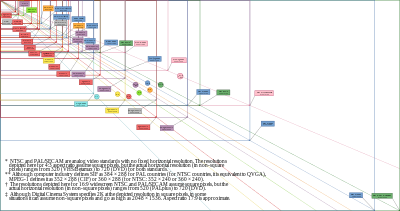
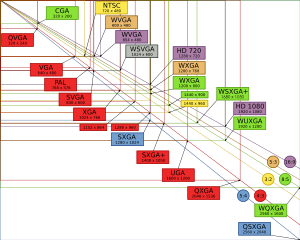
Разрешение (компьютерная графика)
- 1 year ago
- 0
- 0

Разрешение лексической многозначности ( англ. word sense disambiguation, WSD ) — это неразрешенная проблема обработки естественного языка , которая заключается в задаче выбора значения (или смысла) многозначного слова или словосочетания в зависимости от контекста , в котором оно находится. Данная задача возникает в дискурсивном анализе , при оптимизации релевантности результатов поисковыми системами, при разрешении анафорических отсылок , в исследовании лингвистической когерентности текста, при анализе умозаключений .
Научные исследования по разрешению лексической многозначности находятся в поле зрения прикладной и компьютерной лингвистики достаточно давно и имеют многолетнюю историю. С течением лет количество предложенных решений и их эффективность неуклонно росли до тех пор, пока эффективность не достигла определённого уровня сравнительно-эффективных показателей точности для определённого спектра слов и типов многозначностей . Полного решения задача пока не получила, поскольку на пути успешного решения стоит много проблем, напрямую связанных с языковыми особенностями человеческой речи.
Было исследовано большое количество методов: от методов, основанных на знаниях, правилах, лексикографических источников, обучения с учителем на корпусе текстов, до методов обучения без учителя , кластеризующие слова на основе смысла. Среди перечисленных, на сегодняшний день, методы обучения с учителем показали наилучшую эффективность. Однако, объективное сравнение и оценка методов является сложным процессом, зависящим от многих факторов. Для обобщённых систем словарных знаний (для английского языка) эффективность регулярно превышает планку в 90 %, иногда достигая даже 96 %. Для более дифференцированных словарных систем эффективность находятся в пределе 59 %-69 %.
Вообще, под неоднозначностью (или многозначностью) языкового выражения или речевого произведения (текста) понимают наличие у него одновременно нескольких различных смыслов . Учёные разделяют несколько типов подобной многозначности: лексическую, синтаксическую и речевую, однако термин «WSD» включает в себя разрешение именно лексической (смысловой).
О чём речь, можно понять из следующего примера с неоднозначным словом «ключ»:
а также 3 контекста:
Для человека является очевидным, что в первом предложении слово « ключ » используется в первом значении, во втором предложении — соответственно во втором значении, а в третьем — возможны варианты. Разработка алгоритмов, имитирующих подобную способность человека может подчас становиться сложнейшей задачей.
Процесс разрешения требует нескольких вещей: системы словарных знаний для определения множества значений слов и корпус текстов для разрешения (в некоторых случаях могут потребоваться ).
Эта проблема была впервые сформулирована в качестве отдельной задачи в 1940-х годах, во времена зарождения машинного перевода, что делает её одной из старейших проблем компьютерной лингвистики. ( англ. ), в его знаменитом «The „Translation“ memorandum» (1949) , представил проблему в компьютерно-вычислительном аспекте. Исследователи того времени прекрасно понимали её значение и сложность, в частности Иешуа Бар-Хиллель (один из первопроходцев) в 1960 выразил сомнение, что задача всеобщего полностью автоматического машинного перевода когда-либо будет осуществима из-за необходимости смоделировать всё знание человека о мире .
В 70-х, проблема WSD стала частью систем семантической интерпретации, разрабатываемых в рамках области ИИ , однако они по большей части состояли из вручную выведенных правил, и поэтому полностью зависели от количества имеющихся знаний, добывать которые в то время было чрезвычайно трудоёмко.
К 80-м годам такие объёмные ресурсы, как , стали доступны и ручное выписывание правил было вытеснено автоматическим извлечением знаний из подобных источников, однако методы всё ещё не вышли из класса так называемых «методов, основанных на знаниях».
