Существуют разногласия насчёт того, допустимо ли использовать слово
FLOP
от
англ.
FL
oating point
OP
eration
в единственном числе (и такие варианты как
flop
или
флоп
). Некоторые считают, что FLOP (флоп) и FLOPS (флопс или флоп/с) — синонимы, другие же полагают, что FLOP — это просто количество операций с плавающей запятой (например, требуемое для исполнения данной программы), а FLOPS — мера производительности, способность выполнять определённое количество операций с
плавающей запятой
за секунду.
Флопс как мера производительности
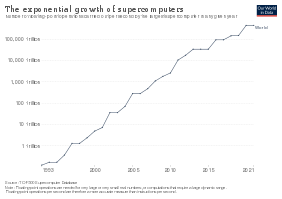
Как и большинство других показателей производительности, данная величина определяется путём запуска на испытуемом компьютере тестовой программы, которая решает задачу с известным количеством операций и подсчитывает время, за которое она была решена. Наиболее популярным тестом производительности на сегодняшний день являются
тесты производительности LINPACK
, в частности HPL, используемый при составлении рейтинга
суперкомпьютеров
TOP500
[
источник не указан 300 дней
]
.
Одним из важнейших достоинств измерения производительности во флопсах является то, что данная единица до некоторых пределов может быть истолкована как абсолютная величина и вычислена теоретически, в то время как большинство других популярных мер являются относительными и позволяют оценить испытуемую систему лишь в сравнении с рядом других. Эта особенность даёт возможность использовать для оценки результатов работы различных
алгоритмов
, а также оценить производительность вычислительных систем, которые ещё не существуют или находятся в
разработке
.
Границы применимости
Несмотря на кажущуюся однозначность, в реальности флопс является достаточно плохой мерой производительности, поскольку неоднозначным является уже само его определение. Под «операцией с плавающей запятой» может скрываться масса разных понятий, не говоря уже о том, что существенную роль в данных вычислениях играет разрядность
операндов
, которая также нигде не оговаривается. Кроме того, флопс подвержен влиянию очень многих факторов, напрямую не связанных с производительностью вычислительного модуля, таких как пропускная способность каналов связи с окружением
процессора
, производительность основной
памяти
и синхронность работы
кэш-памяти
разных уровней.
Всё это, в конечном итоге, приводит к тому, что результаты, полученные на одном и том же компьютере при помощи разных программ, могут существенным образом отличаться; более того, с каждым новым испытанием разные результаты можно получить при использовании одного алгоритма. Отчасти эта проблема решается соглашением об использовании единообразных тестовых программ (той же
LINPACK
) с усреднением результатов, но со временем возможности компьютеров «перерастают» рамки принятого теста и он начинает давать искусственно заниженные результаты, поскольку не задействует новейшие возможности вычислительных устройств. А к некоторым системам общепринятые тесты вообще не могут быть применены, в результате чего вопрос об их производительности остаётся открытым.
Так,
24 июня
2006 года
общественности был представлен
суперкомпьютер
MDGrape-3
, разработанный в японском исследовательском институте
RIKEN
(
Йокогама
), с рекордной теоретической производительностью в 1 петафлопс. Однако данный компьютер не является компьютером общего назначения и приспособлен для решения узкого спектра конкретных задач, в то время как стандартный тест LINPACK на нём выполнить невозможно в силу особенностей его архитектуры.
Также высокую производительность на специфичных задачах показывают
графические процессоры
современных
видеокарт
и
игровые приставки
. К примеру, заявленная производительность видеопроцессора игровой приставки
PlayStation 3
составляет 192 гигафлопса
, а видеоускорителя приставки
Xbox 360
и вовсе 240 гигафлопсов
, что сравнимо с суперкомпьютерами двадцатилетней давности. Столь высокие показатели объясняются тем, что указана производительность над числами 32-разрядного формата
, тогда как для суперкомпьютеров обычно указывают производительность на 64-разрядных данных
. Кроме того, данные приставки и видеопроцессоры рассчитаны на операции с
трёхмерной графикой
, хорошо поддающиеся распараллеливанию, однако эти процессоры не в состоянии выполнять многие задачи общего назначения, и их производительность сложно оценить классическим тестом
LINPACK
и тяжело сравнить с другими системами.
