Анализатор трафика
- 1 year ago
- 0
- 0

|
|
Необходимо проверить качество перевода,
исправить содержательные и стилистические ошибки
.
|
|
|
Этот перевод статьи с другого языка
требует улучшения (см.
Рекомендации по переводу
)
.
|
См. также LL(1)
Синтаксический LL-анализатор ( LL parser ) — в информатике нисходящий синтаксический анализатор для некоторого подмножества контекстно-свободных грамматик , известных как LL-грамматики . При этом не все контекстно-свободные грамматики являются LL-грамматиками.
Буквы L в выражении «LL-анализатор» означают, что входная строка анализируется слева направо (left to right), и при этом строится её (leftmost derivation).
LL-анализатор называется LL(k)-анализатором, если данный анализатор использует предпросмотр на k токенов (лексем) при разборе входного потока. Грамматика, которая может быть распознана LL(k)-анализатором без возвратов к предыдущим символам, называется LL(k)-грамматикой. Язык, который может быть представлен в виде LL(k)-грамматики, называется LL(k)o-языком. Существуют LL(k+n)-языки, которые не являются LL(k)-языками.
Далее описывается анализатор, в основе которого лежит построение таблиц; альтернативой может служить анализатор, построенный методом рекурсивного спуска , который обычно пишется вручную (хотя существуют и исключения, например, генератор синтаксических анализаторов ANTLR для LL(*) грамматик).
LL(1)-грамматики очень распространены, потому что соответствующие им LL-анализаторы просматривают поток только на один символ вперед при принятии решения о том, какое правило грамматики необходимо применить. Языки, основанные на грамматиках с большим значением k, традиционно считались трудными для распознавания, хотя при широком распространении генераторов синтаксических анализаторов, поддерживающих LL(k) грамматики с произвольным k, это замечание уже неактуально.
LL-анализатор называется LL(*)-анализатором, если нет строгого ограничения для k и анализатор может распознавать язык, если токены принадлежат какому-либо регулярному множеству (например, используя детерминированные конечные автоматы ).
Существуют противоречия между так называемой «Европейской школой» построения языков, которая основывается на LL-грамматиках, и «Американской школой», которая предпочитает LR-грамматики. Такие противоречия обусловлены традициями преподавания и деталями описания различных методов и инструментов в конкретных учебниках; кроме того, своё влияние оказал Н. Вирт из ETHZ , чьи исследования описывают различные методы оптимизации LL(1) распознавателей и компиляторов.
Синтаксический анализатор предназначен для разрешения проблемы принадлежности строки заданной грамматике и построения дерева вывода в случае принадлежности.
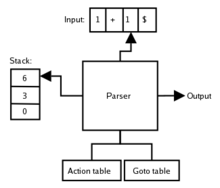
Синтаксический анализатор состоит из:
В строках таблицы располагаются символы магазинного алфавита, а в столбцах — символы терминального алфавита.
При запуске синтаксического анализа, стек уже содержит два символа:
[ S, $ ]
Где '$' — специальный терминал, служащий для указания конца стека, а 'S' — аксиома грамматики.
Синтаксический анализатор пытается при помощи правил грамматики заменить в стеке аксиому на цепочку символов, аналогичную цепочке, находящейся на входной ленте, и затем полностью прочитать ленту, опустошая стек.
Чтобы объяснить принцип работы синтаксического LL анализатора, рассмотрим следующую грамматику:
И проанализируем разбор на примере строки:
Таблица синтаксического анализа для этой грамматики выглядит следующим образом:
| ( | ) | 1 | + | $ | |
| S | 2 | — | 1 | - | - |
| F | — | — | 3 | - | - |
Здесь также есть столбец для специального терминала, обозначенного символом $, который используется, чтобы указать конец входного потока. Цифры (нежирным текстом) в ячейках, означают номера правил указанных выше.
