Сетевая модель OSI
- 1 year ago
- 0
- 0

Существуют два класса систем связи: цифровые и аналоговые . Цифровой сигнал — это сигнал, имеющий конечное число дискретных уровней. Аналоговые сигналы являются непрерывными. Типичным примером такого сигнала является речевой сигнал, передаваемый по обычному телефону. Информацию, передаваемую аналоговыми сигналами, также необходимо защищать, в том числе и криптографическими методами.
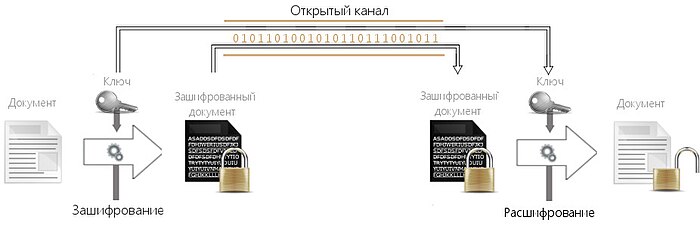
Имеются два различных способа шифрования речевого сигнала. Первый состоит в перемешивании ( скремблировании ) сигнала некоторым образом. Это делается путём изменения соотношений между временем, амплитудой и частотой, не выводящих за пределы используемого диапазона. Второй способ состоит в преобразовании сигнала в цифровую форму, к которой применимы обычные методы дискретного шифрования. Зашифрованное сообщение далее передается по каналу с помощью модема. После расшифрования полученной криптограммы вновь восстанавливается аналоговая форма сигнала.
Прежде чем перейти к деталям, необходимо остановиться на некоторых особенностях речевых сигналов.
Непрерывные сигналы характеризуются своим спектром.
Спектр сигнала
— это эквивалентный ему набор синусоидальных составляющих (называемых также
гармониками
или
частотными составляющими
). Спектр сигнала получается разложением функции, выражающей зависимость формы сигнала от времени, в
ряд Фурье
. Спектр периодического сигнала — линейчатый (дискретный), он состоит из гармоник с
кратными частотами. Спектр непериодического сигнала — непрерывный. Типичный спектр речевого сигнала показан на рис. 1.

Рис. 1
Частотные составляющие в диапазонах 3-4 кГц и менее 300 Гц быстро убывают. Таким образом, очень высокие частотные компоненты имеют существенно меньший вклад в сигнал, чем частоты в диапазоне 500-3000 Гц.
Если ограничиться частотами, не превышающими 3 кГц, и использовать высокочувствительный анализатор, то спектр, производимый некоторыми звуками, имеет вид зубчатой кривой приблизительно следующего вида (см. рис. 2).

Рис. 2
Мы видим несколько пиков графика, называемых формантами . Изменение этих частотных компонент во времени можно изобразить на трехмерном графике (при добавлении третьей координаты — времени).
Речевой сигнал является переносчиком смысловой информации. Эта информация при прослушивании речевого сигнала может быть записана в виде текста сообщения. Слуховое восприятие речевого сигнала более богато и несет как основную текстовую информацию, так и дополнительную в виде ударений и интонаций. Элементарными единицами слуховой информации являются элементарные звуки — фонемы , а смысловыми единицами — звучащие слоги, слова и фразы. Для каждого языка имеется свой набор фонем. Например, в русском и английском языках имеется около 40 фонем.
Множество фонем разбивается на три класса. Гласные образуют одно семейство, согласные и некоторые другие фонетические звуки (для английского языка — это, например, звуки ch , sh ) образуют два класса, называемые взрывными звуками и фрикативными звуками. Гласные производятся движением голосовых связок под воздействием потоков воздуха. Проходя через гортань, они превращаются в серию вибраций. Затем воздушный поток проходит через некоторое число резонаторов, главными из которых являются нос, рот и горло, превращаясь в воспринимаемые человеческим ухом фонемы. Возникающие звуки зависят от формы и размеров этих резонаторов, но в значительной степени они характеризуются низкочастотными составляющими.
