAB 6 15 59][BCDA 13 21 60] [ABCD 4 6 61][DABC 11 10 62][CDAB 2 15 63][BCDA 9 21 64]
Суммируем с результатом предыдущего цикла:
A = AA + A B = BB + B C = CC + C D = DD + D
После окончания цикла необходимо проверить, есть ли ещё блоки для вычислений. Если да, то переходим к следующему элементу массива ( n + 1) и повторяем цикл.
Результат вычислений находится в буфере ABCD, это и есть хеш. Если выводить побайтово, начиная с младшего байта A и заканчивая старшим байтом D, то мы получим MD5-хеш. 1, 0, 15, 34, 17, 18…
// Все переменные — 32-битные беззнаковые целые. Все сложения выполняются по модулю 2^32. var int s[64], K[64] var int i // s обозначает величины сдвигов для каждой операции: s[ 0..15] := { 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22 } s[16..31] := { 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20 } s[32..47] := { 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23 } s[48..63] := { 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21 } // Определяем таблицу констант следующим образом for i from 0 to 63 do K[i] := floor(2^32 × abs (sin(i + 1))) end for // (Или просто используем заранее подсчитанные значения): K[ 0.. 3] := { 0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee } K[ 4.. 7] := { 0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501 } K[ 8..11] := { 0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be } K[12..15] := { 0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821 } K[16..19] := { 0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa } K[20..23] := { 0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8 } K[24..27] := { 0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed } K[28..31] := { 0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a } K[32..35] := { 0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c } K[36..39] := { 0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70 } K[40..43] := { 0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05 } K[44..47] := { 0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665 } K[48..51] := { 0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039 } K[52..55] := { 0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1 } K[56..59] := { 0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1 } K[60..63] := { 0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391 } // Инициализация переменных: var int a0 := 0x67452301 // A var int b0 := 0xefcdab89 // B var int c0 := 0x98badcfe // C var int d0 := 0x10325476 // D // Подготовка: добавляем бит "1" в конец сообщения. append "1" bit to message // Заметка: входные байты представлены строкой из бит, // причем первый бит — старший (big-endian). // Подготовка: дописываем нулевые биты, пока длина сообщения не станет сравнима с 448 по модулю 512 append "0" bit until message length in bits ≡ 448 (mod 512) // Дописываем остаток от деления изначальной длины сообщения на 2^64 append original length in bits mod 2^64 to message // Разбиваем подготовленное сообщение на 512-битные "куски": for each 512-bit chunk of padded message do // и работаем с каждым по отдельности break chunk into sixteen 32-bit words M[j], 0 ≤ j ≤ 15 // разбиваем "кусок" на 16 блоков по 32 бита // Инициализируем переменные для текущего куска: var int A := a0 var int B := b0 var int C := c0 var int D := d0 // Основные операции: for i from 0 to 63 do var int F, g if 0 ≤ i ≤ 15 then F := (B and C) or ((not B) and D) g := i else if 16 ≤ i ≤ 31 then F := (D and B) or ((not D) and C) g := (5×i + 1) mod 16 else if 32 ≤ i ≤ 47 then F := B xor C xor D g := (3×i + 5) mod 16 else if 48 ≤ i ≤ 63 then F := C xor (B or (not D)) g := (7×i) mod 16 F := F + A + K[i] + M[g] // M[g] — 32 битный блок A := D D := C C := B B := B + (F <<< s[i]) // Выполняем битовый сдвиг end for // Прибавляем результат текущего "куска" к общему результату a0 := a0 + A b0 := b0 + B c0 := c0 + C d0 := d0 + D end for var char digest[16] := a0 append b0 append c0 append d0 // (Результат в формате little-endian)