Однако, в 90-х, «статистическая революция» полностью изменила подходы и методы в компьютерной лингвистике, и задача разрешения лексической многозначности стала проблемой, к которой применимы всевозможные методы обучения с учителем .
2000-е годы показали, что методы обучения с учителем достигли некоего уровня точности и не могут его преодолеть, поэтому внимание учёных сместилось в сторону работы с более обобщёнными системами словарных знаний (coarse-grained senses), адаптации к предметным областям (domain adaptation), частичного обучения с учителем (semi-supervised systems) и обучения без учителя (unsupervised corpus-based systems), смешанных методов, а также обработки баз знаний и выведению результатов в виде графов (the return of knowledge-based systems via graph-based methods). Однако, до сегодняшнего дня системы обучения с учителем считаются наиболее эффективными.
Однако почему же такая задача вызывает столько сложностей, а результаты её решений демонстрируют сравнительно низкую эффективность? В процессе работы над проблемой разрешения лексической многозначности было обнаружено большое количество трудностей, чаще всего обусловленных свойствами человеческой психологии и речи.
Во-первых, все словари разные и не эквивалентны друг другу. Чаще всего задача отличить смыслы слова друг от друга не вызывает трудностей, однако в некоторых случаях различные значения слова могут быть очень близкими друг другу семантически (например, если каждый из них является метафорой или метонимией друг к другу), и в таких ситуациях разделение на смыслы в разных словарях и тезаурусах может значительно разниться. Решением данной трудности может стать всеобщее использование одного и того же источника данных: одного всеобщего словаря. Если говорить глобально, то результаты исследований, использующих более обобщённую систему разделения на смыслы, более эффективны , поэтому некоторые исследователи попросту игнорируют в своих работах обработку словарей и тезаурусов с более детальным подразделением на смыслы.
Во-вторых, в некоторых языках частеречная разметка может быть очень близко связана с проблемой разрешения многозначностей, в результате чего эти две задачи могут друг другу мешать. Ученые так и не пришли к единому мнению, стоит ли разделять их на две автономные составляющие, однако перевес находится на стороне тех, кто считает, что это необходимо .
Третья трудность заключается в человеческом факторе . Системы разрешения лексической многозначности всегда оценивались сравнением результатов с результатом работы людей. А людям данная задача может оказаться не такой простой, как POS-tagging — размечать смыслы среди нескольких предложенных в несколько раз сложнее . Если человек может держать в голове или же легко угадать части речи, которыми может быть слово, то запомнить все возможные смыслы слов не представляется возможным. Более того, как выяснилось, результаты у разных людей не всегда совпадают и они часто не приходят к общему решению о том, в каком значении данное слово употреблено в конкретном контексте. Несмотря на это, учёные берут результат человека в качестве стандарта, эталона для сравнения с результатами компьютера. Надо отметить, что человек намного лучше справляется с обобщенными системами словарей, чем с детальными — и именно поэтому внимание исследователей переключилось именно на них .
|
|
Этот раздел
не завершён
.
|
Некоторые исследователи утверждают , что при обработке текстов немаловажен также здравый смысл , обучить которому компьютер представляется маловозможным. В качестве примера можно привести два следующих предложения:
В первом предложении подразумевается, что Jill и Mary являются приходятся сёстрами друг другу; во втором же — что и Jill, и Mary обе являются матерями, и не факт, что они родственники. Поэтому для более точного анализа значений необходимо наличие подобных знаний о мире и обществе. Более того, эти знания порой также необходимы при разрешении синтаксических неоднозначностей и при анализе анафор и катафор .
В-пятых, постоянный задаче-независимый (task-independent) набор методов не имеет смысла, если учесть то, что многозначность слова мышь (животное и компьютерное устройство), например, вообще не влияет на результат англо-русского и русско-английского перевода (так как в обоих языках оба эти значения имеют воплощение в одном и том же слове), но сильно влияет при информационном поиске. Можно привести и обратный пример: при переводе с английского слова 'river' на французский нам необходимо знать значение слова ('fleuve' — река, впадающая в море, а 'rivière' — река, впадающая в другую реку). В итоге, для разных задач требуются и разные алгоритмы — поэтому, если будет разработан какой-нибудь хороший алгоритм разрешения лексической многозначности, невозможно быть полностью уверенным, что он подойдёт под решение всех задач.