Гласные звуки производятся в течение длительного времени. Как правило, требуется около 100 мс для достижения его пиковой амплитуды. Взрывные звуки производятся путём «перекрытия» воздушного потока с последующим его выпусканием с взрывным эффектом. Блокирование воздушного потока может осуществляться различными способами — языком, нёбом или губами. Например, звук «п» произносится при блокировании воздушного потока губами. Взрывные звуки характеризуются их высокочастотными составляющими. До 90 % их пиков амплитуды имеют длительность, не превышающую 5 мсек . Фрикативные звуки производятся частичным перекрытием воздушного потока, что дает звук, похожий на «белый шум». Этот звук затем фильтруется резонаторами голосового тракта. Фрикативный звук обычно богат пиками амплитуды длительностью 20-50 мс и сконцентрирован по частоте от 1 до 3 кГц. Пример фрикатива — звук «ссс…»
Другой важной характеристикой человеческой речи является частота основного тона . Это — частота вибраций голосовых связок. Среднее значение этой частоты колеблется у разных людей, и у каждого говорящего имеется отклонение и пределах октавы выше или ниже этой центральной частоты. Обычно у мужчины частота основного тона колеблется около 130 Гц, у женщины она выше.
Речевые сигналы не только передают информацию, но и дают сведения о голосовых характеристиках говорящего, что позволяет идентифицировать его по голосу. Можно использовать высоту, форманты, временную диаграмму и другие характеристики речевого сигнала, чтобы попытаться сформировать сигнал, схожий с оригиналом. Это воспроизведение может быть в некоторой степени неестественным и некоторые индивидуальные характеристики говорящего будут утеряны. Такие принципы репродукции лежат в основе вокодера , о котором будет сказано далее.
Рассмотрим сначала первый способ шифрования речевых сигналов в их аналоговой форме. При оценке стойкости шифрования речевых сигналов в аналоговой форме необходимо, в первую очередь, учитывать возможности человеческого восприятия при прослушивании результирующего сигнала и попытке восстановить какую-либо информацию. Это восприятие очень субъективно: одни люди воспринимают на слух значительно лучше других. Например, хорошо известно, что родители понимают «речь» своих детей задолго до того, как её начинают понимать другие люди. В связи с этим говорят о так называемой .
Оценивая надежность шифрования целесообразно несколько раз подряд прослушать скремблированные телефонные сообщения. Дело в том, что человеческий мозг способен адаптироваться к «добыванию» информации и быстро анализировать услышанное. Часто бывает так, что после второго или третьего прослушивания человек начинает распознавать отдельные слова или слоги. Возможно, что смесь различных фрагментов приведет к пониманию смысла сообщения. Имеются даже эксперты для восприятия скремблированных сообщений. Простейшей формой рассматриваемых преобразований являются преобразования сигнала в частотной области: инверсии , и .
Простейшим является преобразование инверсии спектра. Оно осуществляется следующим образом. Рассмотрим, например, сигнал, расположенный в диапазоне 300-3000 Гц (см. рис. 3).

Рис. 3
Попытаемся преобразовать сигнал таким образом, чтобы поменялись местами высокие и низкие частоты. Для этого рассмотрим отдельные гармоники нашего сигнала. Если
— одна из гармоник, подаваемая вместе с сигналом
на вход устройства, называемого
смесителем
, то его выходом будет сигнал
.
Согласно известному равенству
Величины
и
можно выбирать. Положив
и
, мы получим следующий амплитудно-угловой спектр выхода смесителя (см. рис. 4).

Рис. 4
При рассмотрении каждой гармоники сигнала и соответствующего выхода смесителя получим следующий график (см. рис. 5).

Рис. 5
Между несущей частотой
находятся два диапазона, называемые
верхним
и
нижним диапазонами
соответственно. Верхний диапазон аналогичен исходному сигналу, лишь перемещенному вверх (каждая частотная компонента увеличивается на
). Нижний диапазон является зеркальным отражением исходного сигнала. Теперь, выбирая подходящую несущую частоту и используя смеситель для перемещения верхнего диапазона, мы можем получить инвертированный речевой сигнал (см. рис. 6).

Рис. 6
Выбором несущей частоты для различных сигналов каждый из них может быть перенесен в другой частотный диапазон. Это дает возможность передавать несколько телефонных сигналов по одному каналу.
Преобразование инверсии не зависит от секретного ключа. Это — кодирование, являющееся нестойким против атак противника, обладающего аналогичным оборудованием. Развитие идеи инверсного кода, позволяющее ввести секретный ключ, состоит в использовании так называемой циклической инверсии. Суть преобразования циклической инверсии заключается в следующем.