Результат вычислений на примере языка программирования Python
import hashlib import math k:int r:int def left_rotate(n, b): return ((n << b) | (n >> (32 - b))) & 0xffffffff def md5(message): a0 = 0x67452301 b0 = 0xefcdab89 c0 = 0x98badcfe d0 = 0x10325476 ml = len(message) * 8 message = bytearray(message) message.append(0x80) while len(message) % 64 != 56: message.append(0) message += ml.to_bytes(8, byteorder='little') for i in range(0, len(message), 64): chunk = message[i:i+64] a = a0 b = b0 c = c0 d = d0 # Main loop for j in range(64): if 0 <= j <= 15: f = (b & c) | ((~b) & d) g = j elif 16 <= j <= 31: f = (d & b) | ((~d) & c) g = (5*j + 1) % 16 elif 32 <= j <= 47: f = b ^ c ^ d g = (3*j + 5) % 16 elif 48 <= j <= 63: f = c ^ (b | (~d)) g = (7*j) % 16 d_temp = d d = c c = b b = (b + left_rotate((a + f + k[j] + int.from_bytes(chunk[4*g:4*(g+1)], byteorder='little')), r[j])) & 0xffffffff a = d_temp a0 = (a0 + a) & 0xffffffff b0 = (b0 + b) & 0xffffffff c0 = (c0 + c) & 0xffffffff d0 = (d0 + d) & 0xffffffff return '{:08x}{:08x}{:08x}{:08x}'.format(a0, b0, c0, d0) # Пример использования: import hashlib message = "Hello, world!" result = hashlib.md5(message.encode()).hexdigest() print("MD5 хэш (hashlib):", result) def md5(message): # Constants T = [int(abs(math.sin(i+1)) * 2**32) & 0xFFFFFFFF for i in range(64)] s = [[7, 12, 17, 22]] * 4 + [[5, 9, 14, 20]] * 4 + [[4, 11, 16, 23]] * 4 + [[6, 10, 15, 21]] * 4 # Initialize variables A, B, C, D = 0x67452301, 0xEFCDAB89, 0x98BADCFE, 0x10325476 message = bytearray(message) length = (8 * len(message)) & 0xFFFFFFFFFFFFFFFF message.append(0x80) while len(message) % 64 != 56: message.append(0x00) message.extend(length.to_bytes(8, byteorder='little')) # Process message in 16-word blocks for i in range(0, len(message), 64): X = [int.from_bytes(message[i:i+4], byteorder='little') for i in range(i, i+64, 4)] A_, B_, C_, D_ = A, B, C, D # Main loop for j in range(64): if j < 16: F = (B & C) | ((~B) & D) F_index = j elif j < 32: F = (D & B) | ((~D) & C) F_index = (5 * j + 1) % 16 elif j < 48: F = B ^ C ^ D F_index = (3 * j + 5) % 16 else: F = C ^ (B | (~D)) F_index = (7 * j) % 16 dTemp = D D = C C = B B = B + left_rotate((A + F + T[j] + X[F_index]) & 0xFFFFFFFF, s[j % 4][j % 4]) A = dTemp # Update state A = (A + A_) & 0xFFFFFFFF B = (B + B_) & 0xFFFFFFFF C = (C + C_) & 0xFFFFFFFF D = (D + D_) & 0xFFFFFFFF # Output result = bytearray(A.to_bytes(4, byteorder='little')) result.extend(B.to_bytes(4, byteorder='little')) result.extend(C.to_bytes(4, byteorder='little')) result.extend(D.to_bytes(4, byteorder='little')) return result.hex() result = md5(message.encode()) print("MD5 хэш (самостоятельная реализация):", result)
Алгоритм MD5 происходит от MD4. В новый алгоритм добавили ещё один раунд, теперь их стало 4 вместо 3 в MD4. Добавили новую константу для того, чтобы свести к минимуму влияние входного сообщения, в каждом раунде на каждом шаге и каждый раз константа разная, она суммируется с результатом F и блоком данных. Изменилась функция вместо . Результат каждого шага складывается с результатом предыдущего шага, из-за этого происходит более быстрое изменение результата. Для этой же цели оптимизирована величина сдвига на каждом круге. Изменился порядок работы с входными словами в раундах 2 и 3 .
Хеш содержит 128 бит (16 байт) и обычно представляется как последовательность из 32 шестнадцатеричных цифр .
Несколько примеров хеша:
MD5("md5") = 1BC29B36F623BA82AAF6724FD3B16718
Даже небольшое изменение входного сообщения (в нашем случае на один бит: ASCII символ «5» с кодом 35 16 = 00011010 1 2 заменяется на символ «4» с кодом 34 16 = 00011010 0 2 ) приводит к полному изменению хеша. Такое свойство алгоритма называется лавинным эффектом .