В шестых, учёными ставится вопрос о возможности дискретного представления значений слова. Даже сам термин « » довольно общий и спорный. Большинство людей соглашаются при работе с обобщёнными системами знаний с высоким уровнем омографии слов, но как только уровень снижается и словари становятся более детальными — тут возникает большое количество расхождений. К примеру, на конференции Senseval-2, который использовал детальные системы, люди-аннотаторы пришли к соглашению только в 85 % случаев .
Значения слов очень гибки, довольно изменчивы и чрезвычайно контекстны, а иногда даже конситуационно зависимы, поэтому они не всегда строго делятся на несколько подзначений . Лексикографы часто встречают в текстах слишком широкие и семантически перекрывающие друг друга подсмыслы, и стандартные значения слов часто приходится корректировать, расширять и сужать самым причудливым и неожиданным образом. Например, в данной ситуации «дети бегут к своим матерям» слово «дети» употребляется одновременно в двух смыслах: они одновременно является детьми своих родителей и просто детьми. Задача лексикографа состоит в том, чтобы, проанализировав огромный объём текстов и материалов, описать весь возможный спектр значений слова. Однако, пока неизвестно, применим ли этот подход в области вычислений и компьютерной лингвистики, ведь решения лексикографов принимаются в пользу полноты описанных смыслов, а не применимости полученной информации при обработке текстов.
Недавно, задача, получившая название ( англ. ), была предложена в качестве решения проблемы дифференцирования значений слов . Смысл её заключается в предоставлении замены слова другим, сохраняющим значение старого в данном контексте.
Общеизвестным фактом является то, что результаты процесса зависят не только от инновативности и эффективности методов, но и от различных настроек/свойств задачи, и требований процесса разрешения (например, дифференцированности значений слова, особенностей оценки результатов, покрытию разрешения (disambiguation coverage) и др.). Также, важно то, что большое количество областей NLP могут воспользоваться результатами WSD.
В системах поиска информации — если при поиске по запросу исключить из рассмотрения те документы, в которых какое-либо из слов запроса употребляется в не том значении, которое интересует пользователя в данный момент, то можно увеличить релевантность результатов запросов.
В 1994 г. Sanderson обнаружил , что улучшения могут быть обнаружены только если эффективность разрешения многозначности превышает 90 %, the general validity of which is debated. И в 1995 Schutze и Pedersen показали , который показал, что при вышеуказанной эффективности можно получить 4 % улучшение поиска. Однако Стоуки показал, что использование WSD может дать, пусть и небольшие — в среднем 1,73 %, результаты и при более низкой эффективности WSD (62.1 %) .
В системах машинного перевода отсутствие надежных механизмов распознавания значения слова значительно снижает качество перевода, так как слово не всегда однозначно переводится на другой язык. И автоматическое определение правильного перевода в зависимости от контекста — очень трудная задача. Разрешение лексической многозначности ещё с давних пор задумывалось как главная задача, решение которой позволит добиться почти идеального машинного перевода — эти мысли основаны на идее, что WSD не может не улучшить системам перевода выбрать правильные кандидаты значений для перевода. Эта область не исследована настолько, насколько необходимо, из-за с давних пор ставших традиционными менее эффективными предопределёнными ( англ. )".
В специфичных областях наибольший интерес представляют проблемы разрешения специфичных им концептов: к примеру, в медицинской области может пригодиться определения названий лекарств в тексте, тогда как в биоинформатике необходимо разрешать неоднозначности в именовании генов и протеинов — этот процесс был назван Извлечение информации (Information Extraction). Оно включает в себя такие задачи, как ( англ. ) (NER), раскрытие акронимов (acronym expansion) (напр., РФ — Российская Федерация) и другие — всё это можно рассматриваться в качестве задачи разрешения многозначности, хотя это и является новым и ещё толком не исследованным направлением.