Пиковая производительность
Для подсчёта максимального количества флопс для процессора нужно учитывать, что современные процессоры в каждом своём ядре содержат несколько исполнительных блоков каждого типа (в том числе и для операций с плавающей запятой), работающих параллельно, и могут выполнять более одной инструкции за такт. Данная особенность архитектуры называется
суперскалярность
и впервые появилась ещё в ЭВМ
CDC 6600
в 1964 году. Массовое производство компьютеров с суперскалярной архитектурой началось с выпуском процессора
Pentium
в 1993 году. Процессор конца 2000-х годов,
Intel Core 2
, также является суперскалярным и содержит 2 устройства вычислений над 64-разрядными числами с плавающей запятой, которые могут завершать по 2 связанные операции (умножение и последующее сложение,
MAC
) в каждый такт, теоретически позволяющих достичь пиковой производительности до 4 операций за 1 такт в каждом ядре
. Таким образом, для процессора, имеющего в своём составе 4 ядра (
Core 2 Quad
) и работающего на частоте 3,5 ГГц, теоретический предел производительности составляет 4х4х3,5=56 гигафлопс, а для процессора, имеющего 2 ядра (
Core 2 Duo
) и работающего на частоте 3 ГГц — 2х4х3=24 гигафлопс, что хорошо согласуется с практическими результатами, полученными на тесте LINPACK.
AMD
Phenom 9500 sAM2+ с тактовой частотой 2,2 ГГц:
2200 МГц × 4 ядра × 4⋅10
−3
= 35,2 Гигафлопса
Для четырёхъядерного процессора Core 2 Quad Q6600:
2400 МГц × 4 ядра × 4⋅10
−3
= 38,4 Гигафлопса.
Более новые процессоры могут исполнять до 8 (например,
Sandy
и
Ivy Bridge
, 2011—2012 гг, AVX) или до 16 (
Haswell
и Broadwell, 2013—2014 гг, AVX2 и FMA3) операций над 64-битными числами с плавающей запятой в такт (на каждом ядре)
. В последующих процессорах ожидается исполнение 32 операций в такт (Intel Xeon Skylake, Xeon *v5, 2015 г, AVX512)
Несмотря на большое число существенных недостатков, флопс продолжает с успехом использоваться для оценки производительности, базируясь на результатах теста LINPACK. Причины такой популярности обусловлены, во-первых, тем, что флопс, как говорилось выше, является абсолютной величиной. А во-вторых, очень многие задачи инженерной и научной практики в конечном итоге сводятся к решению
систем линейных алгебраических уравнений
, а тест LINPACK как раз и базируется на измерении скорости решения таких систем. Кроме того, подавляющее большинство компьютеров (включая суперкомпьютеры) построены по классической архитектуре с использованием стандартных процессоров, что позволяет использовать общепринятые тесты с большой достоверностью.
В различных алгоритмах, кроме возможности выполнять большое количество математических действий в ядре процессора, может потребоваться пересылка больших объёмов данных через подсистему памяти, и их производительность будет сильно ограничена из-за этого, например, как в уровнях 1 и 2
библиотек BLAS
. Однако, алгоритмы, используемые в тестах типа LINPACK (уровень 3 BLAS), имеют высокий коэффициент переиспользования данных, пересылка данных между процессором и памятью в них занимает менее 1/10 общего времени, и они обычно достигают типичной производительности до 80-95 % от теоретического максимума.
Обзор производительности реальных систем
Из-за высокого разброса результатов теста LINPACK приведены примерные величины, полученные путём усреднения показателей на основе информации из разных источников. Производительность игровых приставок и
распределённых систем
(имеющих узкую специализацию и не поддерживающих тест LINPACK) приведена в справочных целях в соответствии с числами, заявленными их разработчиками. Более точные результаты с указанием параметров конкретных систем можно получить, например, на сайте
.
В период с 2030 по 2035 год ведущими компаниями мира планируется создать суперкомпьютер мощностью 1 зеттафлопс. Планируемая потребляемая мощность от 80 до 120 Мегаватт, энергоэффективность: 10 терафлопс/ватт, пропускная способность ввода-вывода: 10-100 петабайт/сек, объем памяти: 1,0 зеттабайт.
В 2025 году Словацкая компания Tachyum планирует запустить суперкомпьютер на базе универсальных процессоров Prodigy. После запуска он обеспечит производительность 8 зеттафлопс в задачах обучения искусственного интеллекта для больших языковых моделей. (В стандартных задачах расчётная производительность более 50 эксафлопс)
Tachyum Prodigy(VLIW) 5,7 ГГц, 192 ядра (2025) — 625 Тфлопс
Количество операций FLOP за такт для разных архитектур
Для ряда процессорных микроархитектур известны максимальные количества плавающих операций, исполняемых за такт на одном ядре. В следующем ниже списке указаны названия микроархитектур, а не семейства процессоров.