Синтаксический анализатор просматривает первый символ '(' из входного потока, в этот момент на вершине стека находится символ 'S', на пересечении этих значений в таблице синтаксического разбора находится правило из списка грамматики. В данном примере это правило номер 2, которое предписывает заменить в стеке символ 'S' на цепочку '(S + F)'. Состояние стека после применения этого правила:
[ (, S, +, F, ), $ ]
На следующем шаге анализатор читает символ '(' из входного потока. Так как на вершине стека находится аналогичный символ '(', то происходит чтение данного символа с ленты и его удаление из стека. Состояние стека после применения этого правила:
[ S, +, F, ), $ ]
Далее на ленте находится символ '1', а на вершине стека 'S', на пересечении этих символов в таблице находится правило 1. После применения этого правила, согласно таблице, анализатор применяет правило 3. Состояние стека после применения правил:
[ F, +, F, ), $ ] [ 1, +, F, ), $ ]
Далее синтаксический анализатор читает '1' и '+' из входного потока и, так как они соответствуют следующим двум элементам на стеке, также удаляет их из стека. В результате чего стек имеет вид:
[ F, ), $ ]
В следующих трёх шагах символ 'F' в стеке будет заменен на '1', после чего символы '1' и ')' будут прочитаны с ленты и удалены из стека. В результате на вершине стека и на ленте будет находиться символ '$', согласно определению это означает успешный разбор цепочки.
В таком случае анализатор сообщит об успешном завершении и выдаст список правил, которые были применены в процессе вывода:
Данные правила действительно являются крайним левым выводом:
Как можно заметить исходя из примера — синтаксический анализатор выполняет три различных вида действий в зависимости от того, находится ли на вершине стека нетерминал, терминал или специальный символ $:
Эти шаги повторяются до тех пор, пока не произойдёт останов. После останова мы получим или сообщение об ошибке, или сообщение об успешном распознавании цепочки.
Чтобы заполнить таблицу синтаксического анализа, необходимо установить, какое правило грамматики синтаксический анализатор должен выбрать, если нетерминальное A находится на вершине его стека и символ a - во входном потоке. Легко заметить, что такое правило должно иметь форму A → w и что у языка, соответствующего w , должна быть по крайней мере одна строка, начинающаяся с a . С этой целью мы определяем Первый набор w , написанного здесь как Fi(w) , как набор терминалов, которые могут быть найдены в начале любой строки в w , и ε, если пустая строка также принадлежит w . Учитывая грамматику с правилами A 1 → w 1 , …, A n → w n , можно вычислить Fi(w i ) и Fi(A i ) для каждого правила следующим образом:
К сожалению, первых наборов недостаточно, чтобы построить таблицу синтаксического анализа. Так происходит, потому что правая сторона w правила могла бы в конечном счете быть приведена к пустой строке. Таким образом синтаксический анализатор должен также использовать правило A → w если ε находится в Fi(w) и во входном потоке символ, который может следовать за A . Поэтому также необходимо построить Следующий набор A (здесь будет записываться как Fo(A) ) который определен как набор терминалов a таких, что существует строка символов αAaβ которая может быть получена из начального символа. Вычисление Следующих наборов для нетерминалов в грамматике может быть сделано следующим образом:
Теперь можно определить точно, какие правила будут содержаться в таблице синтаксического анализа. Если T[A, a] обозначает вход в таблице для нетерминального A и терминала a , то
T[A,a] содержит правило A → w если и только если:
Если таблица будет содержать не более одного правила в каждой ячейке, то синтаксический анализатор сможет однозначно определить, какое правило необходимо применить на каждом шаге разбора. В этом случае грамматику называют LL(1) грамматикой .
Размер таблицы синтаксического анализа в худшем случае имеет показательную сложность в зависимости от k . Однако, после выпуска (PCCTS, теперь известный как ANTLR ) приблизительно в 1992 году было показано, что размер таблицы синтаксического анализа для большинства языков программирования не имеет тенденции к показательному росту, так как не является худшим вариантом. Кроме того, в определенных случаях было возможно создание даже LL( * )-анализаторов. Однако, несмотря на это, традиционные генераторы синтаксических анализаторов, такие как yacc / GNU bison , используют LALR( 1 ) таблицы синтаксического анализа, чтобы создать ограниченный LR-анализатор .
Современные , для LL грамматик с мультиэстафетным предвидением, включают:
| Общие понятия | |
|---|---|
| Тип 0 | |
| Тип 1 | |
| Тип 2 | |
| Тип 3 | |
| Синтаксический анализ | |