Семантическая паутина
- 1 year ago
- 0
- 0

|
|
Пожалуйста, актуализируйте данные
|
Семанти́ческая паути́на (от англ. Semantic Web ) — общедоступная глобальная семантическая сеть , формируемая на базе Всемирной паутины путём стандартизации представления информации в виде, пригодном для машинной обработки.
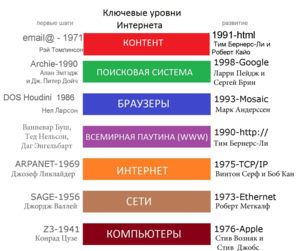
В обычной Всемирной паутине, основанной на HTML -страницах, информация заложена в тексте страниц и предназначена для чтения и понимания человеком. Семантическая паутина состоит из машинно-читаемых элементов — узлов семантической сети , с опорой на онтологии . Благодаря этому программы- клиенты получают возможность непосредственно получать из интернета утверждения вида «предмет — вид взаимосвязи — другой предмет» и вычислять по ним логические заключения . Семантическая паутина работает параллельно с обычной Всемирной паутиной и на её основе, используя протокол HTTP и идентификаторы ресурсов URI .
Название «Семантическая паутина» было впервые введено Тимом Бернерсом-Ли (изобретателем Всемирной паутины) в сентябре 1998 года , и называется им «следующим шагом в развитии Всемирной паутины». Позже в своём блоге он предложил в качестве синонима термин «гигантский глобальный граф» ( англ. giant global graph , GGG , по аналогии с WWW). Концепция семантической паутины была принята и продвигается консорциумом Всемирной паутины .
Семантическая паутина — надстройка над существующей Всемирной паутиной, придуманная для того, чтобы сделать размещаемую в Интернете информацию пригодной для машинной обработки. Доступная в сети информация удобна для прочтения человеком. Семантическая паутина создана для того, чтобы сделать информацию пригодной для автоматического анализа, синтеза выводов и преобразования как самих данных, так и сделанных на их основе заключений в различные представления, полезные на практике.

Машинная обработка возможна благодаря двум характеристикам [ источник не указан 3243 дня ] семантической паутины:
URI
— унифицированный идентификатор ресурса или
адрес
, используемый для указания
ссылок
на какой-либо объект (например,
веб-страницу
,
файл
или ящик
электронной почты
). URI используются для
именования
объектов. Каждый объект глобальной семантической сети имеет уникальный URI. URI однозначно называет некоторый объект. Отдельные URI создают не только для страниц, но и для объектов реального мира (людей, городов, художественных произведений и так далее), и даже для абстрактных понятий (например, «имя», «должность», «цвет»). Благодаря уникальности URI одни и те же предметы можно называть одинаково в разных местах семантической паутины. Используя URI, можно собирать информацию об одном предмете из разных мест. Рекомендуется включать в адрес URI название одного из протоколов Всемирной паутины (
HTTP
или
HTTPS
). То есть адрес URI рекомендуют начинать с «
http://
» или «
https://
»). Такой адрес можно одновременно использовать как адрес
URI
и как адрес веб-страницы (
URL
). На веб-страницах, адреса URL которых совпадают с URI, W3C рекомендует размещать описание предмета. Описание желательно предоставлять в двух форматах
:
Использование семантических сетей и онтологий . Данные во Всемирной паутине, как правило, представлены в виде текста , записанного на естественных языках . Такие тексты предназначены для восприятия человеком, но машина может понять их смысл, используя один из методов обработки естественного языка . Методы выполняют частотный анализ и/или лексический анализ текста.
В качестве формата, удобного для чтения машиной, W3C предлагает использовать язык RDF . Язык RDF позволяет описывать структуру семантической сети в виде графа . Каждому узлу и каждой дуге графа можно назначить отдельный URI. Утверждения, записанные на языке RDF, можно интерпретировать с помощью онтологий. Для создания онтологий рекомендуют использовать языки (англ.) и OWL . Онтологии создаются для получения из данных логических заключений . В основе онтологий лежат математические формализмы, называемые дескрипционными логиками .

