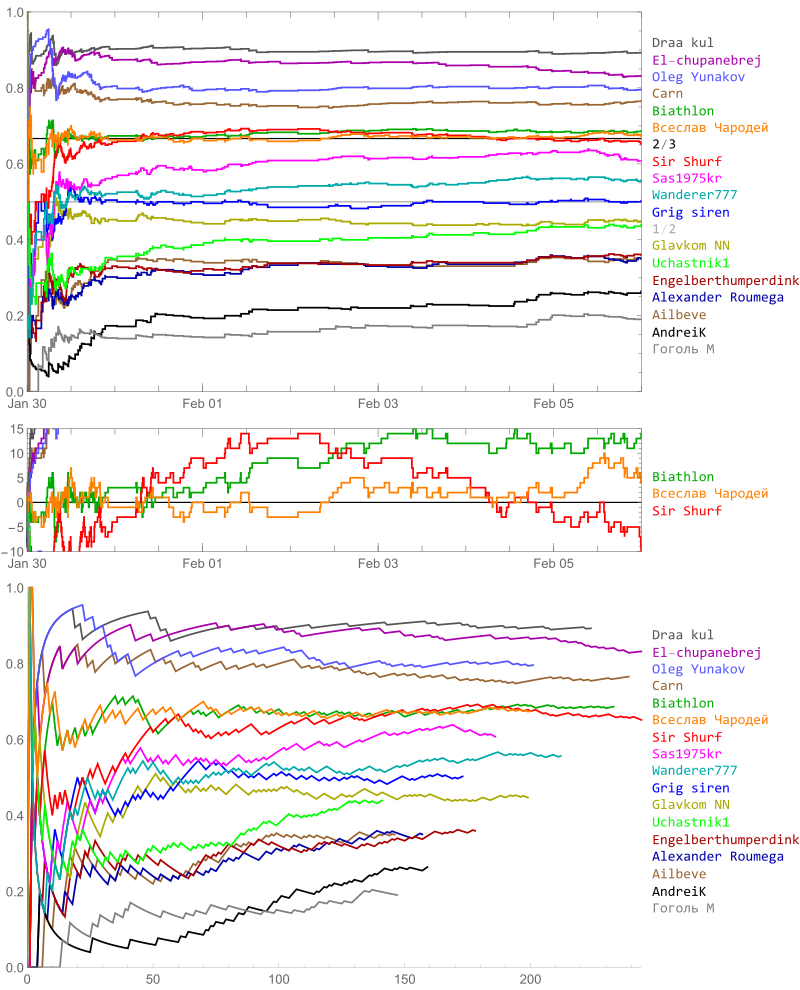
Дельта-метод
(в
статистике
) —
вероятностное распределение
функции от асимптотически
нормальной
статистической
оценки
при известной асимптотической
дисперсии
этой оценки.
Одномерный дельта-метод
Хотя дельта-метод легко обобщается до многомерного случая, аккуратное обоснование этой техники проще продемонстрировать в одномерной постановке задачи. Грубо говоря, если существует
последовательность
случайных величин
X
n
, удовлетворяющая:
n
[
X
n
−
θ
]
→
D
N
(
0
,
σ
2
)
{\displaystyle {{\sqrt {n}}[X_{n}-\theta ]\,{\xrightarrow {D}}\,{\mathcal {N}}(0,\sigma ^{2})}}
где
θ
и
σ
2
- конечные константы, а
→
D
{\displaystyle {\xrightarrow {D}}}
обозначает
сходимость по распределению
, то верно:
n
[
g
(
X
n
)
−
g
(
θ
)
]
→
D
N
(
0
,
σ
2
[
g
′
(
θ
)
]
2
)
{\displaystyle {{\sqrt {n}}[g(X_{n})-g(\theta )]\,{\xrightarrow {D}}\,{\mathcal {N}}(0,\sigma ^{2}[g'(\theta )]^{2})}}
для любой функции
g,
такой, что
g′
(
θ
)
существует, принимает ненулевые значения, и полиномиально ограничена случайной величиной
.
Доказательство в одномерном случае
Демонстрация этого результата довольно очевидна в предположении, что
g′
(
θ
)
непрерывна
.
По
формуле Лагранжа
:
g
(
X
n
)
=
g
(
θ
)
+
g
′
(
θ
~
)
(
X
n
−
θ
)
,
{\displaystyle g(X_{n})=g(\theta )+g'({\tilde {\theta }})(X_{n}-\theta ),}
где
θ
~
{\displaystyle {\tilde {\theta }}}
лежит между
X
n
и
θ
.