Apple A9 — 225,6 гигафлопс(fp32),56,4 гигафлопс (fp64)
Apple A10
— 365 гигафлопс(fp32), 91 гигафлопс (fp64)
Apple A11 — 462 гигафлопс(fp32),116 гигафлопс (fp64)
Apple A12 — 536 гигафлопс(fp32)134 гигафлопс (fp64)
Apple A13 — 620 гигафлопс(fp32),155 гигафлопс (fp64)
Apple A14
— 824 гигафлопс(fp32), 206 гигафлопс (fp64)
Apple A15 — 998 гигафлопс(fp32),250 гигафлопс (fp64)
Apple A16 — 1119 гигафлопс(fp32),280 гигафлопс (fp64)
Apple A17 Pro — 1252 гигафлопс(fp32),313 гигафлопс (fp64)
Apple A18 Pro — 1415 гигафлопс(fp32),354 гигафлопс (fp64)
Распределённые системы
Bitcoin
— имеет значительное количество специализированных вычислительных ресурсов, но решает исключительно целочисленные задачи (вычисление хеш-суммы
SHA256
). Практически все вычислители реализованы в виде специальных заказных микросхем (ASIC), которые технически не способны производить вычисления над числами с плавающей запятой. Следовательно, оценивать сеть Bitcoin с помощью флопсов в настоящее время некорректно.
Ранее, до 2011 года в сети использовались только
ЦПУ
и
ГПУ
, которые могут обрабатывать как целочисленные, так и плавающие данные, и оценка во флопсах получалась из метрики hash/s с помощью эмпирического коэффициента в 12,7 тысячи.
Например, на апрель 2011 мощность сети оценивалась таким методом примерно в 8 петафлопсов.
Folding@home
— более 2,6 эксафлопса на 23 апреля 2020 года, что делает его самым мощным и крупнейшим проектом распределённых вычислений в мире.
Калькулятор
не случайно попал в одну категорию вместе с человеком, поскольку хотя он и является электронным устройством, содержащим процессор, память и устройства ввода-вывода, режим его работы кардинально отличается от режима работы компьютера. Калькулятор выполняет одну операцию за другой с той скоростью, с какой их запрашивает человек-оператор. Время, проходящее между операциями, определяется возможностями человека и существенно превышает время, которое затрачивается непосредственно на вычисления. Можно сказать, что в среднем производительность простейших обычных карманных калькуляторов составляет порядка 10 флопсов и более.
Если не брать исключительные случаи (см.
феноменальный счётчик
), то обычный человек, пользуясь лишь ручкой и бумагой, выполняет операции с
плавающей запятой
очень медленно и часто с большой ошибкой, таким образом говоря о производительности человека как вычислительного аппарата, приходится использовать такие единицы, как миллифлопсы и даже микрофлопсы.
от 11 сентября 2013 на
Wayback Machine
, «Мир ПК», № 07, 2012: «Если нынешняя скорость прогресса суперкомпьютеров будет сохраняться, то следующий рубеж производительности в 1 экзафлопс, или квинтиллион (10^18) операций в секунду, ожидается достичь к 2019 г. … полагают, что компьютер производительностью один зеттафлопс (10^21 , или секстиллион операций) можно будет построить примерно к 2030 г. Более того, заранее припасены термины и для следующих вычислительных рубежей — йоттафлопс (10^24) и „ксерафлопс“ (10^27).»
от 3 декабря 2013 на
Wayback Machine
, «Компьютерра», Дата: 16 июля 2008 года: «За этим рубежом должны последовать зеттафлопс (10^21), йоттафлопс (10^24) и „ксерафлопс“ (10^27).»
↑
(неопр.)
. Дата обращения: 30 декабря 2016.
17 сентября 2016 года.
от 13 января 2010 на
Wayback Machine
floating-point ALUs .. support for FP32 precision
(неопр.)
. Дата обращения: 17 августа 2009.
5 июля 2009 года.
these are single precision GPU peak numbers
(неопр.)
. Дата обращения: 17 августа 2009.
15 октября 2009 года.
HPL is a software package that solves a dense linear system in double precision (64 bits)
(неопр.)
. Дата обращения: 28 сентября 2017.
16 марта 2012 года.