Как мы уже заметили, если инвертированный сигнал находится в том же диапазоне, что и исходный сигнал (300 — 3000 Гц), то несущая частота равна 3300 Гц. Для другой несущей частоты, скажем 4000 Гц, получим инвертированный сигнал со спектром, изображенным на рис. 7

Рис. 7
Этот сигнал не попадает в исходную полосу. Можно договориться переносить часть спектра, превышающую 3000 Гц, в нижнюю часть исходного спектра (см. рис. 8).

Рис. 8
В таком переносе части спектра и заключается идея циклической инверсии. Типичный инвертор имеет от 4 до 16 различных несущих частот. Это дает такое же число возможных циклических сдвигов. С помощью ключа можно выбирать несущую частоту так, как это делается для шифра простой замены. Можно использовать также генератор псевдослучайных чисел , который выбирает изменяемую несущую частоту. Обычно для этого используют интервал в 10 или 20 мс. Реализующее такой метод устройство называют .
Подобные системы имеют две серьёзные слабости. Во-первых, в каждый момент времени имеется лишь небольшое число возможных несущих частот, в силу чего исходный сигнал может быть восстановлен их перебором с помощью сравнительно простого оборудования. Во-вторых, что более важно, остаточная разборчивость выходного сигнала для такого метода неприемлемо высока, что проявляется при непосредственном прослушивании. Третий способ изменения сигнала в частотной области состоит в делении диапазона. Спектр сигнала делится на некоторое число равных поддиапазонов, которые могут переставляться местами друг с другом. К этому можно добавить также возможность инвертирования для некоторых поддиапазонов. Эту идею проиллюстрируем следующим примером.
Рассмотрим сигнал, изображенный на рис. 9. В нашем примере частотный диапазон разбит на пять равных частей, которые переставляются в соответствии с указанной нумерацией, при этом первая и пятая части инвертированы (см. рис. 10).
Всего в нашем примере имеется 5! возможных перестановок и
возможностей для инвертирования. Итого —
вариантов преобразований сигнала. Это, конечно, не очень много. Хуже обстоит дело с остаточной разборчивостью. Если использовать лишь перестановки полос, то для большинства из них остаточная разборчивость достигает 10 %, что, конечно, не дает гарантии стойкости.

Рис. 9

Рис. 10
Некоторые причины этого легко понять. Так будет, например, если некоторые поддиапазоны остаются неизменными. Кроме того, известно, что обычно более 40 % энергии сигнала лежит в первых двух поддиапазонах, соответствующих первой форманте. Как только криптоаналитик найдет правильные позиции первых двух поддиапазонов и переместит их на нужные места, он частично восстановит сигнал и получит неплохой шанс понять фрагмент сообщения.
Можно попытаться улучшить систему защиты за счет использования некоторого числа различных перестановок, которые меняются через короткие промежутки времени с помощью генератора псевдослучайных чисел . Часто для реальных систем лучшие (с точки зрения низкой остаточной разборчивости) перестановки хранятся в ROM (памяти только для чтения), имеющейся внутри устройства.
Несмотря на то, что генератор может вырабатывать последовательность очень большого периода, и размер ключа может быть выбран достаточно большим, даже в этом случае остаточная разборчивость большой доли преобразований так велика, что система не может в полной мере обеспечить необходимую надежность защиты.
То же можно сказать вообще о любом скремблере, использующем лишь действия с частотной областью. Их применение ограничивается лишь ситуациями, когда целью является препятствие пониманию разговора для случайного слушателя или даже противника, не обладающего подходящим оборудованием. Как будет видно из дальнейшего, более совершенные системы или увеличивают ширину спектра сигнала, или вводят временные задержки в передачу. Подобные изменения влекут свои собственные проблемы и поэтому частотные скремблеры могут быть использованы только тогда, когда не требуется гарантированная стойкость.
К сказанному следует добавить замечание о числе поддиапазонов, используемых частотным скремблером. В предыдущем примере их было пять. Ясно, что с ростом этого числа значительно увеличилось бы число возможных перестановок, что привело бы к возрастанию стойкости системы. Однако введение слишком большого числа поддиапазонов связано с большими практическими трудностями. Дело в том, что на приеме необходимо восстановить исходный сигнал. Фильтры же и другие компоненты схемы вносят шумы и не являются в точности линейными системами. Любые преобразования сигнала, производимые при передаче, являются несовершенными и приводят к ухудшению его качества на выходе. Скремблеры особенно чувствительны к подобным искажениям. Поэтому увеличение числа поддиапазонов делает систему или вообще непригодной, или неэкономичной.