MD5("md4") = C93D3BF7A7C4AFE94B64E30C2CE39F4F
Пример MD5-хеша для «нулевой» строки:
MD5("") = D41D8CD98F00B204E9800998ECF8427E
На данный момент существуют несколько видов «взлома» хешей MD5 — подбора сообщения с заданным хешем :
При этом методы перебора по словарю и brute-force могут использоваться для взлома хеша других хеш-функций (с небольшими изменениями алгоритма). В отличие от них, RainbowCrack требует предварительной подготовки радужных таблиц , которые создаются для заранее определённой хеш-функции. Поиск коллизий специфичен для каждого алгоритма.
Для полного перебора или перебора по словарю можно использовать программы PasswordsPro , , John the Ripper . Для перебора по словарю существуют готовые словари . Основным недостатком такого типа атак является высокая вычислительная сложность.
RainbowCrack — ещё один метод нахождения прообраза хеша из заданного множества. Он основан на генерации цепочек хешей, чтобы по получившейся базе вести поиск заданного хеша. Хотя создание радужных таблиц занимает много времени и памяти, последующий взлом производится очень быстро. Основная идея данного метода — достижение компромисса между временем поиска по таблице и занимаемой памятью .
Коллизия хеш-функции — это получение одинакового значения функции для разных сообщений и идентичного начального буфера. В отличие от коллизий, псевдоколлизии определяются как равные значения хеша для разных значений начального буфера, причём сами сообщения могут совпадать или различаться. В MD5 вопрос коллизий не решается .
В 1996 году нашёл псевдоколлизии в MD5, используя определённые инициализирующие векторы, отличные от стандартных. Оказалось, что можно для известного сообщения построить второе, такое, что оно будет иметь такой же хеш, как и исходное. C точки зрения математики это означает: MD5(IV,L1) = MD5(IV,L2), где IV — начальное значение буфера, а L1 и L2 — различные сообщения. Например, если взять начальное значение буфера :
A = 0x12AC2375 В = 0x3B341042 C = 0x5F62B97C D = 0x4BA763E
и задать входное сообщение
| AA1DDABE | D97ABFF5 | BBF0E1C1 | 32774244 |
| 1006363E | 7218209D | E01C136D | 9DA64D0E |
| 98A1FB19 | 1FAE44B0 | 236BB992 | 6B7A779B |
| 1326ED65 | D93E0972 | D458C868 | 6B72746A |
то, добавляя число к определённому 32-разрядному слову в блочном буфере, можно получить второе сообщение с таким же хешем. Ханс Доббертин представил такую формулу:
Тогда MD5(IV, L1) = MD5(IV, L2) = BF90E670752AF92B9CE4E3E1B12CF8DE.
В 2004 году китайские исследователи Ван Сяоюнь (Wang Xiaoyun), Фэн Дэнго (Feng Dengguo), Лай Сюэцзя (Lai Xuejia) и Юй Хунбо (Yu Hongbo) объявили об обнаруженной ими уязвимости в алгоритме, позволяющей за небольшое время (1 час на кластере IBM p690 ) находить коллизии .
В 2005 году Ван Сяоюнь и Юй Хунбо из университета Шаньдуна в Китае опубликовали алгоритм, который может найти две различные последовательности в 128 байт, которые дают одинаковый MD5-хеш. Одна из таких пар (различающиеся разряды выделены):
| d131dd02c5e6eec4693d9a0698aff95c | 2fcab5 8 712467eab4004583eb8fb7f89 |
| 55ad340609f4b30283e4888325 7 1415a | 085125e8f7cdc99fd91dbd f 280373c5b |
| d8823e3156348f5bae6dacd436c919c6 | dd53e2 b 487da03fd02396306d248cda0 |
| e99f33420f577ee8ce54b67080 a 80d1e | c69821bcb6a8839396f965 2 b6ff72a70 |
и
| d131dd02c5e6eec4693d9a0698aff95c | 2fcab5 0 712467eab4004583eb8fb7f89 |
| 55ad340609f4b30283e4888325 f 1415a | 085125e8f7cdc99fd91dbd 7 280373c5b |
| d8823e3156348f5bae6dacd436c919c6 | dd53e2 3 487da03fd02396306d248cda0 |
| e99f33420f577ee8ce54b67080 2 80d1e | c69821bcb6a8839396f965 a b6ff72a70 |
Каждый из этих блоков даёт MD5-хеш, равный 79054025255fb1a26e4bc422aef54eb4 .