Контент-анализ и выявление главных частей текста в терминах идей, тем и т. п. может извлечь большую выгоду от WSD. К примеру, классификация текстов (блогов), присвоение тегов статьям или , или определение релевантных (возможно, семантически) связей между ними, или (семантический) анализ социальных сетей , становящаяся всё более и более активной в последнее время. Эта область является наиболее новой, неизвестной из всех вышеперечисленных.
Как и всегда, при обработке естественного языка, существует два подхода: глубокий и поверхностный.
Подходы, относящиеся к первой категории предполагают доступ к так называемому (world knowldge или commonsense knowledge base). Например, знание того, что «любая неодушевлённая, материальная вещь может быть зелёным в смысле цвета, но не может быть зелёным в смысле неопытности», позволяет определить, в каком смысле слово «зелёный» употреблено в данном контексте. Такие подходы не настолько результативны на практике, поскольку такой класс знаний о мире, пусть и возможно хранить в удобном для восприятия компьютера формате, покрывает очень небольшие области нашей с вами жизни и не совсем применимы ко всем исследованиям. Надо сказать, что и этот подход тоже не всегда работает, например, в предложении «Директор был такой зелёный» пользуясь знаниями, невозможно определить, в данном случае директор зелёный потому что он позеленел или потому что он неопытен — зачастую это возможно определить только исходя не из контекста, а логики и смысла всего текста.
Также, в компьютерной лингвистике существует старая традиция применения данных методов в терминах программных знаний, и зачастую довольно сложно определить, эти знания являются лингвистическими или ( англ. ). Первая попытка была предпринята ( англ. ) и её коллегами из Кембриджского отделения по исследованию языка (Cambridge Language Research Unit) в Англии, в 50-х: они использовали данные тезауруса Роже и пронумерованные ( англ. ) в качестве индикаторов тем и анализировались повторения в тексте, используя алгоритм пересечения множеств. Этот эксперимент был не очень удачен , однако оказал сильнейшее влияние на последующие работы, особенно на работу Яровкского 1990-х об оптимизации тезаурусного метода с помощью машины обучения с учителем.
Поверхностные же подходы не пытаются понять текст, они лишь опираются на анализ близлежащих слов, например: если рядом со словом «bass» присутствуют слова «sea» или «fishing», скорее всего, что в данном случае имеет место значение в биологическом смысле. Эти правила могут быть автоматически извлечены, используя корпус текстов с размеченными значениями слов. Этот подход, пусть и не покрывает по мощности предыдущий, по эффективности на практике легко его обгоняет. Однако, всегда существуют подводные камни, например как в предложении «The dogs bark at the tree», в котором рядом со словом «bark» содержатся слова и «tree», и «dogs».
Существует четыре основных метода разрешения многозначности:
Метод Леска — продуктивный метод, основанный на использовании знаний словаря. Он основывается на гипотезе, что слова, находящиеся рядом в тексте, связаны друг с другом и эту связь можно наблюдать у определений слов и их значений. Два (или более) слова могут оказаться близкими, если у обоих из них будет обнаружена пара значений с наибольшим пересечением слов в их определениях в словаре. К примеру, словосочетание «pine cone», в определениях обоих в одного из значений присутствует такие слова как «evergreen» и «tree». Также, как альтернативу предыдущему способу, можно использовать глобальную связь между этими словами, подсчитав семантическую близость каждой пары значений в WordNet .
Как альтернативу вышеизложенным методам можно использовать общую ( англ. ) значений слов, основанную на WordNet 'e. Методы, использующие графы и работающие по принципу ( англ. ) также применялись с некоторым успехом: некоторые из них показали точность, сравнимую с методами обучения с учителями, а иногда и превосходящую в определённых областях. Также, недавно было показано , что даже простейшие методы, основанные на мерах связности графов (таких, как степень/валентность всего графа) могут показать высокие результаты при наличии богатой лексической базы.
Использование так называемых моделей управления («selectional preferences» или «selectional restrictions») также бывает довольно полезным. К примеру, используя знание, что слово «bass» в значении рыбы часто встречается со словом «cook» или «eat», мы можем разрешить многозначность в таком предложении как «I am cooking bass». Однако, создать подобные знания о мире чрезвычайно трудозатратно и практически невозможно.