Рассмотрим теперь скремблеры, воздействующие на временные компоненты сигнала. В их основе лежат следующие принципы.
Сначала аналоговый сигнал делится на равные промежутки времени, называемые кадрами . Каждый кадр, в свою очередь, также делится на ещё меньшие части, называемые сегментами . Входной сигнал преобразуется путём перестановки сегментов внутри каждого кадра. Для этого речевой сигнал на передающем конце записывается на магнитофонную ленту, которая «разрезается» на равные части, пронумерованные по порядку. Затем они перемешиваются и «склеиваются» в некотором другом порядке. Воспроизведенный со склеенной ленты сигнал передается по каналу связи и на приемном конце снова записывается на магнитофонную ленту, которая, в свою очередь, разрезается на те же части, как и при передаче. Части «склеиваются» в порядке возрастания номеров и сигнал восстанавливается.
Проиллюстрируем этот процесс следующим примером.
На рис. 11 кадр разделен на 8 сегментов. Затем сегменты переставляются в соответствии с перестановкой
При настройке системы необходимо выбрать длины кадров и сегментов. Так как внутри сегмента сигнал не разрушается, то сегменты желательно выбирать настолько короткими, чтобы в них не содержались целые фрагменты сообщения, например отдельные слова. С другой стороны, длина сегмента серьёзно влияет на качество звучания передаваемого сигнала, что объясняется чисто техническими причинами. Чем меньше сегмент, тем ниже качество звучания. Поэтому в выборе длины сегмента необходим разумный компромисс.

Рис. 11
При выборе длины кадра необходимо учитывать фактор временной задержки между входным аналоговым сигналом, поступающим в аппаратуру, и восстановленным аналоговым сигналом на приеме. Для того чтобы разобраться в этом, вернемся к последнему примеру (см. рис. 10).
Пусть сегмент составляет в нашем примере интервал времени в
T
с. Тогда ввод восьми речевых сегментов на вход скремблера занимает 8
T
с. Перестановка сегментов могла быть такой, что восьмой сегмент оказался бы первым (то есть подлежащим передаче по каналу связи в первую очередь). В таком случае передача не может начаться прежде, чем в скремблер не будет введен весь кадр. Для этого потребуется 8
T
с. С начала передачи кадра до её окончания требуется еще 8
T
с. Поэтому временная задержка неизбежна. Получатель не может начать расшифрование до получения всего кадра. Таким образом, даже если не учитывать время передачи, задержка составляет 16
T
с на каждый сегмент речи. В общем случае для системы, оперирующей с
m
сегментами на кадр, время задержки может составлять 2
mT
с. С точки зрения пользователя это нежелательно, и подобная задержка должна быть минимизирована. Однако для повышения надежности засекречивания желательны достаточно длинные кадры. Для того чтобы убедиться в этом, заметим следующее.
При обсуждении свойств фонем мы могли заметить, что свойства речевого звука сохраняются в течение достаточно большого интервала времени (структура формант медленно изменяется). Если кадр настолько мал, что он состоит из единственного тона, то независимо от того, как мы его будем скремблировать, результатом будет являться единственный непрерывный тон (с определенной потерей качества звука в результате нашего вмешательства). Нам не удастся добиться достаточного рассеивания сегментов в связи с их небольшим числом. Это может привести к тому, что значительные части слов окажутся неизменными, что позволит слушателю распознать часть сообщения.
Нет также очевидного способа выбора длины сегментов. На практике необходимо экспериментально проверять любой выбор длины сегмента. Обычно неплохим тестом для этого служит попытка воспроизвести на слух результат скремблирования произнесенных в произвольном порядке чисел от 1 до 10. Ясно, что эта задача значительно проще той, когда требуется узнать сообщение, о котором ничего не известно. Эксперименты показывают, что если длина кадра недостаточно велика, то рассматриваемые системы плохо выдерживают такой тест. В большинстве случаев в аппаратуре данного типа кадры делятся на число сегментов, заключенное в пределах от 8 до 16 причем обычно длительность каждого сегмента составляет от 20 до 60 мс.