В 2006 году чешский исследователь Властимил Клима опубликовал алгоритм, позволяющий находить коллизии на обычном компьютере с любым начальным вектором (A,B,C,D) при помощи метода, названного им « » .
Алгоритм MD5 использует итерационный метод Меркла — Дамгора , поэтому становится возможным построение коллизий с одинаковым, заранее выбранным префиксом. Аналогично, коллизии получаются при добавлении одинакового суффикса к двум различным префиксам, имеющим одинаковый хеш. В 2009 году было показано, что для любых двух заранее выбранных префиксов можно найти специальные суффиксы, с которыми сообщения будут иметь одинаковое значение хеша. Сложность такой атаки составляет всего 2 39 операций подсчёта хеша .
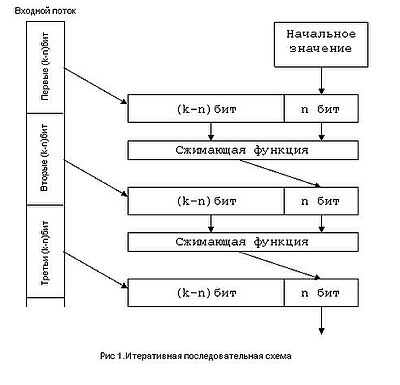
Метод и использует тот факт, что MD5 построен на итерационном методе Меркла — Дамгора. Поданный на вход файл сначала дополняется, так чтобы его длина была кратна 64 байтам, после этого он делится на блоки по 64 байта каждый , , , . Далее вычисляется последовательность 16-байтных состояний , , по правилу , где — некоторая фиксированная функция. Начальное состояние называется инициализирующим вектором .
Метод позволяет для заданного инициализирующего вектора найти две пары и , такие что . Этот метод работает для любого инициализирующего вектора, а не только для вектора используемого по стандарту.
Эта атака является разновидностью дифференциальной атаки, которая, в отличие от других атак этого типа, использует целочисленное вычитание, а не XOR в качестве меры разности. При поиске коллизий используется метод модификации сообщений: сначала выбирается произвольное сообщение , далее оно модифицируется по некоторым правилам, сформулированным в статье, после чего вычисляется дифференциал хеш-функции, причём с вероятностью . К и применяется функция сжатия для проверки условий коллизии; далее выбирается произвольное , модифицируется, вычисляется новый дифференциал, равный нулю с вероятностью , а равенство нулю дифференциала хеш-функции как раз означает наличие коллизии. Оказалось, что найдя одну пару и , можно менять лишь два последних слова в , тогда для нахождения новой пары и требуется всего около операций хеширования .
Применение этой атаки к MD4 позволяет найти коллизию меньше чем за секунду. Она также применима к другим хеш-функциям, таким как RIPEMD и HAVAL .
Ранее считалось, что MD5 позволяет получать относительно надёжный идентификатор для блока данных. На данный момент данная хеш-функция не рекомендуется к использованию, так как существуют способы нахождения коллизий с приемлемой вычислительной сложностью .
Свойство уникальности хеша широко применяется в разных областях . Приведенные примеры относятся и к другим криптографическим хеш-функциям .
С помощью MD5 проверяли целостность и подлинность скачанных файлов — так, некоторые программы поставляются вместе со значением контрольной суммы . Например, пакеты для инсталляции свободного ПО .
MD5 использовался для хеширования паролей. В системе UNIX каждый пользователь имеет свой пароль и его знает только пользователь. Для защиты паролей используется хеширование. Предполагалось, что получить настоящий пароль можно только полным перебором. При появлении UNIX единственным способом хеширования был DES (Data Encryption Standard), но им могли пользоваться только жители США , потому что исходные коды DES нельзя было вывозить из страны. Во FreeBSD решили эту проблему. Пользователи США могли использовать библиотеку DES , а остальные пользователи имеют метод, разрешённый для экспорта. Поэтому в FreeBSD стали использовать MD5 по умолчанию. . Некоторые Linux -системы также используют MD5 для хранения паролей .
Многие системы используют базы данных для аутентификации пользователей и существует несколько способов хранения паролей :
Существует несколько надстроек над MD5.