Поскольку
X
n
→
P
θ
{\displaystyle X_{n}\,{\xrightarrow {P}}\,\theta }
и
X
n
<
θ
~
<
θ
{\displaystyle X_{n}<{\tilde {\theta }}<\theta }
, то
θ
~
→
P
θ
{\displaystyle {\tilde {\theta }}\,{\xrightarrow {P}}\,\theta }
, и поскольку
g′
(
θ
)
непрерывна, применение теоремы о непрерывном отображении даёт:
g
′
(
θ
~
)
→
P
g
′
(
θ
)
,
{\displaystyle g'({\tilde {\theta }})\,{\xrightarrow {P}}\,g'(\theta ),}
где
→
P
{\displaystyle {\xrightarrow {P}}}
обозначает
сходимость по вероятности
.
Перестановка слагаемых и умножение на
n
{\displaystyle {\sqrt {n}}}
даёт
n
[
g
(
X
n
)
−
g
(
θ
)
]
=
g
′
(
θ
~
)
n
[
X
n
−
θ
]
.
{\displaystyle {\sqrt {n}}[g(X_{n})-g(\theta )]=g'\left({\tilde {\theta }}\right){\sqrt {n}}[X_{n}-\theta ].}
Так как
n
[
X
n
−
θ
]
→
D
N
(
0
,
σ
2
)
{\displaystyle {{\sqrt {n}}[X_{n}-\theta ]{\xrightarrow {D}}{\mathcal {N}}(0,\sigma ^{2})}}
по предположению, то применение
теоремы Слуцкого
даёт
n
[
g
(
X
n
)
−
g
(
θ
)
]
→
D
N
(
0
,
σ
2
[
g
′
(
θ
)
]
2
)
.
{\displaystyle {{\sqrt {n}}[g(X_{n})-g(\theta )]{\xrightarrow {D}}{\mathcal {N}}(0,\sigma ^{2}[g'(\theta )]^{2})}.}
Это завершает доказательство.
Доказательство с явным порядком приближения
Как вариант, можно добавить ещё один шаг в конце, чтобы выразить степень приближения.
n
[
g
(
X
n
)
−
g
(
θ
)
]
=
g
′
(
θ
~
)
n
[
X
n
−
θ
]
=
n
[
X
n
−
θ
]
[
g
′
(
θ
~
)
+
g
′
(
θ
)
−
g
′
(
θ
)
]
=
n
[
X
n
−
θ
]
[
g
′
(
θ
)
]
+
n
[
X
n
−
θ
]
[
g
′
(
θ
~
)
−
g
′
(
θ
)
]
=
n
[
X
n
−
θ
]
[
g
′
(
θ
)
]
+
O
p
(
1
)
⋅
o
p
(
1
)
=
n
[
X
n
−
θ
]
[
g
′
(
θ
)
]
+
o
p
(
1
)
{\displaystyle {\begin{aligned}{\sqrt {n}}[g(X_{n})-g(\theta )]&=g'\left({\tilde {\theta }}\right){\sqrt {n}}[X_{n}-\theta ]={\sqrt {n}}[X_{n}-\theta ]\left[g'({\tilde {\theta }})+g'(\theta )-g'(\theta )\right]\\&={\sqrt {n}}[X_{n}-\theta ]\left[g'(\theta )\right]+{\sqrt {n}}[X_{n}-\theta ]\left[g'({\tilde {\theta }})-g'(\theta )\right]\\&={\sqrt {n}}[X_{n}-\theta ]\left[g'(\theta )\right]+O_{p}(1)\cdot o_{p}(1)\\&={\sqrt {n}}[X_{n}-\theta ]\left[g'(\theta )\right]+o_{p}(1)\end{aligned}}}
Это говорит о том, что ошибка аппроксимации сходится к 0 по вероятности.