Помимо выбора длин кадров и сегментов важным параметром является перестановка. Очевидно, что одни перестановки лучше других, и необходимо определить, как их следует выбирать и как управлять их выбором. Как и для преобразований инвертирования и частотных перестановок, имеется несколько вариантов использования базовой системы. Можно выбрать одну фиксированную перестановку для преобразования каждого кадра. Другой вариант связан с выбором (при помощи ключа) нескольких перестановок и периодическим их использованием. Лучшим способом является использование псевдослучайного генератора для выбора перестановки, применяемой для преобразования каждого кадра в отдельности. Для такого варианта актуален вопрос о длине периода соответствующей последовательности перестановок, так как повторное использование одной и той же перестановки нежелательно. В свою очередь, с этим связан выбор числа сегментов в кадре. Например, если это число равно 8 и каждый сегмент имеет длительность в 40 мс, то через 3,6 час. непрерывной работы перестановки начнут повторяться.
Как мы уже отмечали, далеко не все перестановки являются «хорошими» с точки зрения надежности шифрования. Например, если прослушать сигнал после применения каждой из двух подстановок
, , (1)
то мы нашли бы в первом случае значительно более высокую остаточную разборчивость, чем во втором.
Замечание . В (1) рассматриваемые перестановки являются нижними строками подстановок, в которых верхние строки представляют собой исходные порядки сегментов, а нижние — порядки сегментов после перестановки.
Причина указанного различия перестановок (1) состоит в том, что в первой из них символы 1, 4, 5, 8 остаются неподвижными, а остальные смещаются лишь на соседние позиции, тогда как во второй происходит лучшее перемешивание.
Рассмотренный пример приводит к естественной количественной мере «качества» перестановки. Пусть для произвольной подстановки α символ α(i) обозначает позицию, на которую α перемещает i -й сегмент. Тогда смещение символа i после перестановки равно , а среднее смещение после перестановки характеризуется величиной
Для первой подстановки из (1) среднее смещение s(α) равно 0,5, для второй — 2,5. Величина s(α) называется сдвиговым фактором подстановки α . Замечено, что перестановки, приводящие к выходному сигналу с низкой остаточной разборчивостью, имеют большой сдвиговый фактор, хотя обратное может быть неверным. В качестве примера приведем подстановку α восьми элементов со сдвиговым фактором 4, которая плохо выдерживает «тесты на слух»:
. (2)
Помимо своего низкого сдвигового фактора первая подстановка в (1) имеет и другие нежелательные свойства. Рассмотрим, например, соседние сегменты 4 и 5. В скремблированном кадре они расположены в том же порядке, что и в исходном. Если сегменты имеют длительность в 40 мс, то рассматриваемая пара сегментов составляет около 80 мс. Как мы уже отмечали, большинство фонем могут быть узнаваемы в таком интервале времени. В той же подстановке, а также в подстановке (2), сегменты 6 и 8 являются соседними. Это также нежелательно. Дело в том, что вообще при прослушивании в скремблированном сигнале пары соседних сегментов типа i, i + 2 человеческий мозг в состоянии, как правило, восстановить пропущенный сегмент i + 1 , то есть восстановить соответствующую часть сообщения. Нечто подобное имеет место и в других случаях.
Таким образом, в рассмотренных ситуациях также идет речь о некоторой остаточной разборчивости. Это свидетельствует о сложности формализации определения «хороших» с точки зрения защиты перестановок, а следовательно, и сложности их подсчета. Поэтому имеются существенные различия в подсчете числа «хороших» перестановок, это может зависеть от субъективных предпочтений разработчика.
Теперь нужно решить вопрос о способе выбора перестановок с помощью ключа. Имеются два естественных способа такого выбора. Первый состоит в выборе произвольной перестановки данной степени с последующим её тестированием. В зависимости от того, подходит она или нет, перестановка используется для преобразования кадра. Другой способ состоит в предварительном отборе всех «хороших» перестановок в ROM (памяти лишь для чтения), имеющейся в самом оборудовании, и их выбором для использования с помощью псевдослучайной последоват ельности. Рассмотрим оба способа.
Наиболее неблагоприятным для первого способа является фактор времени. В конце промежутка времени, равного длительности кадра, мы должны выбрать следующую подходящую перестановку. При этом нежелательно повторение той же перестановки, что в принципе возможно даже для случайной управляющей последовательности. Поэтому необходим контроль, устраняющий появление неподходящих перестановок. Ожидание подходящей перестановки требует дополнительных временных затрат, что нежелательно.
