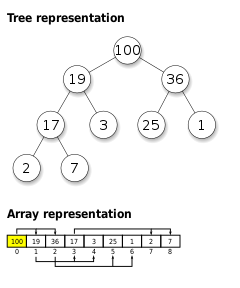
Куча (структура данных)
- 1 year ago
- 0
- 0


R-дерево ( англ. R-trees ) — древовидная структура данных ( дерево ), предложенная в 1984 году . Она подобна B-дереву , но используется для организации доступа к пространственным данным, то есть для индексации многомерной информации , такой, например, как географические данные с двумерными координатами ( широтой и долготой ). Типичным с использованием R-деревьев мог бы быть такой: «Найти все музеи в пределах 2 километров от моего текущего местоположения».
Эта структура данных разбивает многомерное пространство на множество иерархически вложенных и, возможно, пересекающихся, прямоугольников (для двумерного пространства). В случае трехмерного или многомерного пространства это будут прямоугольные параллелепипеды ( кубоиды ) или .
Алгоритмы вставки и удаления используют эти ограничивающие прямоугольники для обеспечения того, чтобы «близкорасположенные» объекты были помещены в одну листовую вершину. В частности, новый объект попадёт в ту листовую вершину, для которой потребуется наименьшее расширение её ограничивающего прямоугольника. Каждый элемент листовой вершины хранит два поля данных: способ идентификации данных, описывающих объект, (либо сами эти данные) и ограничивающий прямоугольник этого объекта.
Аналогично, алгоритмы (например, пересечение, включение, окрестности) используют ограничивающие прямоугольники для принятия решения о необходимости поиска в дочерней вершине. Таким образом, большинство вершин никогда не затрагиваются в ходе поиска. Как и в случае с B-деревьями, это свойство R-деревьев обусловливает их применимость для баз данных , где вершины могут выгружаться на диск по мере необходимости.
Для расщепления переполненных вершин могут применяться различные алгоритмы, что порождает деление R-деревьев на подтипы: квадратичные и линейные.
Изначально R-деревья не гарантировали хороших характеристик для наихудшего случая , хотя хорошо работали на реальных данных. Однако в 2004-м году был опубликован новый алгоритм , определяющий приоритетные R-деревья . Утверждается, что этот алгоритм эффективен , как и наиболее эффективные современные методы, и в то же время является оптимальным для наихудшего случая .
Каждая вершина R-дерева имеет переменное количество элементов (не более некоторого заранее заданного максимума). Каждый элемент нелистовой вершины хранит два поля данных: способ идентификации дочерней вершины и ограничивающий прямоугольник (кубоид), охватывающий все элементы этой дочерней вершины. Все хранимые кортежи хранятся на одном уровне глубины, таким образом, дерево идеально сбалансировано. При проектировании R-дерева нужно задать некоторые константы:
Для корректной работы алгоритмов необходимо выполнение условия MinEntries <= MaxEntries / 2. В корневой вершине может быть от 2 до MaxEntries потомков. Часто выбирают MinEntries = 2, тогда для корня выполняются те же условия, что и для остальных вершин. Также иногда разумно выделять отдельные константы для количества точек в листовых вершинах, так как их часто можно делать больше.
Построение R-дерева происходит, как правило, с помощью многократного вызова операции вставки элемента в дерево. Идея вставки похожа на вставку в B-дерево : если добавление элемента в очередную вершину приводит к переполнению, то вершина разделяется. Приведём ниже классический алгоритм вставки, описанный .
Для разделения вершин могут использоваться разные алгоритмы, это один из них. Он имеет всего линейную сложность и просто реализуется, правда выдаёт не самое оптимальное разделение. Однако практика показывает, что такой сложности обычно достаточно.
Иногда вместо R-дерева используют так называемое (c означает clustered ). Основная идея в том, что для разделения вершин или точек используются алгоритмы кластеризации , такие как k-means . Сложность k-means тоже линейная, но он в большинстве случаев даёт лучший результат, чем линейный алгоритм разделения Гуттмана, в отличие от которого он не только минимизирует суммарную площадь огибающих параллелепипедов, но и расстояние между ними и площадь перекрытия. Для кластеризации точек используется выбранная метрика исходного пространства, для кластеризации вершин можно использовать расстояние между центрами их огибающих параллелепипедов или максимальное расстояние между ними.
Алгоритмы кластеризации не учитывают то, что число потомков вершины ограничено сверху и снизу константами алгоритма. Если кластерный сплит выдаёт неприемлемый результат, можно использовать для этого набора классический алгоритм, так как на практике такое происходит не часто.
Интересна идея использовать кластеризацию на несколько кластеров, где несколько может быть больше двух. Однако надо учитывать, что это накладывает определённые ограничения на параметры структуры р-дерева.
Отметим, что помимо cR-дерева существует его вариация clR-дерево, основанное на методе кластеризации, где в качестве центра использован итерационный алгоритм решения «задачи размещения». Алгоритм имеет квадратичную вычислительную сложность, но обеспечивает построение более компактных огибающих параллелепипедов в записях вершин структуры.
Поиск в дереве довольно тривиален, надо лишь учитывать тот факт, что каждая точка пространства может быть покрыта несколькими вершинами.
Данный алгоритм удаляет некоторую запись E из R-дерева. Алгоритм состоит из следующих шагов:
Функция FindLeaf
Пусть T - корень дерева, в E - искомая запись.
Функция CondenseTree
Пусть из листа L удалили запись E. Тогда, необходимо устранить тот узел, у которого осталось мало записей (меньше чем MinEntries) и переместить его записи. При продвижении вверх по дереву, если необходимо - совершать удаление записей (по тому же самому критерию). По пути к корню перерасчитывать прямоугольники, делая их как можно меньше. Ниже описан алгоритм. Данную функцию можно реализовать и с помощью рекурсии.
| Двоичные деревья | |
|---|---|
| B-деревья | |
| Префиксные деревья | |
|
Двоичное разбиение
пространства |
|
| Недвоичные деревья | |
| Разбиение пространства | |
| Другие деревья | |
| Алгоритмы | |