Речевой звук
- 1 year ago
- 0
- 0

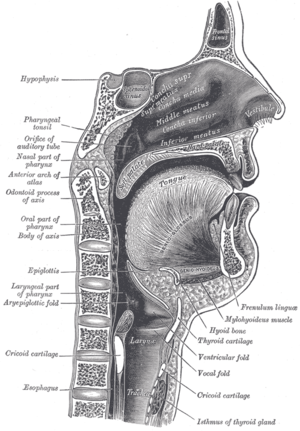
Речево́й ко́рпус ( звуково́й ко́рпус ) — база данных аудиофайлов и транскрипций текстов, разновидность корпуса текстов . В речевые корпуса используются, среди прочего, для создания (которые затем могут использоваться в механизмах распознавания речи ). В лингвистике речевые корпуса используются для исследований фонетики , диалектологии , конверсационного анализа и в других областях.
Существует два типа речевых корпусов:
1.Базы начитанных текстов, в том числе:
2.Базы аудиозаписей спонтанной речи — в том числе:
Особый вид речевых корпусов — это , которые содержат речь с иностранным акцентом .
| Общие определения | |
|---|---|
| Анализ текста | |
| Реферирование |
|
| Машинный перевод | |
|
Идентификация
и сбор данных |
|
| Тематическая модель | |