(неопр.)
. Дата обращения: 20 июля 2010.
24 мая 2010 года.
↑
Jack Dongarra.
(англ.)
.
Argonne Training Program on Extreme-scale Computing
. Argonne National Laboratory (13 августа 2014). Дата обращения: 13 апреля 2015. Архивировано из
24 апреля 2016 года.
Jack Dongarra,
от 22 декабря 2015 на
Wayback Machine
/ A Look at High Performance Computing, 2015-10-15
(англ.)
от 21 ноября 2014 на
Wayback Machine
// Компьютерра, 18 ноября 2014: «… кластер A-Class, созданный компанией „Т-Платформы“ для Научно-исследовательского вычислительного центра МГУ.»
от 17 ноября 2016 на
Wayback Machine
// Мир ЦОД, Открытые системы, 19.11.2014: «В новом суперкомпьютере МГУ всего пять вычислительных стоек с 1280 узлами на базе 14-ядерных процессоров Intel Xeon E5-2697 v3 и ускорителей NVIDIA Tesla K40 с общей емкостью оперативной памяти более 80 Тбайт. … Каждая стойка суперкомпьютера потребляет около 130 кВт»
от 11 сентября 2017 на
Wayback Machine
, TOP500 News Team | July 16, 2012
(англ.)
Agam Shah (IDG News),
от 3 июля 2017 на
Wayback Machine
// PCWorld, Computers, Oct 29, 2012
(англ.)
от 28 ноября 2014 на
Wayback Machine
// «Открытые системы», № 08, 2013
Производительность вычислений
одинарной точности
у большинства процессоров ровно в 2 раза выше указанных значений.
От 1200 до 4900 рабочих тактов процессора на выполнение 1 инструкции двойной точности в зависимости от их типа, операции одинарной точности выполнялись примерно в 10 раз быстрее:
от 26 декабря 2019 на
Wayback Machine
(страница 4)
↑
Ryan Crierie.
(англ.)
. Alternate Wars (13 марта 2014). Дата обращения: 23 января 2015.
23 января 2015 года.
↑
Jack J. Dongarra.
(англ.)
(15 июня 2014). Дата обращения: 23 января 2015.
17 апреля 2015 года.
(неопр.)
. МЦСТ. Дата обращения: 28 июня 2015. Архивировано из
4 июня 2014 года.
(неопр.)
.
АО "МЦСТ"
. Дата обращения: 16 декабря 2017.
30 марта 2018 года.
По шесть 64 разрядных
FMAC
блоков в каждом ядре: 8 х 1,3 х 6 х 2 = 124,8 ГФлоп/с пиковой производительности при вычислениях двойной точности
По два 128 разрядных
FMAC
блока в каждом модуле, объединяющем пару ядер, работающих на частоте 4 ГГц: 4х4х2х2х128/64 = 128 ГФлоп/с пиковой производительности при вычислениях двойной точности
Alex Voica.
(англ.)
(3 сентября 2015). Дата обращения: 4 февраля 2017. Архивировано из
5 февраля 2017 года.
(неопр.)
. Дата обращения: 26 декабря 2019.
27 июня 2019 года.
По два 128 разрядных
FMAC
блока в каждом ядре: 8 х 3,4 х 2 х 2 х 128/64 = 217,6 Гфлоп/с пиковой производительности при вычислениях двойной точности
(неопр.)
.
АО "МЦСТ"
. Дата обращения: 16 декабря 2017.
27 декабря 2019 года.
(неопр.)
. Дата обращения: 23 сентября 2017.
23 сентября 2017 года.
По шесть 128 разрядных
FMAC
блоков в каждом ядре: 8 х 1,5 х 6 х 2 х 128/64 = 288 Гфлопс пиковой производительности при вычислениях двойной точности
(неопр.)
. Дата обращения: 15 января 2015.
27 марта 2015 года.
(неопр.)
. Дата обращения: 26 декабря 2019.
5 марта 2021 года.
↑
По два 256 разрядных
FMAC
блока в каждом ядре: 8 х 3,6 х 2 х 2 х 256/64 = 460 ГФлоп/с
(неопр.)
. Дата обращения: 26 декабря 2019.
27 июня 2019 года.
(неопр.)
. Дата обращения: 30 января 2020.
4 января 2020 года.
(неопр.)
. Дата обращения: 26 декабря 2019.
24 июля 2019 года.
