Жизнь американского пожарного
- 1 year ago
- 0
- 0

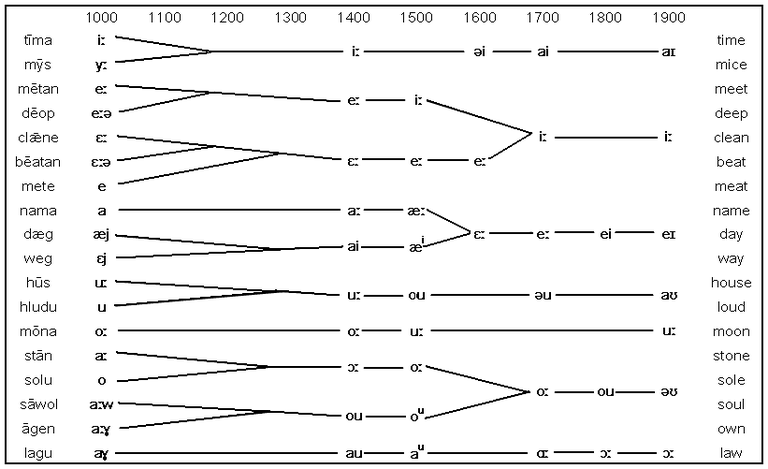
Национальный корпус американского английского ( англ. American National Corpus , ANC) — корпус текстов американского английского языка , содержащий 22 миллиона слов из письменных и устных источников, вышедших с 1990 года. ANC включает в себя ряд текстов из новых источников, включая такие как электронная почта , твиты и тексты с веб-страниц , которые не включены в более ранние корпуса английского языка, такие как Британский национальный корпус . В нём осуществлён частеречный конкорданс с лемматизацией , включая имена собственные, и .
ANC доступен для участников . Ресурс (подкорпус), содержащий 15 миллионов слов корпуса, называется Open American National Corpus (OANC) и находится в открытом доступе с сайта ANC .
Тексты Корпуса формируются в соответствии с требованиями технического комитета «Linguistic Annotation Framework». Благодаря находящемуся в открытом доступе инструменту трансдукции ANC2Go, фрагменты корпуса и аннотации, созданные пользователями, представлены в нескольких форматах, таких как CoNLL IOB — XML -формат, соответствующий стандарту кодирования (который можно использовать в поисковой системе XAIRA Британского национального корпуса ), -совместимый формат, и форматы, подходящие для широкого спектра программ конкорданса. Также доступны плагины для импорта аннотаций в систему обработки естественного языка GATE .
ANC отличается от других корпусов английского языка широкой аннотированностью, включая различные частеречевые разметки (Penn tags, CLAWS5 и CLAWS7 tags), и аннотации для нескольких типов именованных объектов. Дополнительные аннотации добавляются ко всему корпусу или его частям по мере поступления, нередко как результаты реализации других проектов. В отличие от онлайновых корпусов текстов, которые из-за ограничений, обусловленных авторским правом , предоставляют доступ только к отдельным предложениям, весь корпус текстов ANC доступен для проведения исследований, включая разработку статистических языковых моделей и полнотекстовых лингвистических аннотаций.
Аннотации ANC создаются автоматически и не проверяются. Раздел OANC из 500 000 слов, известный как (MASC) аннотируется для примерно 20 различных видов лингвистических аннотаций, которые проверяются или создаются вручную. К ним относятся синтаксическая аннотация Penn Treebank, семантические сети WordNet и , и другие. Подобно OANC, MASC находится в свободном доступе для любого использования и может быть загружен с сайта ANC или Консорциума лингвистических данных. Он также распространяется с пакетом библиотек и программ для символьной и статистической обработки естественного языка Natural Language Toolkit .
ANC и его подкорпуса отличаются от аналогичных текстовых корпусов главным образом характеристиками лингвистических аннотаций и включением текстов современных жанров, которые не содержатся в таких ресурсах, как, например, Британский национальный корпус . Кроме того, поскольку первоначальное целевое назначение ANC — разработка статистических моделей языка, пользователям ANC доступны полные данные и все аннотации, в отличие от Корпуса современного американского английского языка (COCA), чьи тексты доступны только выборочно через веб-браузер.
Рост баз текстов OANC и MASC продолжается благодаря пополнению данных и аннотаций, производимых сообществами компьютерной лингвистики и корпусной лингвистики .
| Англоязычные корпусы | |
|---|---|
| Русскоязычные корпусы | |
| Корпусы на других языках | |
| Организации | |