Текстовые данные
- 1 year ago
- 0
- 0

Те́кстовые
да́нные
(также
те́кстовый форма́т
) — представление информации
строкового типа
(то есть, последовательности
печатных символов
) в
вычислительной системе
. В
MIME
закодированным
таким образом данным соответствует тип
text/plain
.
Часто текстовые данные понимаются в более узком смысле — как текст на каких-либо языках ( формальных или естественных ), который может быть прочитан и понят человеком.
Текстовому формату противопоставляются « двоичные данные », информация в которых закодирована произвольным образом, не рассчитанным на восприятие человеком.
Для большей части компьютерного оборудования и программ неважно, являются ли данные текстовыми. Однако многие сетевые протоколы рассчитаны на работу только с текстовыми данными и не могут обрабатывать произвольную последовательность байтов. Также, некоторые программы обрабатывают текстовые и двоичные данные по-разному, а некоторые предназначены для обработки именно текстовых данных. Программы для создания и редактирования текстовых данных называются текстовыми редакторами .
Текстовыми данными как правило называются последовательности из подмножества знаков, включающего только печатные знаки ( буквы , цифры , знаки препинания ) и некоторые управляющие знаки ( пробелы , табуляции , переводы строки). Существуют методы (например, UUENCODE или Base64 ), позволяющие закодировать в текстовом формате произвольные данные любого формата, что часто используется для кодирования бинарных данных.
Требование к возможности понимания содержимого человеком вносит дополнительную избыточность в представление данных. К примеру, число 123, для кодирования которого достаточно одного 8-битного байта, в текстовом виде кодируется несколькими цифровыми символами — так, в десятичной системе счисления для этого требуется три знака («123»), в двоичной — семь знаков («1111011»), в шестнадцатеричной — два («7B»).
Текстовый формат не позволяет использовать команды форматирования текста, управлять атрибутами шрифтов, размечать содержимое .
Текстовые данные могут разделяться на строки. В некоторых операционных системах (в основном семейства UNIX ) разбиение на строки кодируется одним управляющим знаком с кодом 10 в таблице ASCII (наименование — Line Feed, LF), на других (к примеру, в MS-DOS и Microsoft Windows ) — парой управляющих знаков с кодами 13 и 10 (Carriage Return и Line Feed, CR/LF). В Mac OS (но не Mac OS X ) разбиение кодируется одним знаком с кодом 13.
Такое разбиение управляющим знаком или знаками продиктовано тем, как работали пишущие машинки , через которые осуществлялся ввод в некоторых первых компьютерах — позиция ввода там указывалась положением валика с бумагой, и для поворота валика и перехода к следующей строке требовалось нажатие одной или двух клавиш или рычажков.
Также, знаки разбиения строк использовались для управления механическими принтерами (в качестве которых могли выступать те же печатные машинки, используемые и для ввода) — знак LF вызывал прокрутку рулона с бумагой, а знак CR вызывал возврат печатной каретки (там, где они были) в начало строки. Отсюда и название знаков — англ. Line Feed (перевод строки) и англ. Carriage Return (возврат каретки).
На некоторых платформах разбиение на строки делалось иначе — текст представлялся в виде последовательности записей фиксированной длины, для чего более короткие строки дополнялись нужным количеством пробелов. Это соответствовало представлению данных на перфокартах , которые служили средством ввода и даже хранения данных, имевших фиксированную ширину (например, 80 позиций - колонок).

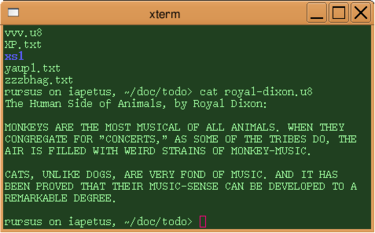
cat
в окне
xterm
Основная цель применения текстовых данных — «общий знаменатель», независимость от отдельных программ, требующих собственного кодирования или форматирования и несовместимых с другими программами.
Текстовые файлы
(файлы в текстовом формате) могут быть открыты, прочитаны и отредактированы в любых текстовых редакторах, таких как
MS-DOS Editor
(
DOS
),
Блокнот
(
Windows
),
ed
,
vi
и
vim
(
UNIX
,
Linux
),
,
TextEdit
(
Mac OS X
) и т. п. Другие программы также как правило умеют читать и импортировать текстовые данные. Просмотреть текстовые файлы можно также встроенными командами (
type
в DOS и Windows) и
утилитами
(
cat
в Unix).
Текстовый формат часто используется для представления данных, которые сами не являются чисто текстовыми. В этом случае другие форматы данных «надстраиваются» над простым текстом, для чего их управляющие конструкции выражаются посредством печатных слов и знаков препинания. Это обеспечивает удобство работы с данными на двух уровнях — например, данные HTML и XML можно просматривать и редактировать с показом форматирования в режиме WYSIWYG , а можно их открыть в обычном текстовом редакторе и иметь доступ ко всем тонкостям языка разметки. При хранении данных в «двоичном» виде (как это делается, например, в Microsoft Word ранних версий) с ними нередко нельзя работать в других программах (из-за недоступности информации о структуре формата) или даже в разных версиях одной и той же программы.
В большинстве языков программирования предполагается использование текстового формата для исходного кода программ. Помимо прочего, это позволяет применять к исходным кодам разнообразные утилиты для преобразований, оформления, поиска, статистики, анализа и т. п.
В файлах конфигурации многих программ применяется текстовый формат, даже если там представлены числа и двоичные переключатели (да/нет). Это несколько усложняет программы из-за необходимости преобразования текстовых данных во внутренний формат и обратно, но появляется возможность править конфигурацию вручную, без использования средств настройки самой программы.
Затруднительным является указание на какую-то определенную часть текста, хранящегося в формате текстовых данных. В качестве указателей могут использоваться номера строк или номера символов .
Термин открытый текст ( англ. plaintext ; выглядит очень похоже на термин англ. plain text , используемый для обозначения текстовых данных) широко применяется в криптографии и означает любые незашифрованные данные, в том числе и нетекстовые. Термин чистый текст ( англ. cleartext ) также применяется в криптографии и означает незашифрованные данные, к тому же понятные человеку и незащищённые от «подслушивания» при передаче.
|
|
Для улучшения этой статьи
желательно
:
|
|
|
В статье
не хватает
ссылок на источники
(см.
рекомендации по поиску
).
|
| Неинтерпретируемые | |
|---|---|
| Числовые | |
| Ссылочные | |
| Композитные | |
| Абстрактные |
|
| Другие | |
| Связанные темы | |