Все методы обучения с учителем основаны на предположении, что контекст рассматриваемого нами слова предоставляет достаточно информации для того, чтобы вычислить то, в каком значении оно в данном случае применено (а значит знания, полученные из словарей и тезаурусов, отсекаются как лишние). Все модели обучения с учителем применялись к проблеме WSD, включая связанные с ними техники, такие как , и ( англ. ). Метод опорных векторов и ( англ. ) показали себя как одни из наиболее высокоэффективные методы на сегодняшний день, возможно, потому что они могут справиться с свойствами слов и контекстов. Однако, вышеперечисленные методы имеют в качестве узкого места требование иметь огромное количество вручную размеченных текстов для обучения, что, как уже говорилось, трудоёмко и дорого. Снова встаёт проблема обладания подобными размеченными корпусами.
Метод бутстреппинга является распространённым способом итеративного обучения и оценки классификатора для увеличения его эффективности. Алгоритм начинается с небольшого количества начальных данных (англ. seed data) для каждого слова: либо небольшое количество вручную введённых примеров контекстов либо пара безошибочных правил определения значения слова (к примеру, слово «play» в контексте слова «bass» почти всегда обозначает, что слово подразумевается в музыкальном значении). Эти данные используются для тренировки классификатора, применяя любой из вышеприведённых методов обучения с учителем. Затем, классификатор применяется на множестве уже неразмеченных текстов для извлечения большой тренирующей выборки, в которую включены только «надёжные» контексты. Процесс итеративно повторяется: каждый следующий классификатор обучается на соответствующем ему бо́льшем множестве контекстов — и повторяется до тех пор, пока весь корпус не покрыт либо пока не достигнуто максимальное количество итераций.
Другой метод использует большие объёмы неразмеченных текстов для получения информации о совместной встречаемости слов, что может значительно дополнить наши данные. Также, правильно выравненный может использоваться для разрешения кросс-языковой многозначности, так как многозначное слово в одном языке всегда переводится на другой язык в зависимости от своего значения, в котором оно употреблено. Этот метод в каком-то смысле тоже можно считать методом частичного обучения.
Все вышеперечисленные техники могут позволить адаптировать методы обучения с учителем к другим областям.
Данный вид методов — одна из наиболее сложных WSD-задач. Основным предположением этого метода является утверждение: «схожие значения встречаются в схожих контекстах» и таким образом они могут быть извлечены из текста с помощью кластеризации, используя некоторую меру схожести контекстов . Тогда, новые контексты могут быть причислены к одному из ближайших кластеров. Производительность метода безусловно ниже других методов, однако сравнение несколько проблематично из-за необходимости проецирования полученных кластеров на имеющиеся в словаре значения. Если же проецирование не требуется, то можно произвести оценки кластеризации (включая энтропию и чистоту). Учёные возлагают большую надежду на то, что методы обучения без учителя смогут помочь превозмочь недостатки ( англ. ), так как они не требуют решения чрезмерно трудоёмких задач по синтаксической и семантической разметке всего корпуса.
Также существуют другие методы, основанные на совершенно отличающихся от вышеперечисленных принципах:
( англ. ) является наиболее серьёзным препятствием на пути решения проблемы разрешения многозначности. Методы обучения без учителя опираются на знания, которые едва ли присутствуют в электронных словарях и других лингвистических электронных системах знаний. Методы же обучения с учителем и вовсе полагаются на существование вручную аннотированного корпуса, существование которого технически реализуемо только для небольшого набора слов для целей тестирования, как это было проделано для Senseval.
Поэтому, одним из наиболее обнадёживающих трендов является использование Интернета в качествое корпуса для получения лексической информации автоматически . WSD традиционно понимался как способ улучшить результаты таких областей, как information retrieval (IR). В данном случае, тем не менее, обратное тоже верно: поисковые системы обладают простыми и достаточно быстрыми возможностями для успешного майнинга Интернета для использования в WSD. Поэтому проблема получения знаний спровоцировала появление определённых методов по их получению:
Знания являются одними из ключевых моментов разрешения многозначности: они предоставляют данные, на которые опирается сам процесс разрешения. Эти данные могут быть как корпусы текстов, так и словари, тезурусы, глоссарии, онтологии:
Тестирование и сравнение методов является совсем нетривиальной задачей из-за различий в различных тестовых выборках, sense inventories, а также используемых источников данных. До того, как были созданы специальные мероприятия для сравнения систем, они сравнивались вручную, на собственных, часто небольших подборок данных. Ведь для того, чтобы проверить свой алгоритм, разработчики должны потратить время, чтобы вручную разметить все употребления слов. И сравнивать одни и те же методы даже на одинаковых текстах нельзя, если в них используются разные системы толкования слов.