Техническую часть Семантической паутины составляет семейство стандартов на языки описания, включающее XML , XML Schema , RDF , RDF Schema , OWL , а также некоторые другие. Располагая их в порядке повышения уровня абстракции, реализуемого тем или иным языком, получаем:
rdfs:Class
, для определения новых типов RDF-данных. Языком поддерживается также отношение наследования типов
rdfs:subClassOf
.
Форматы описания метаданных в Семантической паутине предполагают проведение логического вывода на этих метаданных, и разрабатывались с оглядкой на существующие математические формализмы в этой области. Формализм, лежащий в основе формата, даёт возможность делать заключения о свойствах программ, обрабатывающих данные в этом формате.
Особенно сильно это относится к языку OWL . Базовым формализмом для него являются дескрипционные логики , а сам язык разбит на три вложенных подмножества (в порядке вложенности): OWL Lite, OWL DL и OWL Full . Доказано , что логический вывод на метаданных с выразительностью OWL Lite выполняется за полиномиальное время (другими словами, задача вывода принадлежит к классу P ). OWL DL описывает максимальное обладающее разрешимостью подмножество дескрипционных логик, но некоторые запросы по таким данным могут требовать экспоненциального времени выполнения . OWL Full реализует все существующие конструкторы дескрипционных логик за счёт отказа от обязательной разрешимости запросов.
Простая структура предикатов языка RDF , в свою очередь, позволяет использовать при его обработке опыт из теорий , логики предикатов и т. д.
В 2006 году журнал « IEEE Intelligent Systems» опубликовал новую статью Тима Бернерса-Ли «Semantic Web Revisited» («Семантическая паутина: пересмотр») , в которой автор называет описанный подход к организации информации в вебе «простой идеей, до сих пор в большой степени нереализованной», несмотря на все преимущества, предоставляемые Семантической паутиной в случае её внедрения.
На сегодняшний день нет общедоступных средств просмотра и прямого использования информации, предоставляемой сайтами в Семантическую паутину. Редкие образцы разрозненны, а программы-клиенты не выходят за уровень локальных исследовательских проектов отдельных энтузиастов. [ источник не указан 3462 дня ]
Комментаторы указывают на различные причины, которые препятствуют активному развитию Семантической паутины, начиная с человеческого фактора (люди склонны избегать работы по поддержке документов с метаданными, открытыми остаются проблемы истинности метаданных, и т. д.), и заканчивая косвенным указанием Аристотеля на отсутствие очевидного способа деления мира на различимые концепты. Это ставит под сомнение возможность существования , критической для Семантической паутины. Аристотель в « Топике » использует понятие differentia specifica , или наличие у понятий различимого качества , как основу для группировки понятий в классы. Философ уверен в наличии бесконечного числа понятий, из чего следует бесконечность числа классов, в которые их можно объединить. Для выделения такого количества классов необходимо бесконечно много различимых качеств, наличие которых Аристотель подвергает сомнению.
Необходимость описания метаданных так или иначе приводит к дублированию информации. Каждый документ должен быть создан в двух экземплярах: размеченным для чтения людьми, а также в машинно-ориентированном формате. Этот недостаток Семантической паутины был главным толчком к созданию так называемых микроформатов и языка RDFа . Последний является вариантом языка RDF и отличается от него тем, что не определяет собственного синтаксиса, а предназначен для внедрения в XML-атрибуты XHTML -страниц. Кроме того, в самих стандартах HTML появляются семантические теги .
Одним из первых серьёзных и популярных проектов, основанных на принципах Семантической паутины, стал проект « Дублинское ядро » ( англ. Dublin Core ), реализуемый инициативной организацией Dublin Core Metadata Initiative (DCMI). Это открытый проект, цель которого — разработать стандарты метаданных, которые были бы независимы от платформ и подходили бы для широкого спектра задач. Конкретнее, DCMI занимается разработкой словарей метаданных общего назначения, стандартизирующих описания ресурсов в формате RDF.
Версии 0.90 и 1.0 формата RSS основаны на RDF. Информация в нём представляется как и в RDF, тройками субъект-отношение-объект . Необходимо отметить, что несмотря на то, что ему присущи многие недостатки Семантической паутины (например, дублирование информации), этот простейший формат быстро стал чрезвычайно популярным за счёт узкой категоризации подмножества используемых метаданных. Отличие RSS от RDF состоит в том, что субъектом тройки всегда является сайт-источник RSS-файла, а в качестве отношений используются самые очевидные свойства документов, имеющие отношение к часто обновляющимся источникам информации: дата написания, автор, постоянная ссылка, и т. д. Другими словами, RSS — узкоспециализированное подмножество RDF.
Заметим, что формат RSS версии 2.0, хотя и не является форматом, основанным на RDF, позволяет внедрение произвольного XML-содержимого, находящегося в собственных
пространствах имён
XML. Это позволяет использовать RDF-описания также и в нём (используя пространство имён
rdf
).
Проект « Friend of a Friend » («Друг друга») позволяет описывать отношение знакомства с помощью RDF. Любой его участник может идентифицировать себя уникальным образом с помощью URI (например, mailto-адресом электронной почты , адресом блога, и т. п.), создать свой профиль, используя предопределённые для FOAF отношения на языке RDF, и перечислить идентификаторы людей, которых этот участник знает. Это описание может обрабатываться автоматически; на его основе можно строить сети доверия, анализировать структуру социальных групп, и т. д.
DBpedia — проект, направленный на извлечение структурированной информации из данных, созданных в рамках проекта Wikipedia. DBpedia позволяет пользователям запрашивать информацию, основанную на отношениях и свойствах ресурсов Википедии, в том числе ссылки на соответствующие базы данных. Начат группой добровольцев из Свободного университета Берлина и Лейпцигского университета , в сотрудничестве с , и впервые был опубликован в 2007 году. Проект DBpedia использует Resource Description Framework (RDF) для представления извлеченной информации. По состоянию на апрель 2010, базы данных DBpedia состоят из более чем 1 млрд единиц информации, из которых 257 млн были взяты из английской версии Википедии и 766 млн извлечены из версий на других языках .
|
|
|
|---|---|
| Основы | |
| Подразделы | |
| Приложения | |
| Связанные темы | |
| Стандарты |
|