Мешок с костями
- 1 year ago
- 0
- 0

Мешок слов ( англ. bag-of-words ) — упрощенное представление текста, которое используется в обработке естественных языков и информационном поиске . В этой модели текст (одно предложение или весь документ) представляется в виде мешка (мультимножества) его слов без какого-либо учета грамматики и порядка слов, но с сохранением информации об их количестве.
Мешок слов обычно используется в методах классификации документов , где частотность вхождения слова используется как признак для обучения классификатора .
Одно из первых упоминаний «мешка слов» в лингвистическом контексте встречается в статье 1954 года Зеллига Харриса Distributional Structure .
Модель «мешок слов» также используется в задачах компьютерного зрения .
Далее приводится пример моделирования текста с помощью мешка слов на языке программирования JavaScript .
Возьмем два простых документа:
(1) Иван любит смотреть фильмы. Мария тоже любит фильмы.
(2) Иван также любит смотреть футбольные матчи.
Для каждого документа строится список его слов:
«Иван», «любит», «смотреть», «фильмы», «Мария», «тоже», «любит», «фильмы»
«Иван», «также», «любит», «смотреть», «футбольные», «матчи»
Из этих списков можно создать объекты, представляющие мешок слов:
BoW1 = { "Иван" : 1, "любит" : 2, "смотреть" : 1, "фильмы" : 2, "Мария" : 1, "тоже" : 1 };
BoW2 = { "Иван" : 1, "также" : 1, "любит" : 1, "смотреть" : 1, "футбольные" : 1, "матчи" : 1 };
Ключами объекта являются слова из списка, а значения — это число появлений этого слова в списке, то есть исходном текстовом документе. Каждый ключ встречается в объекте лишь однажды, порядок ключей не имеет значения.
Если объединить эти два документа в третий документ
(3) Иван любит смотреть фильмы. Мария тоже любит фильмы. Иван также любит смотреть футбольные матчи.
то его представление в виде мешка слова имеет вид
BoW3 = { "Иван" : 2, "любит" : 3, "смотреть" : 2, "фильмы" : 2, "Мария" : 1, "тоже" : 1, "также" : 1, "футбольные" : 1, "матчи" : 1 };
Как видно, в алгебре мешков «объединение» двух документов является дизъюнктным объединением , суммирующим кратности элементов:
На практике модель мешка слов в основном используется для формирования признаков . На основе мешка слова можно вычислять различные меры, характеризующие исходный текст. Чаще всего по мешку слов находят абсолютную частотность слов, то есть количество появлений каждого слова во всем тексте. В приведенном выше примере можно построить следующие два списка, или вектора, абсолютных частотностей слов (BoW1 и BoW2 упорядочены как BoW3):
(1) [1, 2, 1, 2, 1, 1, 0, 0, 0]
(2) [1, 1, 1, 0, 0, 0, 1, 1, 1]
Каждое число списка соответствует количеству появлений соответствующего слова в тексте, также это можно назвать гистограммой. Например, в первом списке первые два числа — это «1, 2»: первое число соответствует слову «Иван», которое появляется в первом документе только 1 раз, второе число соответствует слову «любит», которое появляется в 2 раза.
Этот список не сохраняет порядок слов оригинального предложения, что является основной особенностью модели «мешка слов».
Мешок слов имеет несколько успешных приложений, например фильтрация электронной почты .
Однако, частотность слов не всегда являются наилучшей характеристикой текста. Распространенные слова, такие как «и», «в», «но», почти всегда имеют наивысшую частотность в тексте. Таким образом, высокая частотность появления слова не обязательно означает, что это слово является более важным по смыслу. Популярным способом решения этой проблемы является мера TF-IDF , которая нормализует частотность слова в документе делением на частотность этого слова во всей коллекции документов. Кроме того, для задач классификации были разработаны альтернативы определения частотностей с помощью обучения с учителем , которые учитывают тип документа . Наконец, в некоторых задачах вместо частотностей слов используют бинарные веса (наличие/отсутствие, 1/0), например, такая опция есть в системе машинного обучения Weka .
Модель «мешок слов» — это неупорядоченное представление документа, в котором важно только количество слов. Например, в приведенном выше примере «Иван любит смотреть фильмы. Мария тоже любит фильмы», мешок слов не содержит информации о том, что глагол «любит» всегда следует после имени человека. Эту пространственную информацию может сохранить модель N-грамм . Применяя к приведенному примеру модель биграмм , получим следующее представление текста:
[
"Иван любит",
"любит смотреть",
"смотреть фильмы",
"Мария любит",
"любит фильмы",
"фильмы тоже",
]
Мешок слов можно рассматривать как частный случай модели n -грамм при n = 1 . Для n > 1 модель называется w-shingling (где w, также как n , обозначает количество сгруппированных слов). Подробнее см. в статье о языковой модели .
from keras.preprocessing.text import Tokenizer
sentence = ["Иван любит смотреть фильмы. Мария тоже любит фильмы."]
def print_bow(sentence: str) -> None:
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentence)
sequences = tokenizer.texts_to_sequences(sentence)
word_index = tokenizer.word_index
bow = {}
for key in word_index:
bow[key] = sequences[0].count(word_index[key])
print(f"Мешок слов предложения 1:\n{bow}")
print(f'Нашли {len(word_index)} уникальных токенов.')
print_bow(sentence)
Распространенной альтернативой представлению мешка слов словарем является метод , в котором слова с помощью хэш-функции преобразуются в индексы массива . Таким образом, не требуется память, чтобы хранить ключи словаря. Коллизии хеш-функции разрешаются освобождением памяти, что позволяет увеличить количество хэш-корзин. Практически, хэширование упрощает реализацию мешка слов и улучшает масштабируемость.
В байесовской фильтрации спама сообщения электронной почты моделируется неупорядоченным набором слов, выбранных из одного из двух распределений вероятностей: спама и обычных электронных писем (ham). Построим мешок слов для каждого из типов писем, одна будет содержать слова из всех спам-сообщений, а другая — слова из обычных сообщений. Мешок слов для спама будет содержать слова, связанные со спамом, такие как «акции», «виагра» и «покупать», значительно чаще, а мешок для ham будет содержать больше слов, связанных с друзьями или работой.
Классифицируя сообщение электронной почты, байесовский фильтр спама предполагает, что сообщение состоит из набора слов, случайным образом выбранных из одного из двух мешков, и использует байесовскую вероятность , чтобы определить в каком мешке оно находится.
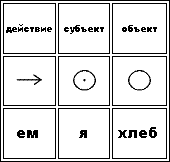
И этот запас комбинаций элементов становится фактором того, какие решения выбираются затем... потому что язык - это не просто мешок слов, а инструмент с особыми свойствами, которые были созданы при его использовании
{{
cite conference
}}
:
В
|url=
пропущен заголовок (
справка
)
| Общие определения | |
|---|---|
| Анализ текста | |
| Реферирование |
|
| Машинный перевод | |
|
Идентификация
и сбор данных |
|
| Тематическая модель | |