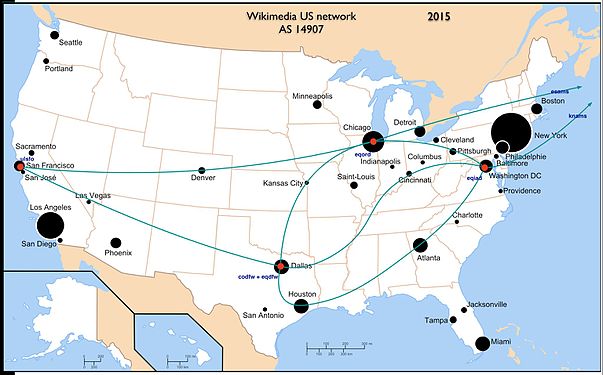
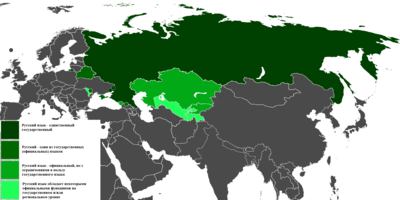
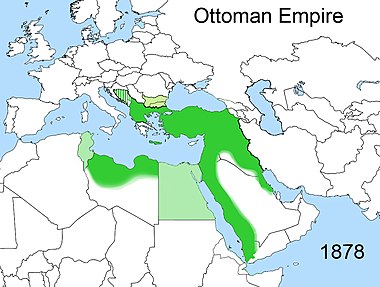
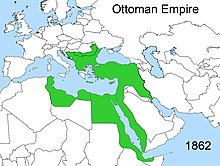
Interested Article - 0 0 isla 2020-10-11 1 0 0 isla 2020-10-11 1 Tags: Патрулирование 1 year ago 0 0 0 Википедия 1 year ago 0 0 0 Свободный контент 1 year ago 0 0 0