Второй метод использует лишь те перестановки, которые записаны в ROM. Если их запас не слишком велик, то это улучшает шансы противника. В случае когда кадр состоит из не слишком большого числа сегментов, скажем 8, и имеется возможность хранить все «хорошие» перестановки, второй метод предпочтителен. Чтобы понять ещё одно преимущество второго метода, необходимо рассмотреть вопрос о возможностях перехватчика, обладающего той же аппаратурой и полным набором «хороших» перестановок.
Предположим, что одной из перестановок, хранящихся в ROM, является вторая перестановка из (1), и мы её использовали для перемешивания кадра. Перехватчик, желая определить используемую перестановку, может перебирать перестановки, обратные к хранимому запасу перестановок. Если наша память содержит также нижнюю строку подстановки
, (3)
то перехватчик может опробовать и её (вместо использованной). Результатом последовательного применения исходной подстановки и обратной к подстановке (3) является подстановка
.
Она так близка к тождественной подстановке, что практически всегда дает возможность противнику восстановить исходный кадр. Помимо (3) есть и другие перестановки, «близкие» к истинной. В случае когда кадр состоит из 8 сегментов, таких пар «близких» перестановок имеется достаточно много и ситуация достаточно опасна (с точки зрения защиты). Дело в том, что мы должны скорректировать определение «хорошей» перестановки и тем самым уменьшить их число в памяти. Надо избегать записывать в память пары перестановок, соответствующих подстановкам и , для которых произведение или близко к тождественной подстановке. Если ROM заполняется с учетом сделанной коррекции и число хранимых перестановок достаточно велико, то второй метод их выбора для перемешивания кадров становится более предпочтительным.
Рассмотрим сначала вопрос о возможности восстановления информации, содержащейся в скремблированном сигнале, путём непосредственного прослушивания. С точки зрения разработчика необходимо найти баланс между минимальной остаточной разборчивостью и минимальной временной задержкой.
Для уменьшения остаточной разборчивости имеется ряд способов. Один из них состоит в простом реверсировании порядка следования сегментов. Наблюдения показывают, что при использовании такого способа уровень успешного прослушивания уменьшается почти на 10 %. Другой метод также имеет отношение к частотной области. Здесь имеется в виду совместное использование частотного и временного перемешивания в одной двумерной системе. Хотя такой метод уменьшает уровень успешного прослушивания почти на 20 %, он более дорог в реализации. Отметим при этом, что любые изменения сигнала уменьшают качество воспроизведения и что частотные искажения, в частности, сильно зависят от шумов и нелинейности при передаче.
Используя подобные методы или их комбинацию, можно уменьшить остаточную разборчивость до такого уровня, что будет невозможно воспринимать на слух никакое сообщение. Теперь рассмотрим вопрос о стойкости системы против более изощренных атак.
Одна из них состоит в попытках переупорядочить речевой сигнал кадр за кадром. Эта задача решается с использованием прибора, называемого сонографом . Этот прибор воспроизводит сонограмму каждого кадра. Сонограмма — это трехмерный график в системе координат время (по горизонтали), частота (по вертикали), амплитуда (по третьей координате), использующий «серую шкалу». В этой шкале чёрный цвет представляет максимальную амплитуду и белый цвет — минимальную. Изменения амплитуды представляются изменениями оттенком серого цвета. Светлее оттенок, соответствующий меньшей амплитуде. Таким образом, хотя сонограмма имеет три измерения, она обычно представляется в двумерном виде.
Дескремблирование некоторого числа кадров путём опробования содержания ROM может позволить определить часть псевдослучайной последовательности, достаточной для определения ключа. Для противодействия этому необходим соответствующий генератор псевдослучайной последовательности, стойкий к подобной угрозе.
Предположим, что наша система стойка к описанному подходу. Это означает, что единственный путь, при котором криптоаналитик может получить сообщение, состоит в дескремблировании каждого кадра. Но тогда, очевидно, время, необходимое для восстановления сообщения, прямо пропорционально числу кадров. Криптоаналитик может автоматизировать процесс перебора перестановок, содержащихся в ROM, для проверки критерия того, что полученный сигнал является речевым сигналом (это можно сделать, например, по сонограмме ). Для защиты от этой возможности вновь встает вопрос об увеличении числа «хороших» перестановок, что требует увеличения длительности кадра и временной задержки при передаче.