Для «объединения» и сравнения методов были организованы международные конференции по сравнению систем WSD. (теперь переименована в ) является международной конференцией по сравнению систем разрешения лексической многозначности, проводившаяся каждые 3 года, начиначя с 1998: (1998), (2001), (2004), и их логический последователь , который был полностью посвящён задаче WSD и был проведён единожды, в 2007 году. В число её задач входит организация семинаров и мастер-классов, подготовка и разметка корпусов вручную для тестирования систем, а также сравнение алгоритмов различных типов («all-words» и «lexical sample» WSD, палгоритмы использующие аннотированный корпус и использующие неаннотированный) а также изучение таких подзадач как , , и т. д. В рамках вышеперечисленных мероприятий также проводились сравнения WSD-систем в рамках не только английского языка. Однако, ни одного языка славянской группы на мероприятиях не было.
Система значений слов . Во время первых конференций в качестве систем значений слов (словарей, лексических баз данных) использовались либо малоизвестные недоступные ранее (напр., проект HECTOR) либо небольшие, самостоятельно сделанные организаторами небольшие, неполные версии настоящей полной системы, покрывающие те области, которые требовались в соревновании. Обычно и те, и другие являлись недостаточно подробными и дифференцированными (англ. coarse-grained), однако выбирались именно они для того, чтобы избежать использования наиболее популярных и подробных (англ. fine-grained) примеров (напр., WordNet ), поскольку это сделало бы эксперимент «нечистым», так как эти базы знаний уже были неоднократно «засвечены» в различных исследованиях и оценках. Было замечено, что на более подробных результаты были совсем другими, поэтому было принято решение тестировать алгоритмы и на тех, и на других sense inventories.
Набор проверяемых слов . Также, сравнение методов разрешения многозначности делится на два типа по количеству проверяемых слов: разрешение лексической многозначности некоторой совокупности слов (чаще всего, несколько десятков) и разрешение лексической многозначности всех слов текста. Их различие заключается в объёме анализа и обработки данных: задача «all-words» («все-слова-текста») подразумевает обработку всех присутствующих в тексте слов на предмет многозначности (абсолютно все слова в корпусе должны быть разрешены), задача же «lexical sample» («ограниченный набор») состоит в разрешении только целевых слов, определённых заранее и находящихся в нашем корпусе. Первый тип предполагается более реалистичной оценкой, однако намного более трудоёмкой с точки зрения проверки результатов. Из-за сложностей тестирования второго в первых конференциях проводились тестирования тестового набора, однако потом оба были включены в тестирование.
В случае задачи «ограниченного набора слов» организаторам необходимо было выбрать те самые ключевые слова, на которых системы должны были тестироваться. Критикой мероприятий, которые происходили до Senseval’a, являлось то, что эти образцы из набора выбиралось по прихоти экспериментаторов. На Senseval’e этого попытались избежать, выбрав произвольные слова, разделенные на группы по частям речи, частотностям и степени многозначности. Также, по вопросу включения проблемы определения части речи в программу WSD было много разногласий, поэтому организаторы приняли решение включить в выборку слов как чётко обозначенные части речи, так и определённое количество неопределённых.
Корпус . Необходимо пояснить, что такое размеченный текст и что такое неразмеченный. Неразмеченный корпус является по сути некой массой обычных текстов, которые содержат необходимое количество упоминаний слов, которые нужно «разрешить». Размеченный же является тем же самым сборищем текстов, однако с тем отличием, что все упоминаемые слова содержат приписанную (напр., в качестве тега или иной другой мета-информацией) информацию о том, в каком значении слова употреблены в данных контекстах.