По два 256 разрядных
FMAC
блока в каждом ядре: 16 х 3,5 х 2 х 2 х 256/64 = 896 ГФлоп/с
(англ.)
.
TechPowerUp
. Дата обращения: 10 октября 2021.
(рус.)
.
iXBT.com
. Дата обращения: 10 октября 2021.
10 октября 2021 года.
(неопр.)
. Дата обращения: 15 октября 2017.
22 октября 2015 года.
↑
(неопр.)
. Дата обращения: 24 декабря 2019.
24 декабря 2019 года.
Указанное количество инструкций за такт способны исполнять только старшие представители этих архитектур, продающиеся под маркетинговыми наименованиями Xeon Platinum и Xeon Gold начиная с серии 6ххх, которые имеют по два 512 разрядных FMAC блока в каждом ядре для выполнения AVX-512 инструкций. У всех младших моделей: Xeon Bronze, Xeon Silver и Xeon Gold 5ххх один из FMAC блоков отключен и поэтому максимальный темп исполнения инструкций с плавающей точкой снижен в 2 раза.
Блок обработки операций с плавающей запятой (FPU) является общим на модуль — пару ядер процессора. При одновременном исполнении плавающих операций на обоих ядрах он разделяется между ними.
(неопр.)
. Дата обращения: 26 декабря 2019.
11 июня 2017 года.
Данная микроархитектура относится к классу
VLIW
и имеет 6 параллельных каналов исполнения инструкций, 4 из которых оснащены 64 разрядными блоками вычислений с плавающей точкой типа
FMAC
.
(неопр.)
. Дата обращения: 16 декабря 2017.
30 марта 2018 года.
В 4 м поколении архитектуры 64 разрядные FMAC блоки имеются уже на всех 6 каналах исполнения инструкций.
(неопр.)
. Дата обращения: 16 декабря 2017.
27 декабря 2019 года.
В 5 м поколении архитектуры разрядность всех FMAC блоков была увеличена с 64 до 128.
Сергей Уваров.
(неопр.)
.
IXBT.com
(23 сентября 2013).
2 октября 2013 года.
(неопр.)
. Дата обращения: 15 января 2015.
20 декабря 2014 года.
↑
(неопр.)
. Дата обращения: 22 января 2022.
22 января 2022 года.
от 30 августа 2017 на
Wayback Machine
// Gizmodo, 5/13/13: «Because Bitcoin miners actually do a simpler kind of math (integer operations), you have to do a little (messy) conversion to get to FLOPS. .. new ASIC miners—machines .. do nothing but mine Bitcoins—can’t even do other kinds of operations, they’re left out of the total entirely.»
от 3 декабря 2013 на
Wayback Machine
// SlashGear, May 13, 2013: «Bitcoin mining technically doesn’t operate using FLOPS, but rather integer calculations, so the figures are converted to FLOPS for a conversion that most people can understand more. Since the conversion process is a bit weird, it’s led to some experts calling foul on the mining figures.»
от 27 ноября 2013 на
Wayback Machine
// ExtremeTech: «As Bitcoin mining doesn’t rely on floating-point operations, these estimates are based on opportunity costs. Now that we have hardware with application-specific integrated circuits (ASIC) designed from the ground up to do nothing but mine Bitcoins, these estimates become even more fuzzy.»
от 3 декабря 2013 на
Wayback Machine
// CoinDesk
[
неавторитетный источник
]
: «Two, the estimates used to convert hashes to flops (resulting in about 12,700 flops per hash) date to 2011, before ASIC devices became the norm for bitcoin mining. ASICs don’t handle flops at all, so the current comparison is very rough.»
от 3 декабря 2013 на
Wayback Machine
// VR-Zone: «A conversion rate of 1 hash = 12.7K FLOPS is used to determine the general speed of the network contribution. The estimate was created in 2011, before the creation of ASIC hardware solely designed for bitcoin mining. ASIC doesn’t use floating point operations at all,… Thus, the estimate doesn’t have any real-world meaning for such hardware.»
, архивная копия от 2011-04-08: «Network Hashrate TFLOP/s 8007»
19 сентября 2010 года.
3 мая 2012 года.
(неопр.)
. Дата обращения: 16 апреля 2012.
21 февраля 2012 года.
↑
(неопр.)
. Дата обращения: 7 декабря 2017.
10 апреля 2021 года.
от 28 июля 2009 на
Wayback Machine
// IGN Entertainment, 2003. «PSP CPU CORE…FPU, VFPU (Vector Unit) @ 2.6GFlops»