Как мы убедились ранее, временная задержка при передаче преобразованного кадра может быть в два раза больше длительности самого кадра. Это является следствием того, что для некоторых перестановок сегмент мог быть задержан на полную длительность кадра. С целью уменьшения подобной задержки можно ещё более ограничить множество используемых перестановок, добиваясь того, чтобы каждый сегмент задерживался «не слишком долго». Это достигается при использовании перестановок с относительно небольшими смещениями для каждого символа.
Подытожим рассмотрение скремблеров.
Скремблеры характеризуются аналоговым выходом, лежащим в том же диапазоне, что и исходный сигнал. Кроме того, они обычно имеют характерные спектральные характеристики и выходной сигнал, представляющий собой последовательность фонем открытой речи (с измененным порядком следования). Их стойкость зависит как от типа скремблирования, так и от способа его реализации. В частности, использование зависящего от ключа псевдослучайного генератора для скремблирования может значительно увеличить уровень стойкости. Надежность любого выбранного метода скремблирования зависит в значительной степени от типа и качества канала связи. Скремблеры варьируются от простейших инверторов до сложных относительно высокой стойкости. Обычно они применяются как системы шифрования временной стойкости.
Для преобразования речевого сигнала в цифровую форму берутся отсчеты , то есть значения сигнала через равные промежутки времени τ. Интервал τ должен быть настолько мал, чтобы сигнал не успевал намного измениться между отсчетами. Этот интервал часто называют или . Минимальную частоту взятия отсчетов, то есть величину, обратную временному шагу дискретизации, определяет теорема В. Л. Котельникова , согласно которой частота отсчетов должна быть вдвое больше максимальной частоты звукового спектра. В телефонии такая частота ограничивается 3,4 кГц. Поэтому частота отсчетов должна быть не менее 6800 в секунду, или 6,8 кГц. Процесс взятия отсчетов называют .
Для цифровой оценки отсчетов используется процесс . Каждый отсчет можно представить числом, соответствующим значению отсчета звукового напряжения. Например, если звуковое напряжение измерять в милливольтах, то число целых милливольт и будет отсчетом, а 1 мВ — шагом дискретизации по уровню. Отношение максимальной амплитуды звукового напряжения к шагу квантования дает максимальное число, которое нужно получить при отсчетах. Оно определяет динамический диапазон передаваемого сигнала. Для передачи речи с удовлетворительным качеством достаточен динамический диапазон 30-35 дб, что соответствует числу шагов квантования 30 при отсчетах. Для передачи одного отсчета двоичным кодом в этом случае достаточно разрядов. Для качественной передачи музыки число квантований должно быть не менее 10000, что соответствует динамическому диапазону 80 дб. В этом случае для передачи одного отсчета потребуется разрядов.
Переход на цифровую передачу существенно улучшает качество связи. Но не даром. Оценим поток информации при телефонном разговоре.
Полагая полосу звуковых частот равной, как и выше, 3,4 кГц и частоту взятия отсчетов 6,8 кГц, получаем 6800 отсчетов в секунду. При 30 шагах квантования по уровню каждый отсчет занимает 5 разрядов. Следовательно, в секунду передается 34000 двоичных разрядов, или бит информации. Скорость передачи информации, измеренную в бит/с, можно выразить формулой , где F — максимальная частота звукового спектра, N — число уровней квантования. Чтобы передать цифровой сигнал со скоростью 34 Кбит/с, нужна полоса частот, пропускаемых каналом связи, не менее 34 кГц.
Таким образом, при переходе к цифровому сигналу произошёл как бы обмен полосы частот на отношение сигнал/шум , но обмен достаточно выгодный. Расширяя полосу частот в 10 раз при переходе к цифровой передаче, мы намного снижаем допустимое отношение сигнал/шум или сигнал/помеха в канале связи, и это при общем существенном улучшении качества передачи.
В заключение сделаем одно замечание. Для аналогово-цифровых преобразователей входной сигнал отсчитывается через регулярные интервалы времени и затем передается цифровая «аппроксимация». Имеется и другой способ передачи информации. Если, например, входным сигналом является синусоида с частотой f , то вместо того, чтобы посылать цифровую аппроксимацию, мы могли бы просто сообщить получателю о параметрах синусоиды и предложить ему самому построить такой сигнал. Этот принцип заложен в основе аппаратов, называемых соответственно вокодерами и . С помощью таких аппаратов синтезируются цифровые речевые системы с низкоскоростным выходом (1,2 — 4,8 Кбит/с).
|
|
Для улучшения этой статьи
желательно
:
|