Служить обучающим материалом для наших систем по разрешению лексической многозначности могут как размеченные тексты (системы обуч. с учителем), так и неразмеченные (системы обуч. без учителя), однако для автоматического тестирования систем необходимо наличие именно размеченного, получение которого довольно трудоёмко. Процесс этот проходит таким образом: несколько лингвистов-лексикографов проходят по всему тексту и в соответствии со словарем значений всем словам из заданной выборки слов, тестируемых на определение многозначности, приписывают мета-информацию о том, в каком значении слова употреблены в данных контекстах. Затем, для каждого слова делают некое подобие кворума из принятых решений лексикографов и выносится решение о том, в каком значение оно здесь употреблено, после чего в конечную версию текста добавляются полученные теги; иным словом, все употребления избранных нами слов дополняются необходимой мета-информацией.
Затем, корпус разделяется на три части. Первая, так называемая dry-run distribution (англ. «предварительный прогон») позволяет командам отрегулировать и адаптировать свои программы к виду и структуре подаваемой на вход информации; содержит необходимый минимум информации.
Вторая часть называется тренировочной выборкой (англ. training distibution), содержащей словарные статьи и корпус с мета-информацией о значениях целевых слов), которая позволяет обучить соревнующиеся программы правильно выбирать нужные смыслы слов; она предоставляется всем командам сразу после предварительного прогона. Количество контекстов необходимых слов может колебаться довольно сильно (от нескольких до больше 1000) и зависит от количества доступных контекстов. Затем идёт стадия обучения программ.
Последняя же часть, называемая оценочной выборкой (англ. evaluation distibution, без мета-информации о значениях целевых слов), доступная после завершения обучения программ, позволяет вычислить аккуратность алгоритмов. Каждый контекст был аннотирован вручную по крайней мере тремя людьми, однако эта мета-информация не было включена в распространяемые данные, посокльку именно они проверяются. Все программы, проходя по этой выборке, необходимы были вычислить для каждого контекста наиболее вероятное значение употребляемого слова (или же список значений с соответствующими им вероятностями); после отправки данных организаторам, те автоматически получают результаты, сравнивая со своими (так как оценочная выборка, так же как и обучающая содержит размеченные употребления слов).
Группы и бейслайны . Необходимо отметить, что все алгоритмы работают по-разному и пользуются разными источниками информации, поэтому все они были разделены на группы по методу обработки текстов: методы обучения с учителем и методы обучения без учителя. Для сравнения с уже известными алгоритмами (названными отправными точками — ) были также опубликованы их результаты, например, всевозможные вариации алгоритма Леска .
Далее, поскольку задача WSD требует для себя наличия словаря значений и корпуса , организаторам надо было выбрать какие-нибудь из существующих для проекта. WordNet и SemCor — самые популярные примеры вышеперечисленных необходимых компонентов, однако их использование сделало бы эксперимент нечистым, так как эти базы знаний уже были неоднократно «засвечены» в различных исследованиях и оценках, поэтому для тестирования обычно выбираются или недоступные ранее или самостоятельно сделанные организаторами неполные версии обеих вещей (к примеру, на Senseval-1 оба были предоставлены проектом HECTOR ).
Аккуратность алгоритмов . При оценке практически любого алгоритма классификации каких-либо объектов используются две самые распространенные меры оценок — ( англ. ):
Однако, если система аннотирует каждое слово или результат рассчитывается для всех классов сразу, точность и полнота являются одной и той же величиной — она называется аккуратностью вычислений ( англ. ). Эта модель была расширена для употребления при выдаче алгоритмами списка значений с соответствующими им вероятностями.
|
|
В разделе
не хватает
ссылок на источники
(см.
рекомендации по поиску
).
|
Семинары Senseval являются наилучшим примером для изучения самых лучших результатов систем WSD и будущих направлений исследования области. Существуют определённые выводы, которые можно сделать, проанализировав и обобщив поздние конференции:
Для понимания общего состояния данной области и уровня, достигнутого лучшими системами разрешения многозначности, необходимо проанализировать и внимательно изучить лучшие результаты и их особенности:
|
|
Для улучшения этой статьи
желательно
:
|
| Общие определения | |
|---|---|
| Анализ текста | |
| Реферирование |
|
| Машинный перевод | |
|
Идентификация
и сбор данных |
|
| Тематическая модель | |