Многомерный дельта-метод
По определению,
состоятельная оценка
B
сходится по вероятности
к своему истинному значению
β
, и зачастую можно применить
центральную предельную теорему
, чтобы получить
асимптотически нормальную оценку
:
n
(
B
−
β
)
→
D
N
(
0
,
Σ
)
,
{\displaystyle {\sqrt {n}}\left(B-\beta \right)\,{\xrightarrow {D}}\,N\left(0,\Sigma \right),}
где
n
-- число наблюдений и Σ -- (
симметричная
,
положительно определённая
)
ковариационная матрица
. Предположим, мы хотим оценить дисперсию скалярной функции
h
от оценки
B
. Возьмём первых два члена
ряда Тейлора
и используя векторную нотацию
градиента
, мы можем оценить
h(B)
как
h
(
B
)
≈
h
(
β
)
+
∇
h
(
β
)
T
⋅
(
B
−
β
)
{\displaystyle h(B)\approx h(\beta )+\nabla h(\beta )^{T}\cdot (B-\beta )}
что означает, что дисперсия
h(B)
примерно
Var
(
h
(
B
)
)
≈
Var
(
h
(
β
)
+
∇
h
(
β
)
T
⋅
(
B
−
β
)
)
=
Var
(
h
(
β
)
+
∇
h
(
β
)
T
⋅
B
−
∇
h
(
β
)
T
⋅
β
)
=
Var
(
∇
h
(
β
)
T
⋅
B
)
=
∇
h
(
β
)
T
⋅
Cov
(
B
)
⋅
∇
h
(
β
)
=
∇
h
(
β
)
T
⋅
Σ
n
⋅
∇
h
(
β
)
{\displaystyle {\begin{aligned}\operatorname {Var} \left(h(B)\right)&\approx \operatorname {Var} \left(h(\beta )+\nabla h(\beta )^{T}\cdot (B-\beta )\right)\\&=\operatorname {Var} \left(h(\beta )+\nabla h(\beta )^{T}\cdot B-\nabla h(\beta )^{T}\cdot \beta \right)\\&=\operatorname {Var} \left(\nabla h(\beta )^{T}\cdot B\right)\\&=\nabla h(\beta )^{T}\cdot \operatorname {Cov} (B)\cdot \nabla h(\beta )\\&=\nabla h(\beta )^{T}\cdot {\frac {\Sigma }{n}}\cdot \nabla h(\beta )\end{aligned}}}
Можно использовать
формулу конечных приращений
(для действительнозначных функций нескольких переменных), чтобы увидеть, что это не влияет на приближения в первом порядке
[[{{{1}}}|?]]
.
Дельта метод утверждает, что
n
(
h
(
B
)
−
h
(
β
)
)
→
D
N
(
0
,
∇
h
(
β
)
T
⋅
Σ
⋅
∇
h
(
β
)
)
{\displaystyle {\sqrt {n}}\left(h(B)-h(\beta )\right)\,{\xrightarrow {D}}\,N\left(0,\nabla h(\beta )^{T}\cdot \Sigma \cdot \nabla h(\beta )\right)}
или в одномерном случае:
n
(
h
(
B
)
−
h
(
β
)
)
→
D
N
(
0
,
σ
2
⋅
(
h
′
(
β
)
)
2
)
.
{\displaystyle {\sqrt {n}}\left(h(B)-h(\beta )\right)\,{\xrightarrow {D}}\,N\left(0,\sigma ^{2}\cdot \left(h^{\prime }(\beta )\right)^{2}\right).}
Пример
Замечание
Этот раздел
требует существенной доработки
.
Этот раздел статьи необходимо дополнить и убрать это сообщение.
Примечания
![{\displaystyle {{\sqrt {n}}[X_{n}-\theta ]\,{\xrightarrow {D}}\,{\mathcal {N}}(0,\sigma ^{2})}}](/images/008/188/8188077/1.jpg?rand=764268)

![{\displaystyle {{\sqrt {n}}[g(X_{n})-g(\theta )]\,{\xrightarrow {D}}\,{\mathcal {N}}(0,\sigma ^{2}[g'(\theta )]^{2})}}](/images/008/188/8188077/3.jpg?rand=593866)








![{\displaystyle {\sqrt {n}}[g(X_{n})-g(\theta )]=g'\left({\tilde {\theta }}\right){\sqrt {n}}[X_{n}-\theta ].}](/images/008/188/8188077/12.jpg?rand=264547)
![{\displaystyle {{\sqrt {n}}[X_{n}-\theta ]{\xrightarrow {D}}{\mathcal {N}}(0,\sigma ^{2})}}](/images/008/188/8188077/13.jpg?rand=725455)
![{\displaystyle {{\sqrt {n}}[g(X_{n})-g(\theta )]{\xrightarrow {D}}{\mathcal {N}}(0,\sigma ^{2}[g'(\theta )]^{2})}.}](/images/008/188/8188077/14.jpg?rand=400235)
![{\displaystyle {\begin{aligned}{\sqrt {n}}[g(X_{n})-g(\theta )]&=g'\left({\tilde {\theta }}\right){\sqrt {n}}[X_{n}-\theta ]={\sqrt {n}}[X_{n}-\theta ]\left[g'({\tilde {\theta }})+g'(\theta )-g'(\theta )\right]\\&={\sqrt {n}}[X_{n}-\theta ]\left[g'(\theta )\right]+{\sqrt {n}}[X_{n}-\theta ]\left[g'({\tilde {\theta }})-g'(\theta )\right]\\&={\sqrt {n}}[X_{n}-\theta ]\left[g'(\theta )\right]+O_{p}(1)\cdot o_{p}(1)\\&={\sqrt {n}}[X_{n}-\theta ]\left[g'(\theta )\right]+o_{p}(1)\end{aligned}}}](/images/008/188/8188077/15.jpg?rand=61827)